
隨機逼近
正文
在有隨機誤差干擾的情況下,用逐步逼近的方式估計某一特定值的數理統計方法。1951年,H.羅賓斯和S.門羅首先研究了此問題的一種形式:設因素x的值可由試驗者控制,x的“回響”的指標值為Y,當取x之值x進行試驗時,回響Y可表為Y=h(x)+ε,式中h(x)為一未知函式,ε為隨機誤差。設目標值為A,要找這樣的x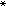 ,使h(x)=A。分別以Y-A和h(x)-A代替Y和h(x)。不妨設A=0,問題就在於找方程h(x)=0的根x。例如若x為施藥量,Y為衡量藥物反應的某種生理指標,則問題在於找出施藥量x,以使該生理指標控制於適當的值A。
,使h(x)=A。分別以Y-A和h(x)-A代替Y和h(x)。不妨設A=0,問題就在於找方程h(x)=0的根x。例如若x為施藥量,Y為衡量藥物反應的某種生理指標,則問題在於找出施藥量x,以使該生理指標控制於適當的值A。 若隨機誤差 ε=0,且h(x)為已知函式,則數值分析中提供了許多近似解法。例如可用牛頓疊代法求解:從一適當選擇的初始值x0齣發,用疊代公式xi+1=xj+αjyj,式中yj=h(xj);
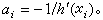 但當h(x)未知且有隨機誤差干擾時,αj和yj無法算出。羅賓斯等將上述算法稍作修改,引進疊代程式xi+1=xj-bjYj,式中Yj為當x=xj時Y的回響值,bj為適當選定的常數。假定 h(x)為x的遞增函式且增長速度不快於線性,而各次量測相互獨立,則理論研究證明了,只要取bj>0滿足
但當h(x)未知且有隨機誤差干擾時,αj和yj無法算出。羅賓斯等將上述算法稍作修改,引進疊代程式xi+1=xj-bjYj,式中Yj為當x=xj時Y的回響值,bj為適當選定的常數。假定 h(x)為x的遞增函式且增長速度不快於線性,而各次量測相互獨立,則理論研究證明了,只要取bj>0滿足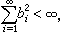
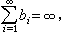 則由此算法決定的序列{xj}以機率1收斂到x(見機率論中的收斂)。上述算法叫羅賓斯-門羅程序,這是隨機逼近的開創性的工作。
則由此算法決定的序列{xj}以機率1收斂到x(見機率論中的收斂)。上述算法叫羅賓斯-門羅程序,這是隨機逼近的開創性的工作。 在有的問題中,要找的不是h(x)的零點,而是其極值點慜,它滿足h′(慜)=0。但試驗觀測到的不是h′(x)+ε而只是h(x)+ε,故上述算法不能用於逼近慜。J.基弗和J.沃爾弗維茨依據用差商逼近h′(x)的想法在 1952年提出了一個算法(基弗-沃爾弗維茨程式)以解決估計慜的問題。
1951年以來,隨機逼近的研究已取得了很大的進展。在理論上,討論了量測誤差不獨立的情形和帶約束條件的情形,以及h(x)具有更一般性質的情形。也考慮了時間連續時的算法和修正係數bj的選擇,並對算法的漸近性質作了深入的研究。在方法上,也從純機率發展到結合使用微分方程等工具。隨機逼近在最佳化問題、適應控制、調節及跟蹤系統等方面都有套用。
參考書目
M.T.Wasan,Stochastic ApproxiMation,cambridge Univ. Press,cambridge,1969.
H.Robbins and S.Monro,A Stochastic Approximation Method,Ann. Math. Statist.,Vol.22(1),1951.
