 朱邦復
朱邦復概述
 漢字基因
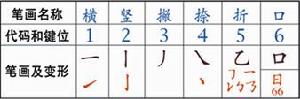
漢字基因字碼用於漢字的編碼使用倉頡檢字法可根據字形得出一個字的字碼
字序用於漢字的檢索、排序以倉頡碼為內碼。由於倉頡碼具有固定序列,可用作排序
字形即漢字的形體,可被人類視覺感受字形產生器可根據倉頡碼產生字形
字辨感受漢字的形體而得知其含義的抽象、動態過程倉頡系統可根據掃描的文字點陣圖,搜尋其中的倉頡字根,轉換成相應的倉頡碼,字音即漢字的讀音,人類可發出和感受者倉頡系統可根據倉頡碼推斷大致讀音,但因古今音變劇烈,須做較多例外處理
字義即漢字可供人認知的意義對漢字進行“概念分類”和定義,可供電腦的“理解系統”根據倉頡碼(內碼)理解字義,再加以組合,即可令電腦理解人類的自然語言與思想,甚至可和人類溝通。
碼序形辨的分析方法,即是早期朱邦復開發倉頡輸入法的過程[2]。而關於字義的分析方法,朱邦復認為,透過人類感官,對事物作“絕對分類”(二分法),求出最小的概念象徵因子,即是字義基因;由於漢字是中文的最小組成因子,因此字義基因也是“中文概念基因”。
| 因子 | 功能 | 技術套用 |
|---|---|---|
| 字碼 | 用於漢字的編碼 | 使用倉頡檢字法可根據字形得出一個字的字碼 |
| 字序 | 用於漢字的檢索、排序 | 以倉頡碼為內碼。由於倉頡碼具有固定序列,可用作排序 |
| 字形 | 即漢字的形體,可被人類視覺感受 | 字形產生器可根據倉頡碼產生字形 |
| 字辨 | 感受漢字的形體而得知其含義的抽象、動態過程 | 倉頡系統可根據掃描的文字點陣圖,搜尋其中的倉頡字根,轉換成相應的倉頡碼 |
| 字音 | 即漢字的讀音,人類可發出和感受者 | 倉頡系統可根據倉頡碼推斷大致讀音,但因古今音變劇烈,須做較多例外處理 |
| 字義 | 即漢字可供人認知的意義 | 對漢字進行“概念分類”和定義,可供電腦的“理解系統”根據倉頡碼(內碼)理解字義,再加以組合,即可令電腦理解人類的自然語言與思想,甚至可和人類溝通。 |
緣起
 朱邦復
朱邦復朱邦復心中的感慨既深且遠,如果中文處理不能具相同的效率,中文遲早將被時代淘汰。再若中文淘汰了,國人全盤接受外國文化的洗禮,那又能算什麽人?千秋萬世的後代子孫,怎知中華文化在絕滅前,曾經綿延過五千年,曾經令黃土高原光輝燦爛?義無反顧地,朱邦複決定獻身於中文的研發工作,默默地耕耘了二十六年。如果可能,朱邦復打算再努力另一個二十六年。畢竟,文化是永無止境的!
同年,朱邦復先回到台灣,在一九七六年先發表了「形意檢字法」。朱邦復作過試驗,如果用在鉛字的排列上,可以增加約五倍的檢字效率。此外,朱邦復發現朱邦復所採用的字根,正是文字的基因,除了字形可供取碼外,如果選取及安排得當,完全可以代表文字所有的機能。尤其是在漢字(中文尚包括其他民族文字)中,百分之九十是形聲字,除了聲符之外,形聲字尚有「假借」的機能,也就是說,字首代表分類,字身可作定義之用。為此,朱邦復對檢字法的要求,是以字義的理解為第一訴求。
一九七八年,時年四十有二,朱邦復有幸接觸到電腦,憤而學習。在一個月內,朱邦復邊學邊做,試著寫作程式,將朱邦復的檢字法與電腦字形結合,並完成了史上第一套軍用通訊系統。當時,蔣緯國將軍特別命名為「倉頡輸入法」。
 漢字基因工程
漢字基因工程同年,朱邦復用這些觀念,設計了一台具有簡單概念的「中文電腦」。由於朱邦復無力生產,便與宏碁公司合作,只提供了字碼輸入及字形輸出的功能,另外由宏碁公司設計了中文作業系統及中文程式語言。
一九七九年九月,朱邦復和宏碁公司共同發表了「天龍中文電腦」,打破了電腦不能使用中文的迷信。
此後,朱邦復繼續從事漢字的研究,達二十年之久。一九八九年八月,朱邦復曾與深圳科技工業園合作,完成「漢字大字型檔」,國家科學院在北京友誼賓館,舉行技術審核及評估。最後在十餘位第一流科學家的審核下,評定為「超過世界水平」。
一九九○年六月,朱邦復發展的「聚珍整合系統」,又在國家科學院的核估下,被評為「超過世界水平」的軟體技術。
一九九一年朱邦復回到台灣,為了抗衡微軟的文化侵略,朱邦復堅決認定微軟視窗應該把文字介面公開,令從事中文軟體的業者,保有一線生機。但微軟悍然拒絕,朱邦復又尋求台灣資訊策進會合作,協助他在視窗3.0上,建立了一個中文系統,其功能遠勝微軟之中文視窗。
微軟立刻拉攏台灣軟體界,合縱連橫。一九九二年,台灣僅有的十餘家軟體公司,不是成為微軟的代銷業者,就是被蠶食鯨吞。最後微軟推出視窗3.1,並取消了資策會版本更新的權利,至此大勢已去,事到如今,台灣的中文軟體界已告全軍覆沒。
朱邦復經過這次慘敗的打擊,便宣佈退隱歸山,專心一致研發漢字的基因工程。但惜曲高和寡,朱邦復曾前後在台灣大學及報章雜誌上發表「概念網路」理念,卻得不到任何迴響。於是朱邦復又轉換策略,將漢字基因理論運用在三維動畫處理上,打算將中華文化的精髓轉化為人人可以接受的動畫產品。
一九九九年二月,朱邦復完成了由編劇到動畫製作的套用系統。又在短短三個月中,以四個工作人員,完成了台灣大學中國文學系所委製的九十分鐘三維動畫,是根據《周禮》製作的「士昏禮」,又是國人突破性的創舉。
同時,朱邦復接到了香港「文化傳信集團有限公司」的邀請,赴港合作,謀求利用最新科技,將文化事業發揚光大。
這次回到台灣發表「漢字基因工程」,正值祖國改革開放成果展現,又恰是微軟大軍臨境,進一步推廣其維納斯計畫之際。此中意義之大,無與倫比,朱邦復今年已六十有三,雖然屢戰屢敗,但仍堅信漢字基因是唯一能夠維護朱邦復中華文化之科技至寶。
理念基礎
 朱邦復
朱邦復微電腦的優點,是執行的結果精確,處理速度快捷,可以節省大量的人力、物力。更兼以能利用軟體設計以增益其功能,對於當今變化無常,而又需求殷切的各種服務業,簡直是大旱之逢甘霖。在商業推波助瀾下,一時大行其道,人們遂誤以為現今的電腦技術,就是最終的資訊解決方桉。
其實,人生從初試啼聲至意識漸明,無非是各種信息之交匯所致。因此,人腦可說是一個自然形成的「信息網路」。大自然進化數十億年,萬事萬物井然有序,其法則自必效率最高。從理論上來說,順遂自然,是最簡單易行的法門。
舉例而言,貓、狗、鳥、魚都各有辨識能力,足證辨識必非高深莫測的「高科技」。再看作圖、計算等能力,不僅貓、狗無此能力,連人類也必須經過長時期的學習、訓練,否則無法勝任。
 朱邦復
朱邦復電腦原名「計算機」,是以數學運算為主要功能。數學的特性是精準明確,從技術來說,這種特性是基於工業發達後,人們因從事物質生產,迫切需要的一種規範。根據這種訴求,我們不難想見,無論微電腦的功能發展到何種地步,要想以之解決人生的各種問題,可以說是緣木求魚。
概念係指概略的念頭,是人將繁複的經驗,用概括簡略的表達方式,以便於與他人溝通者。每一個人都生存在獨一的時空中,在變化無窮的環境刺激下,個人經驗之排列組合機率,完全沒有與他人重複的可能。
因此,最理想的,能解決人類各種問題的方桉,便是用概念設計出一種協助人類思維的工具。由於電子技術的進步,顯然可以在微電腦現有的結構上,重新規劃,設計出一種完全符合人性的擬人電腦。
字易
 漢字基因
漢字基因朱邦復認為,漢字的創造和其字義的由來,主要系“約定俗成”,即“視訊之圖形基因供約定,而由使用者是否易於接受為俗成”。由於人類的感官類似,因此對同樣的視覺圖像能產生類似的感受,此即“約定”。數千年以降,讀書人若能輕易接受、沿用,即為“俗成”。歷史上短暫出現的“死字”,皆系無法“俗成”而放棄者。
他分析了幾個巨大的漢字字集,認為其中約六、七千個常用漢字都是由這樣的“約定俗成”產生。這些字都有類似的組成邏輯,其中絕大多數可拆分為字首和字身,根據字首(常識分類)和字身(細部定義),就可以聯想推理出漢字所表達的“主觀思想概念”。而拆分到最後不能再拆的字形,即為最小的概念單位,也就是“漢字基因”中的“字義”因子。
據此,漢字學習極易,只要學習者掌握了正確的方法,對常識加以聯想,就可以“觸類旁通”而無須“強迫記憶”。而所謂“正確”,即符合“約定俗成之規律”,並且能正確解釋古今用法的字義。要正確地學習漢字,應先習會獨體字(含字首及字身),次學組合字。此兩者總共約七百餘字,卻可組合常用之六、七千字。也就是說,只要熟識了七百個字形,即可掌握常用漢字八成的認知。
但同時他也發現,六萬字的字集中,仍有約九成的漢字無法用漢字基因理論解釋,這些字大部份是名稱用字,是“純粹的形聲字”,這種字的創造與理解無乾,只能視為一個符號,自然也無法用漢字基因理論解釋;其他如“古用字”、“異體字”、“錯訛字”亦同。學習這類“符號”的唯一方法是死記硬背,就像大部分無法拆解的英文單字一樣。
字義解釋
這本書除理論以外,並以常見的字身為綱,用統一的方式解釋許多類似字的字義,例如:
生 指事,會意-甲骨文草木長出,活著,起始,不熟。人稱。與〔日〕組合為〔星〕日所生者,萬物之精也,在夜空為發光的天體。與〔金〕組合為〔鉎〕金所生,鐵衣,鏽也。與〔水〕組合為〔泩〕水生,水漲也。與〔竹〕組合為〔笙〕竹生,管可生音的吹奏樂器。與〔心〕組合為〔性〕人所認知之起始,事物之本質。與〔女〕組合為〔姓〕古代從母稱姓,從男稱氏,家族的代表也。與〔貝〕組合為〔貹〕財生,財富也。與〔生〕組合為〔甡〕生之再生,眾多狀。與〔牛〕組合為〔牲〕牛之生,家中生養的動物。與〔更〕組合為〔甦〕再生,死而復活。與〔文廠〕組合為〔產〕因文明而生、有價值之物品﹔製造,出生。朱邦復認為很多當今所謂的形聲字,其“聲部”亦代表了一定的概念,因此實際上是“形意字”(形聲兼會意字),並據此解釋字義,與主流的文字學解釋不同。
字首和字身
|
|
| 朱邦復要讓電腦思考中文 |

字首:多半為字義的概略分類。
字身:一個漢字去除字首以外的部分,稱之。多半為字義的細部定義。
整體字(獨體字):凡不可分割為字首和字身的漢字,稱之。倉頡輸入法的規則亦稱之“連體字”。
組合字:可分割為字首和字身的漢字,稱之。倉頡輸入法的規則亦稱之“分體字”。
漢字基因理論與字首:朱邦復認為,漢字的創造和其字義的由來,主要系“約定俗成”,即“視訊之圖形基因供約定,而由使用者是否易於接受為俗成”。由於人類的感官類似,因此對同樣的視覺圖像能產生類似的感受,此即“約定”。數千年以降,讀書人若能輕易接受、沿用,即為“俗成”。歷史上短暫出現的“死字”,皆系無法“俗成”而放棄者。
他分析了幾個巨大的漢字字集,認為其中約六、七千個常用漢字都是由這樣的“約定俗成”產生。這些字都有類似的組成邏輯,其中絕大多數可拆分為字首和字身,將字首(常識分類)和字身(細部定義),就可以聯想推理出漢字所表達的“主觀思想概念”。而拆分到最後不能再拆的字形,即為最小的概念單位,也就是“漢字基因”中的“字義”因子。
據此,漢字學習極易,只要學習者掌握了正確的方法,對常識加以聯想,就可以“觸類旁通”而無須“強迫記憶”。而所謂“正確”,即符合“約定俗成之規律”,並且能正確解釋古今用法的字義。
要正確地學習漢字,應先習會獨體字(含字首及字身),次學組合字。此兩者總共約七百餘字,卻可組合常用之六、七千字。也就是說,只要熟識了七百個字形,即可掌握常用漢字八成的認知。
但同時他也發現,六萬字的字集中,仍有約九成的漢字無法用漢字基因理論解釋,這些字大部份是名稱用字,是“純粹的形聲字”,這種字的創造與理解無乾,只能視為一個符號,自然也無法用漢字基因理論解釋。
|
|
| 視窗合作破裂 |

一、同字組合:同字代表同一概念,重複使用時,會因位置不同,產生迥異之感受。
平行排列,以示數量多況:
木+木═林木多成群者。
石+石═砳石多成聲者。
相反排列,以示相反狀:
非-相背之形,鳥翼形。
上下堆砌,以示盛大、成熟之況:
日+日═昌大盛(或指下面曰字)。
火+火═炎火盛。
金字塔排列,以示人之感受狀:
木+木+木═森,多樹之感受,指蔭涼感。
二、字首在上:
原形在上:指事物之正常態,由上而下者。
日+比═昆日下比列而排,眾多,鹹同。
向上生長:指生態或有動力使向上者。
艸+牙═芽草木芽形之苗,事物之初。
包含狀況:有全包、半包、側蓋等,代表限制。
囗+或═國限於土地,有人民、主權、需持戈守域者。
後人誤解,為簡化而更為複雜者:
山+夆═峰象徵實況,山尖在頂,今人以之為“異體字”或無此字。
山+夆═峰象徵分類,山有夆者。
|
|
| 中文編輯公用程式說明 |

三、字首在下:
現實本況:理應在下者。
執+土═墊持土而襯,土在下面。
分+山═岔山分有歧,三分路。
表示正在發生者,如心之當前狀況:
芻+心═急事及於心,迫切也,快速也。
今+心═念此刻之心,想也﹔又讀書出聲也。
承載狀況:代表動態。
走+召═超喚乃因於距離高遠,走而召,行走高過也。
四、字首在左:常態分類,左為類右為別。
分類組合:
心+亡═忙心之亡失,事情繁多沒有空閒。
心+青═情心的本性,人的欲望、感受。
同類組合:
日+月═明日月皆有光,可見可知,引申為下一個可知者。
女+子═好有子有女,完美也,正面有價值的感受、認知,喜歡。
五、字首在右:如力刀反斤鳥欠殳邑等(除鳥外,皆與行為有關)
且+力═助且出力,輔佐,幫忙。
車+斤═斬車被截,砍斷。
字首的切分規律:
字首和字身的切分方法大略如下:
指示字的主幹為字首,附加部分為字身。如“本”,“木”為字首,“一”為字身。
形聲字的形符為字首,聲符為字身。如“楣”,“木”為字首,“眉”為字身。
會意字中概念分類的部分為字首,細部定義的部分為字身。如“信”,“人”為字首,“言”為字身。
倉頡輸入法的字首和字身:《漢字基因字典》和《字易》在探討字義時,用的是“字義”因子,而倉頡輸入法取出的是“字碼”因子,二者不完全相同。倉頡輸入法對漢字的切割規則是依據漢字基因理論設計,因此對大部分的漢字而言,倉頡輸入法取出的字首與“字義”分析的字首相同。但為了視覺辨識的方便,以及為了提高編碼的效率和解析度,倉頡輸入法對某些字的取碼規定便與字義分析的結果不同。
其中最大的特點是,倉頡輸入法規定取字的最左、最上或最外的部分為字首。部首在右的字,如【頭】,依漢字基因理論,字首為〔頁〕;但倉頡輸入法取出的字首是〔豆〕。
有些字甚至連切割部分都有根本的不同,如【條】,依字義分析,字首為〔木〕,字身為〔攸〕;但倉頡輸入法取出的字首是〔亻〕,字身為[丨夊木]。
有些字在字義上是組合字,但字形上是連體字,如【舌】,依字義分析,字首為〔乾〕,字身為〔口〕;但倉頡輸入法視為無法分割的連體字[舌]。
有些字在字義上是獨體字,但字形上是組合字,如【兆】,依字義分析,為無法分割的獨體字;但倉頡輸入法可分出字首“中一”和字身“山人”。
漢字基因字典
 漢字基因字典
漢字基因字典他認為,漢字是世界獨有的概念文字,其中蘊涵的微言大義,是古人思維的結晶,數千年來行文乃至思考的根本,因此古文能夠言簡意賅,含意深遠。但由於白話文運動鼓吹以“詞”取代“字”,現在的辭典僅解釋詞義而不談及該詞義的由來;而現代的字典則多以詞為基準,將漢字分成一條一條解釋,違反漢字本質,令漢字看似費解且難以學習。漢字“本義”被人忘卻,現代人中文水平低落,正因不能辨明字義所致。為了揭示字義,消除現今辭典的弊病,故此編寫這部字典。
這部字典僅取漢字的“本義”,參照《康熙字典》和《形音義綜合大字典》,並根據漢字基因理論,把組合字分為字首、字身解釋,字首為常識分類,字身為細部定義。從字首字身的“體用”關係聯想來說明字義。再按“體用因果”組合為詞,均以漢字的本義解釋。如此每個字、詞不再是一條一條獨立的解釋,而是由一個簡短的概念延伸、演化而來,有源有本。
這樣的編寫方式是因每個漢字都表示一概念,詞則是把概念加以組合聯想而來。以字首字身解釋漢字本義,能加深了解其中的概念,闡明漢字的微言大義。也說明只需明了字首字身和組合規律,就能掌握漢字理解的要訣,證明漢字的合理易學,是簡化字和其他文字所比不上的。
漢字排序採用第五代倉頡碼,是漢字基因中的“字序”因子。
這部字典由朱邦復獨力編寫,尚未出版。他把初稿放在其網站作參考用,收六千多字。
倉頡系統
 倉頡系統
倉頡系統倉頡系統方案:朱邦復先生在發展倉頡輸入法時,原意是要發展“中文檢字法”,使漢字具有“序位觀念”,使中文能像拼音文字一般,用少數字母找到所有漢字。倉頡輸入法的26個字碼“日月金木水火土…止卜”,其實正如同拉丁字母的26個字母“ABCDE…XYZ”、日本語的五十音序等,是有序的排列,可用於檢索漢字,是以稱作“倉頡字母”。
事後他進一步擴充系統,提出漢字基因理論。由於字根都依漢字形聲字特性分析得來,故若在電腦上運用這套方法,將有以下六大用途:
- 1.字碼:倉頡碼可用於漢字之輸入,即倉頡輸入法。
- 2.字序:倉頡碼有一定的排序規律,漢字也可如同英語般快速地排序、查詢、檢索。
- 3.字形:將倉頡碼輸入“向量字形產生器”後,可組合成漢字,顯示於電腦螢幕或用於列印。
- 4.字辨:把掃描所得的漢字點陣資料輸入,轉換為向量,分析其中的倉頡字根,可得出倉頡碼。這種由“形”得“碼”的過程就是文字辨識。
- 5.字音:大部分的漢字具有形聲的特質,因此將輸入的倉頡碼的字身分析出來,通常可代表該漢字的聲部,即讀音,可用於語音辨識。(但實務上,很多漢字發音已變,須另外處理。)
- 6.字義:由“倉頡碼”可分析出字首和字身,能夠透過程式組合出漢字字義,可供電腦“理解”人類常識,甚至和人類溝通。
倉頡系統即是將上列六大要素綜合考慮而發展出的電腦系統。
批評
 漢字基因
漢字基因其中,“漢字基因字典”的一大特色是把大多數的漢字視作表意字,即象形、指事或會意,特別是把很多簡單形聲字都看成會意。有人認為,這樣“把漢字看成與辭彙無關的直接表達概念的符號”,是完全錯誤的漢字觀念,是一種附會和向壁虛構
相關詞條
輸入法大全
| 輸入法大全及其理論,發明者等。 |
