
概念
Unicode 包含了超過十萬個字元(在2005 年, Unicode 的第十萬個字元被採納且認可成為標準之一)、一組可用以作為視覺參考的代碼圖表、一套編碼方法與一組標準字元編碼、一套包含了上標字、下標字等字元特性的列舉等。Unicode 在字元集認可的成功,使其得以在電腦軟體的國際化與本地化領域中,廣泛且具優勢的被採用。
這標準已在多種新科技當中被加以採用,包含了可擴展置標語言(XML)、Java程式語言以及最新的作業系統中。
歷史
 UNICODE
UNICODEUnicode 試圖將字位(字素,graphemes)與類字位字元加以認定與編碼,而非以不同的字形(glyphs)來加以區分。然而在漢字的個案來看,這樣方式有時會引起一字多形的認定爭議。
在文字處理方面, Unicode 的功用是為每一個字元提供一個唯一的代碼(即一組數字),而不是一種字形。換句話說, Unicode 是將字元以一種抽象的方式來呈現,而將視覺上的演繹工作(如字型大小、外觀形狀、字型形態、文體等)留給其他軟體來處理,如網頁瀏覽器或是文字處理器。
為了使 Unicode 與已存在和廣泛使用的舊有編碼互相兼容,尤其是差不多所有電腦系統都支援的基本拉丁字母部分,所以 Unicode 的首 256 字元仍舊保留給 ISO 8859-1 所定義的字元,使既有的西歐語系文字的轉換不需特別考量;另一方面因相同的原因,Unicode 把大量相同的字元重複編到不同的字元碼中去,使得舊有紛雜的編碼方式得以和 Unicode 編碼間互相直接轉換,而不會遺失任何資訊。舉例來說,全形格式區段包含了主要的拉丁字母的全形格式,在中文、日文、以及韓文字形當中,這些字元以全形的方式來呈現,而不以常見的半角形式顯示,這對豎排文字和等寬排列文字有重要作用。
在表達一個 Unicode 的字元時,通常會用“U ”然後緊接著一組十六進制的數字來表示這一個字元。在基本多文種平面(Basic Multilingual Plane,簡稱 BMP)里的所有字元,只要使用四位十六進制數(例如 U 4AE0,共支持六萬多個字元)來表示,但在 BMP 以外的字元則需要使用五位或六位十六進制數了。舊版的 Unicode 標準使用相近的標記方法,但卻有些微的差異,例如在 Unicode 3.0 里使用“U-”然後緊接著八位數,而“U ”則必須隨後緊接著四位數,以表示僅限於代表一個字元單位(code unit),而非字元(code point)。
標準
 UNICODE標準定義
UNICODE標準定義Unicode組織在 1991 年首次發布了The Unicode Standard(ISBN 0-321-18578-1)。 Unicode 的開發結合了國際標準化組織(International Organization for Standardization,簡稱 ISO )所制定的ISO/IEC 10646,即通用字元集(Universal Character Set,簡稱 UCS )。Unicode 與 ISO/IEC 10646 在編碼的運作原理相同,但The Unicode Standard 包含了更詳盡的實現資訊、涵蓋了更細節的主題,諸如字元編碼(bitwise encoding)、校對以及呈現等。 The Unicode Standard 也列舉了諸多的字元特性,包含了那些必須支援雙方向呈現的文字(由左至右或由右至左的文字呈現方向,如阿拉伯文是由右至左)。 Unicode 與 ISO/IEC 10646 兩個標準在術語上的使用有些微的不同。
在 2005 年, Unicode 的第十萬個字元被輸入成為標準之一,其為馬來亞拉姆語(Malayalam,印度西南部沿海居民的語言)的 Praslesham(പ്രശ്ലേഷം)。
Unicode 截至2008年曆次的版次與發布時間如下:
Unicode 1.0:1991年10月
Unicode 1.0.1:1992年6月
Unicode 1.1:1993年6月
Unicode 2.0:1997年7月
Unicode 2.1:1998年5月
Unicode 2.1.2:1998年5月
Unicode 3.0:1999年9月;涵蓋了來自ISO 10646-1的十六位元通用字元集(UCS)基本多文種平面(Bsic Multilingual Plane)
Unicode 3.1:2001年3月;新增從ISO 10646-2定義的輔助平面(Supplementary Planes)
Unicode 3.2:2002年3月
Unicode 4.0:2003年4月
Unicode 4.0.1:2004年3月
Unicode 4.1:2005年3月
Unicode 5.0:2006年7月
Unicode 5.1:2008年4月。
編碼和實現
大概來說,Unicode 編碼系統可分為編碼方式和實現方式兩個層次。
編碼方式
Unicode的編碼方式與ISO 10646的通用字元集(Universal Character Set,UCS)概念相對應,目前實際套用的 Unicode 版本對應於 UCS-2,使用16位的編碼空間。也就是每個字元占用2個位元組。這樣理論上一共最多可以表示 2 即 65536 個字元。基本滿足各種語言的使用。實際上目前版本的 Unicode 尚未填充滿這16位編碼,保留了大量空間作為特殊使用或將來擴展。
上述16位 Unicode 字元構成基本多文種平面(Basic Multilingual Plane, 簡稱 BMP)。最新(但未實際廣泛使用)的 Unicode 版本定義了16個輔助平面,兩者合起來至少需要占據21位的編碼空間,比3位元組略少。但事實上輔助平面字元仍然占用4位元組編碼空間,與 UCS-4 保持一致。未來版本會擴充到 ISO 10646-1 實現級別3,即涵蓋 UCS-4 的所有字元。UCS-4 是一個更大的尚未填充完全的31位字元集,加上恆為0的首位,共需占據32位,即4位元組。理論上最多能表示 2 個字元,完全可以涵蓋一切語言所用的符號。
BMP 字元的Unicode 編碼表示為 U hhhh,其中每個 h 代表一個十六進制數位。與 UCS-2 編碼完全相同。對應的4位元組 UCS-4 編碼後兩個位元組一致,前兩個位元組的所有位均為0。
關於 Unicode 和 ISO 10646 及 UCS 的詳細關係 ,請參看通用字元集。
實現方式
Unicode 的實現方式不同於編碼方式。一個字元的 Unicode 編碼是確定的。但是在實際傳輸過程中,由於不同系統平台的設計不一定一致,以及出於節省空間的目的,對 Unicode 編碼的實現方式有所不同。Unicode 的實現方式稱為Unicode轉換格式(Unicode Translation Format,簡稱為 UTF)。
例如,如果一個僅包含基本7位ASCII字元的 Unicode 檔案,如果每個字元都使用2位元組的原 Unicode 編碼傳輸,其第一位元組的8位始終為0。這就造成了比較大的浪費。對於這種情況,可以使用 UTF-8 編碼,這是一種變長編碼,它將基本7位ASCII字元仍用7位編碼表示,占用一個位元組(首位補0)。而遇到與其他 Unicode 字元混合的情況,將按一定算法轉換,每個字元使用1-3個位元組編碼,並利用首位為0或1進行識別。這樣對以7位ASCII字元為主的西文文檔就大大節省了編碼長度。類似地,對未來會出現的需要4個位元組的輔助平面字元和其他 UCS-4 擴充字元,2位元組編碼的 UTF-16 也需要通過一定的算法進行轉換。
再如,如果直接使用與 Unicode 編碼一致(僅限於 BMP 字元)的 UTF-16 編碼,由於每個字元占用了兩個位元組,在Macintosh機和PC機上,對位元組順序的理解是不一致的。這時同一位元組流可能會被解釋為不同內容,如編碼為 U 594E 的字元“奎”同編碼為 U 4E59 的“乙”就可能發生混淆。於是在 UTF-16 編碼實現方式中使用了大尾序(big-endian)、小尾序(little-endian)的概念,以及BOM(Byte Order Mark)解決方案。
此外,Unicode 的實現方式還包括 UTF-7、Punycode、CESU-8、SCSU、UTF-32等,這些實現方式有些僅在一定的國家和地區使用,有些則屬於未來的規劃方式。目前通用的實現方式是 UTF-16小尾序(BOM)、UTF-16大尾序(BOM)和 UTF-8。在微軟公司Windows XP作業系統附帶的記事本中,“另外儲存為”對話框可以選擇的四種編碼方式除去非 Unicode 編碼的 ANSI 外,其餘三種“Unicode”、“Unicode big endian”和“UTF-8”即分別對應這三種實現方式。
目前輔助平面的工作主要集中在第二和第三平面的中日韓統一表意文字中,因此包括GBK、GB18030、Big5等簡體中文、繁體中文、日文、韓文以及越南喃字的各種編碼與 Unicode 的協調性被重點關注。考慮到 Unicode 最終要涵蓋所有的字元,從某種意義而言,這些編碼方式也可視作 Unicode 的出現於其之前的既成事實的實現方式,如同ASCII及其擴展Latin-1一樣,後兩者的字元在16位 Unicode 編碼空間中的編碼第一位元組各位全為0,第二位元組編碼與原編碼完全一致。但上述東亞語言編碼與 Unicode 編碼的對應關係要複雜得多。
非Unicode環境
在非 Unicode 環境下,由於不同國家和地區採用的字元集不一致,很可能出現無法正常顯示所有字元的情況。微軟公司使用了代碼頁(codepage)轉換表的技術來過渡性的部分解決這一問題,即通過指定的轉換表將非 Unicode 的字元編碼轉換為同一字元對應的系統內部使用的 Unicode 編碼。可以在“語言與區域設定”中選擇一個代碼頁作為非 Unicode 編碼所採用的默認編碼方式,如936為簡體中文GBK,950為正體中文Big5(皆指PC上使用的)。在這種情況下,一些非英語的歐洲語言編寫的軟體和文檔很可能出現亂碼。而將代碼頁設定為相應語言中文處理又會出現問題,這一情況無法避免。從根本上說,完全採用統一編碼才是解決之道,但目前尚無法做到這一點。
代碼頁技術現在廣泛為各種平台所採用。UTF-7 的代碼頁是65000,UTF-8 的代碼頁是65001。
XML與Unicode
 XML
XML過去電腦編碼的8位標準,使每個國家都只按國家使用的字元而編定各自的編碼系統;而對於部份字元系統比較複雜的語言,如越南語,又或者東亞國家的大型字元集,都不能在8位的環境下好好顯示。連自己的語言也未必可以好好顯示的話,就更惶論顯示其他國家的文字了。然而,現在於HTML和XML,我們可以利用&#nnn;的格式顯示特定的字元。nnn代表該字元的十進位Unicode代碼。如果想採用十六進位代碼的話,要在編碼之前加上x字元。
只是最近才有在文本中對十六進制的支持,那么舊版本的瀏覽器顯示那些字元或許可能有問題-大概首先會遇到的一個問題只是在對於大於8位Unicode字元的顯示。解決這個問題的普遍做法仍然是將其中的十六進制碼轉換成一個十進制碼(例如:用♠代替♠)。
也有一些字元集標準將一些常用的標誌存放在字元內碼外面,那么你可能使用象—這樣的文本標誌來表示一個長劃(—)的情況,即使它的字元內碼已經被使用,這些標準也不包含那個字元。
然而部分由於Unicode版本發展原因,很多瀏覽器只能顯示UCS-2完整字元集,也即現在使用的Unicode版本中的一個小子集。下表可以檢驗您的瀏覽器怎樣顯示各種各樣的Unicode代碼:
一些多語言支持的網頁瀏覽器,比如微軟Windows系統的Internet Explorer5.5,以及跨平台的瀏覽器 Mozilla/Netscape6,可以在安裝時根據需要動態地使用相應的字元集,預先安裝了合適的語言包,就可以同時顯示頁面上的各種Unicode字元。MSIE 5.5還提出用戶可以在需要新字型時,即裝即用。另外的瀏覽器如Netscape Navigator4.77,則只能顯示跟頁面編碼相應字元集中的文字。當你使用後一種瀏覽器時,你不大可能預先安裝所有的字型,即使有了字型,瀏覽器也不一定能將這些字型完全套用起來。可能遇到的情況是,這種瀏覽器只能夠顯示部分文字,因為它們是按照標準進行編碼,儘管理論上在兼容的系統中,只要有了相應的字型,就可以正確顯示。一種變通的辦法,是將某些少見的字元,通過“名稱實體引用”的方式來使用。
輸入
 Microsoft Word
Microsoft Word漢字問題
Unicode的漢字處理方法一直備受抨擊。有指這種把數萬漢字逐一編碼的方式,非常浪費資源,要把漢字加到Unicode標準中也不容易。也有批評處理Unicode中漢字編碼的專家,並不是真正研究漢字的學者。從早期的中文電腦時期開始,已有研究以部件產生漢字(動態組字),取代漢字逐一編碼方法,其中以朱邦復的漢字基因工程成效最豐。
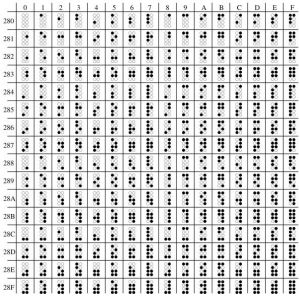
編碼表
| Unicode 編碼表 | ||||
| 0000-0FFF | 8000-8FFF | 10000-10FFF | 20000-20FFF | 28000-28FFF |
| 1000-1FFF | 9000-9FFF | 21000-21FFF | 29000-29FFF | |
| 2000-2FFF | A000-AFFF | 22000-22FFF | 2A000-2AFFF | |
| 3000-3FFF | B000-BFFF | 23000-23FFF | ||
| 4000-4FFF | C000-CFFF | 1D000-1DFFF | 24000-24FFF | 2F000-2FFFF |
| 5000-5FFF | D000-DFFF | 25000-25FFF | ||
| 6000-6FFF | E000-EFFF | 26000-26FFF | ||
| 7000-7FFF | F000-FFFF | 27000-27FFF | E0000-E0FFF |
輸入法大全
| 輸入法大全及其理論,發明者等。 |
