簡介
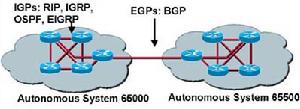
BGP是一種在自治系統之間動態交換路由信息的路由協定。一個自治系統的經典定義是在一個管理機構控制之下的一組路由器,它使用IGP和普通度量值向其他自治系統轉發報文。
在BGP中使用自治系統這個術語是為了強調這樣一個事實:一個自治系統的管理對於其他自治系統而言是提供一個統一的內部選路計畫,它為那些通過它可以到達的網路提供了一個一致的描述。
BGP是自主網路系統中網關之間交換器路由信息的協定。邊界網關協定常常套用於網際網路的網關之間。路由表包含已知路由器的列表、路由器能夠達到的地址以及到達每個路由器的路徑的跳數。
使用邊界網關協定的主機一般也使用傳輸控制協定(TCP)。當網路檢測到某台主機發出變化時,就會傳送新的路由表。BGP-4,邊界網關協定的最新版本,允許網路管理員在策略描述下配置跳數的規格。
簡單擴展
BGP是一種不同自治系統的路由器之間進行通信的外部網關協定。BGP是ARPANET所使用的老EGP的取代品。RFC1267[LougheedandRekhter1991]對第3版的BGP進行了描述。
RFC1268[RekhterandGross1991]描述了如何在Internet中使用BGP。下面對於BGP的大部分描述都來自於這兩個RFC文檔。同時,1993年開發第4版的BGP(見RFC1467[Topolcic1993]),以支持CIDR。
BGP系統與其他BGP系統之間交換網路可到達信息。這些信息包括數據到達這些網路所必須經過的自治系統AS中的所有路徑。這些信息足以構造一幅自治系統連線圖。然後,可以根據連線圖刪除選路環,制訂選路策略。
首先,將一個自治系統中的IP數據報分成本地流量和通過流量。在自治系統中,本地流量是起始或終止於該自治系統的流量。也就是說,其信源IP位址或信宿IP位址所指定的主機位於該自治系統中。其他的流量則稱為通過流量。在Internet中使用BGP的一個目的就是減少通過流量。
可以將自治系統分為以下幾種類型:
1) 殘樁自治系統(stubAS),它與其他自治系統只有單個連線。stubAS只有本地流量。
2) 多接口自治系統(multihomedAS),它與其他自治系統有多個連線,但拒絕傳送通過流量。
3) 轉送自治系統(transitAS),它與其他自治系統有多個連線,在一些策略準則之下,它可以傳送本地流量和通過流量。
這樣,可以將Internet的總拓撲結構看成是由一些殘樁自治系統、多接口自治系統以及轉送自治系統的任意互連。殘樁自治系統和多接口自治系統不需要使用BGP——它們通過運行EGP在自治系統之間交換可到達信息。
BGP允許使用基於策略的選路。由自治系統管理員制訂策略,並通過配置檔案將策略指定給BGP。制訂策略並不是協定的一部分,但指定策略允許BGP實現在存在多個可選路徑時選擇路徑,並控制信息的重傳送。選路策略與政治、安全或經濟因素有關。
BGP與RIP和OSPF的不同之處在於BGP使用TCP作為其傳輸層協定。兩個運行BGP的系統之間建立一條TCP連線,然後交換整個BGP路由表。從這個時候開始,在路由表發生變化時,再傳送更新信號。
BGP是一個距離向量協定,但是與(通告到目的地址跳數的)RIP不同的是,BGP列舉了到每個目的地址的路由(自治系統到達目的地址的序列號)。這樣就排除了一些距離向量協定的問題。採用16bit數字表示自治系統標識。
BGP通過定期傳送keepalive報文給其鄰站來檢測TCP連線對端的鏈路或主機失敗。兩個報文之間的時間間隔建議值為30秒。套用層的keepalive報文與TCP的keepalive選項是獨立的。
詳解
一:背景
路由包括兩個基本的動作:確定最佳路徑和信息群(通常稱為分組)通過網路的傳輸。通過網路傳輸分組相對較簡單,而路徑的確定複雜。BGP就是當今網路中實現路徑選擇的一種協定。下面簡述BGP的基本操作,並提供其協定組件的描述。
BGP在TCP/IP網中實現域間路由。BGP是一種外部網關協定(EGP),即它在多個自治系統或域間執行路由、 與其它BGP系統交換路由和可達性信息。
BGP設計用以代替其前身(現在已不用了)外部網關協定(EGP)作為全球網際網路的標準外部網關路由協定。 BGP解決了EGP的嚴重問題,能更有效地適應網際網路的飛速發展。
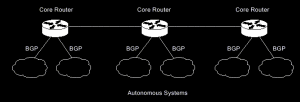
下面是核心路由器用BGP在AS間路由數據的示意圖。
 bgp
bgpBGP在多個RFC中規定:
RFC1771 - 描述了BGP4,即BGP的當前版本。
RFC1654 - 描述了第一個BGP4規範。
RFC1105,RFC1163和RFC1267 - 描述了BGP4之前的BGP版本。
二:BGP操作
BGP執行三類路由:AS間路由、AS內部路由和貫穿AS路由。
AS間路由發生在不同AS的兩個或多個BGP路由器之間,這些系統的對等路由器使用BGP來維護一致的網路拓撲視圖,AS間通信的BGP鄰居必須處於相同的物理網路。網際網路就是使用這種路由的實例,因為它由多個AS(或稱管理域)構成,許多域為構成網際網路的研究機構、公司和實體。BGP經常用於為網際網路內提供最佳路徑而做路由選擇。
AS內部路由發生在同一AS內的兩個或多個BGP路由器間,同一AS內的對等路由器用BGP來維護一致的系統拓撲視圖。BGP也用於決定哪個路由器作為外部AS的連線點。再次重申,網際網路提供了AS間路由的實例。一個組織,如大學,可以利用BGP在其自己的管理域(或稱AS)內提供最佳路由。BGP協定既可以提供AS間也可以提供AS內部路由。
貫穿(pass-through)AS路由發生在通過不運行BGP的AS交換數據的兩個或多個BGP對等路由器間。在貫穿AS環境中,BGP通信既不源自AS內,目的也不在該AS內的節點,BGP必須與AS內使用的路由協定互動以成功地通過該AS傳輸BGP通信,下圖所示為貫穿AS環境:
 bgp
bgp三:BGP路由
與其它路由協定一樣,BGP維護路由表、傳送路由更新信息且基於路由metric決定路由。BGP系統的主要功能是交換其它BGP系統的網路可達信息,包括AS路徑的列表信息,此信息可用於建立AS系統連線圖,以消除路由環,及執行AS策略確定。
每個BGP路由器維護到特定網路的所有可用路徑構成的路由表,但是它並不清除路由表,它維持從對等路由器收到的路由信息直到收到增值(incremental)更新。
BGP設備在初始數據交換和增值更新後交換路由信息。當路由器第一次連線到網路時,BGP路由器交換它們的整個BGP路由表,類似的,當路由表改變時,路由器傳送路由表中改變的部分。BGP路由器並不周期性傳送路由更新,且BGP路由更新只包含到某網路的最佳路徑。
BGP用單一的路由metric決定到給定網路的最佳路徑。這一metric含有指定鏈路優先權的任意單元值,BGP的metric通常由網管賦給每條鏈路。賦給一條鏈路的值可以基於任意數目的尺度,包括途經的AS數目、穩定性、速率、延遲或代價等。
四:BGP訊息類型
RFC1771中規定了四種BGP訊息類型:初始(open)訊息,更新訊息、通知訊息和keep-alive訊息。
初始訊息在對等路由器間打開一個BGP通信會話,是建立傳輸協定後傳送的第一個訊息,初始訊息由對等設備傳送的keep-alive訊息確認,且必須得到確認後才可以交換更新、通知和keep-alive訊息。
更新訊息用於提供到其它BGP系統的路由更新,使路由器可以建立網路拓撲的一致視圖。更新用TCP傳送以保證傳輸的可靠性。 更新訊息可以從路由表中清除一條或多條失效路由,同時發布若干路由。
通知訊息在檢查到有錯誤時傳送。通知訊息用於關閉一條活動的會話,並通知其它路由器為何關閉該會話。
keep-alive訊息通知對等BGP路由器該設備仍然alive。keep-alive訊息發布足夠頻繁以防止會話過期。
五:BGP分組格式
簡述BGP初始、更新、通知和keep-alive訊息類型及基本的BGP信頭格式。
1、信頭格式
所有的BGP訊息類型都使用基本的分組信頭。初始、更新和通知訊息有附加的域,而keep-alive訊息只使用基本的分組信頭。
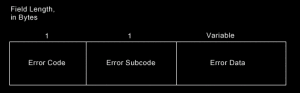
下圖為BGP信頭使用的域:
 bgp
bgp每個BGP分組都包含信頭,其主要目的是標識該分組的功能。下面簡述信頭中的每個域。
標記 - 含有認證值。
長度 - 指示訊息的總長度,以位元組計。
類型 - 標識訊息類型為下列類型之一:
初始
更新
通知
keep-alive
數據:為可選域,含有上層信息。
2、初始訊息格式
BGP初始訊息由BGP信頭和附加域構成,下圖為BGP初始訊息的附加域:
 bgp
bgp在信頭的類型域中標識為BGP初始訊息的BGP分組包含下列各域,這些域為兩個BGP路由器建立對等關係提供了交換方案:
版本 - 提供BGP版本號,使接收者可以確認它是否與傳送者運行同一版本協定。
自治系統 - 提供傳送者的AS號。
保持時間(Hold-time) - 在傳送者被認為失效前最長的不接收訊息的秒數。
BGP標識 - 提供傳送者的標識(IP位址),在啟動時決定,對所有本地接口和所有對等BGP路由器而言都是相同的。
可選參數長度 - 標識可選參數域的長度(如果存在的話)。
可選參數 - 包含一組可選參數。目前只定義了一個可選參數類型:認證信息。認證信息含有下列兩個域:
認證碼:標識使用的認證類型。
認證數據:包含由認證機制使用的數據。
3、更新訊息格式
BGP更新訊息由BGP信頭和附加域構成,下圖為BGP更新訊息的附加域:
 bgp
bgp收到更新訊息分組後,路由器就可以從其路由表中增加或刪除指定的表項以保證路由的準確性。更新訊息包含下列域:
失效路由長度 - 標識失效路由域的總長度或該域不存在。
失效路由 - 包含一組失效路由的IP位址前綴。
總路徑屬性長度 - 標識路徑屬性域的總長度或該域不存在。
路徑屬性 - 描述發布路徑的屬性,可能的值如下:
源:必選屬性,定義路徑信息的來源。
AS路徑:必選屬性,由一系列AS路徑段組成。
下一跳:必選屬性,定義了在網路層可達信息域中列出的套用作到目的地下一跳的邊緣路由器的IP位址。
多重出口區分:可選屬性,用於在到相鄰AS的多個出口間進行區分。
本地優先權:可選屬性,用以指定發布路由的優先權等級。
原子聚合:可選屬性,用於發布路由選擇信息。
聚合:可選屬性,包含聚合路由信息。
網路層可達信息 - 包含一組發布路由的IP位址前綴。
4、通知訊息格式:
下圖為BGP通知訊息使用的附加域:
 bgp
bgp通知訊息分組用於給對等路由器通知某種錯誤情況。
錯誤碼 - 標識發生的錯誤類型。下面為定義的錯誤類型:
訊息頭錯:指出訊息頭出了問題,如不可接受的訊息長度、標記值或訊息類型。
初始訊息錯:指出初始訊息出了問題,如不支持的版本號,不可接受的AS號或IP位址或不支持的認證碼。
更新訊息錯:指出更新訊息出了問題,如屬性列表殘缺、屬性列表錯誤或無效的下一跳屬性。
保持時間過期:指出保持時間已過期,這之後BGP節點就被認為已失效。
有限狀態機錯:指示期望之外的事件。
終止:發生嚴重錯誤時根據BGP設備的請求關閉BGP連線。
錯誤子碼 - 提供關於報告的錯誤的更具體的信息。
錯誤數據 - 包含基於錯誤碼和錯誤子碼域的數據,用於檢測通知訊息傳送的原因。
協定同步規則
一.理解BGP同步及其基本需求
1.BGP同步規則的定義:
在bgp同步打開的情況下,一個BGP路由器不會把那些通過ibgp鄰居學到的bgp路由通告給自己的ebgp鄰居;除非自己的igb路由表中存在這些路由,才可以向ebgp路由器通告.
2.BGP同步規則的目的:
防止一個AS(不是所有的路由器都運行bgp)內部出現路由黑洞,即向外部通告了一個本AS不可達的虛假的路由.
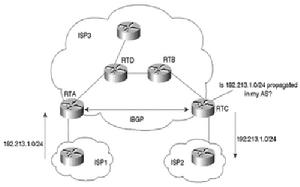 BGP同步規則的拓撲示意
BGP同步規則的拓撲示意3.BGP同步規則的基本需求
如果一個AS內部存在非bgp路由器,那么就出現了BGP和IGP的邊界,需要在邊界路由器將BGP路由發布到igp中,才能保證AS所通告到外部的BGP路由在AS內部是連通的.實際上是要求BGP路由和igp路由的同步.
4.滿足BGP同步規則的基本需求的結果
如果將BGP路由發布到igp中,由於BGP路由主要是來自AS外部的路由(來自internet),那么結果是igp路由器要維護數以萬計的外部路由,對路由器的CPU和memeory以及AS內部的鏈路頻寬的占用將帶來巨大的開銷.
5.結論
通常BGP協定的運行需要關閉同步.
二.BGP同步的解決方案1.full mesh iBGP解決方案
AS內部的所有路由器都運行full mesh iBGP,就可以關閉所有路由器的同步而不影響路由的通告和連通性.
問題:
當AS內部路由器數量很多時,需要建立N*(N-1)/2個ibgp會話,帶來過度的系統開銷,擴展性不好.
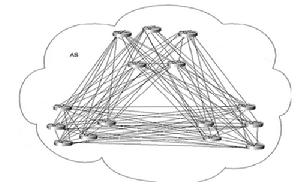 Full-Mesh IBGP 拓撲示意:15個路由器的AS,需要建立15(15-1)/2=105個ibgp會話
Full-Mesh IBGP 拓撲示意:15個路由器的AS,需要建立15(15-1)/2=105個ibgp會話Full-Mesh IBGP 拓撲示意:15個路由器的AS,需要建立15(15-1)/2=105個ibgp會話
2.路由反射器解決方案
AS內部的所有路由器都運行bgp,在AS內部部署路由反射器,構建hub and spoke的ibgp(會話數為N-1), 然後關閉所有bgp路由器的同步.
問題:
此方案可以使bgp路由器傳遞ibgp路由到ebgp, 並保證bgp路由的連通性.但是對物理拓撲有很大的限制(要求是星型拓撲)
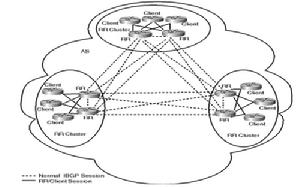 Bgp路由反射器設計拓撲 15個路由器的AS,具有冗餘的RR方案(33個ibgp會話)
Bgp路由反射器設計拓撲 15個路由器的AS,具有冗餘的RR方案(33個ibgp會話)3.bgp聯盟解決方案:
AS內部的所有路由器都運行bgp,把一個原始的AS基於網路拓撲劃分為若干個sub-AS(又稱聯盟AS),聯盟AS之間的bgp鄰居叫做聯盟ebgp,不需要full mesh bgp會話;在每個聯盟AS內部運full mesh ibgp或者hub and spoke反射器,然後就可以關閉所有路由器的bgp同步功能.
結論:
bgp聯盟結合路由反射器的方式較好的解決了bgp的同步規則帶來的需求,是最為有效的解決方案.
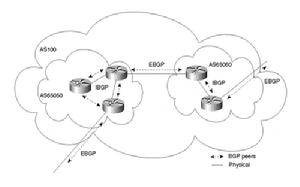 bgp聯盟拓撲示意圖
bgp聯盟拓撲示意圖bgp聯盟拓撲示意圖
三.BGP同步規則的總結
1.在所有的方案中, 既要保證傳遞bgp路由,還要保證bgp路由的連通性.
2.關閉同步能夠實現bgp路由的傳遞,不一定能保證as內部連通性,除非as內所有路由器都運行bgp才可以保證連通性;否則,仍然需要路由再發布(bgpàigp)
3.最後,在as內部一般需要部署igp來維持AS內部網路路徑的連通性,以保證as內部的所通告的bgp路由的下一跳的可達性.這樣bgp網路就具有更好的靈活性和擴展性.
協定分析-報文、狀態機
BGP是一種自治系統間的動態路由發現協定,它的基本功能是在自治系統間自動交換無環路的路由信息。與OSPF和RIP等在自治區域內部運行的協定對應,BGP是一類EGP(Edge Gateway Protocol)協定,而OSPF和協定。
BGP是在EGP套用的基礎上發展起來的。EGP在此以前已經作為自治區域間的路由發現協定,廣泛套用於NFSNET等主幹網路上。但是,EGP被路由環路問題所困擾。BGP通過在路由信息中增加自治區域(AS)路徑的屬性,來構造自治區域的拓撲圖,從而消除路由環路並實施用戶配置的策略。同時,隨著INTERNET的飛速發展,路由表的體積也迅速增加,自治區域間路由信息的交換量越來越大,都影響了網路的性能。BGP支持無類型的區域間路由CIDR(classless Interdomain Routing),可以有效的減少日益增大的路由表。
BGP運行時刻分別與本自治區域外和區域內的BGP夥伴建立連線(使用Socket)。與區域內夥伴的連線稱為IBGP(Internal BGP)連線,與自治區域外的BGP夥伴的連線稱為EBGP(External BGP)連線。本地的BGP協定對IBGP和EBGP夥伴使用不同的機制處理。
1、BGP協定的層次位置
BGP使用Socket服務建立連線,連線埠號為179。
2、BGP的訊息結構
BGP有4種類型的訊息。分別為OPEN,UPDATE,KEEPALIVE和NOTIFY。它們有相同的訊息頭
⑴訊息頭結構:
Marker : (16位元組) 鑒權信息
Length : (2位元組) 訊息的長度
Type : (1位元組) 訊息的類型
0 :OPEN
1 :UPDATE
2 :NOTIFICATION
3 :KEEPALIVE
⑵OPEN訊息結構:
訊息頭加如下結構 :
Version :(1位元組) 發端BGP版本號
My Autonomous system :(2位元組無符號整數) 本地AS號
Hold Time :(2位元組無符號整數) 發端建議的保持時間
BGP Identifier :(4位元組) 發端的路由器標識符
OptParmLen :(1位元組) 可選的參數的長度
Optional Parameters :(變長) 可選的參數
⑶KEEPALIVE訊息結構
KEEPALIVE訊息只有一個訊息頭。
⑷NOTIFY訊息結構
訊息頭加如下結構:
Errsubcode :(1位元組) 輔助錯誤代碼,略。
Data :(變長) 依賴於不同的錯誤代碼和輔助錯誤代碼。用於診斷錯誤原因。
⑸UPDATE訊息結構
訊息頭加如下結構:
Unfeasible Routes Len :(2位元組無符號整數) 不可達路由長度
Withdrawn Routes :(變長) 退出路由
Path Attribute Len :(2位元組無符號整數) 路徑屬性長
Path Attributes :(變長) 路徑屬性(以下詳細說明)
Network Layer Reachability Information :(變長) 網路可達信息(信宿)
其中退出路由和信宿地址的表示方法為一 的二元組。length一個位元組,指示地址前綴的長度。prefix為地址前綴,長度1至4位元組。
3、BGP路徑的屬性
每個路徑屬性由1位元組的屬性標誌位,1位元組的屬性類型,1或2位元組路由屬性長度和路徑屬性數據組成。
屬性標誌位:
位0:0 表示此屬性必選,1 表示此屬性可選。
位1:0 表示此屬性為非過渡屬性,1表示此屬性為過渡屬性。
位2:0 表示所有屬性均為路由起始處生成,1 表示中間AS加入了新屬性。
位3:0 表示路由屬性長度由1位元組指示,1表示由2位元組指示。
位4至位7:未用置0
位0和位1標識了BGP的4類路由屬性:
-(01) 公認必選:BGP的UPDATE報文中必須存在的屬性。它必須能被所有的BGP工具識別。公認必選屬性的丟失意味著UPDATE報文的差錯。這是為了保證所有的BGP工具統一於一套標準屬性。
-(01) 公認自決:能被所有BGP識別的屬性,但在UPDATE報文中可發可不發
-(11) 可選過渡:如果BGP工具不能識別可選屬性,它就去找過渡屬性位。如果此屬性是過渡的,BGP工具就接受此屬性,並把它向前傳遞給其它BGP路由器。
-(10) 可選非過渡:當可選屬性未被識別,且過渡屬性也未被置位時,此屬性被忽略,不傳遞給其它BGP路由器。
路由屬性類型:
⑴ORIGIN (Type Code = 1,公認必選屬性)
指示此路由起始類型:
⑵AS_PATH (Type Code = 2,公認必選屬性)
AS路徑屬性由一系列AS路徑段(Segment)組成。每個AS路徑段為一三元組。
路徑類型有:
路徑段長度用1位元組表示AS號的數量,即最長為255個AS號。
路徑值為若干AS號,每個AS號為2位元組。
⑶NEXT_HOP (Type Code = 3,公認必選屬性)
此屬性為UPDATE訊息中的信宿地址所使用的下一跳。
⑷MULTI_EXIT_DISC (Type Code = 4,公認自決屬性)
簡稱MED屬性。為一4位元組無符合整數。它在AS區域間傳播,用來幫助一個其它AS區域的BGP夥伴選擇進入本AS區域的人口。
⑸LOCAL_PREF (Type Code = 5,公認自決屬性)
本地優先權屬性。為一4位元組無符合整數。它在AS區域內傳播,用來幫助一個本AS區域內BGP夥伴選擇進入其它AS區域的出口。
⑹ATOMIC_AGGREGATE (Type Code = 6,公認自決屬性)
元聚合屬性。長度為零。它表示本地BGP在若干路由中選擇了一個較抽象的(less specific)路由,而沒有選擇較具體(specific)的路由。
⑺aggregator (Type Code = 7,可選過渡屬性)
聚合者屬性。長度為6位元組,分別為最後進行路由聚合的路由器的AS號(2位元組)和IP位址(4位元組)。
4、BGP協定的特點
BGP是一種AS(自治區域)外部路由協定,主要負責本自治區域和外部的自治區域間的路由可達信息的交換。因此,它所關心的拓撲結構是AS(自治區域)的拓撲結構,BGP通過UPDATE訊息中路由的AS屬性來構造AS的拓撲結構圖,進一步通過此結構圖來選擇路由。
與OSPF,RIP等IGP協定相比,BGP的拓撲圖要更抽象和粗略一些。因為IGP協定構造的是AS內部的路由器的拓撲結構圖。IGP把路由器抽象成若干端點,把路由器之間的鏈路抽象成邊,根據鏈路的狀態等參數和一定的度量標準,每條邊配以一定的權值,生成拓撲圖。根據此拓撲圖選擇代價(兩點間經過的邊的權值和)最小的路由。這裡有一個假設,即路由器(端點)轉發數據包是沒有的代價的。而在BGP中,拓撲圖的端點是一個AS區域,邊是AS之間的鏈路。此時,數據包經過一個端點(AS自治區域)時的代價就不能假設為0了,此代價要由IGP來負責計算。這體現了EGP和IGP是分層的關係。即IGP負責在AS內部選擇花費最小的路由,EGP負責選擇AS間花費最小的路由。
BGP作為EGP的一種,選擇路由時考慮的是AS間的鏈路花費,AS區域內的花費(由BGP路由器配置)等因素。
如上所述,內部網關協定IGP需引入AS自治區域內部網路拓撲圖其它各點的路由,同時向其它端點傳送本端點(路由器)所知的路由,如直接路由、靜態路由等。作為外部網關協定,BGP傳送和引入路由的單位是整個AS自治區域,即BGP要傳送本地路由器所在的AS內部的所有路由,引入其它AS自治區域的所有路由(假設不使用路由策略控制傳送和引入)。其路由數量顯然要遠遠大於IGP傳送和引入的路由數量。因此,類似於IGP那樣定時對外廣播路由信息是不可取的。BGP採用傳送路由增量(Incremental)的方法,完成全部路由信息的通告和維護:初始化時傳送所有的路由給BGP對端(BGP Peer),同時在本地保存了已經傳送給BGP對端的路由信息。當本地的BGP收到了一條新路由時(如通過IGP注入了新路由或加入了新的靜態路由),與保存的已傳送信息進行比較,如未傳送過,則傳送,如已傳送過則與已經傳送的路由進行比較,如新路由花費更小,則傳送此新路由,同時更新已傳送信息,反之則不傳送。當本地BGP發現一條路由失效時(如對應連線埠失效),如此路由已傳送過,則向BGP對端傳送一個退出路由訊息。
套用於IP骨幹網
1 制約BGP擴展性的幾個問題
BGP是目前套用在網際網路上的IP網路互聯協定,為運營商之間的互聯提供了穩定而安全的路由協定,具有豐富的路由控制機制。為了更好地控制路由策略,當前大部分的運營商均將BGP部署到骨幹路由器。隨著網路的不斷擴展、路由器數目的增多以及路由信息條目的激增,解決BGP的擴展性問題變得越來越重要。
目前BGP的擴展性面臨如下幾個問題。
(1)I-BGP的Full-Mesh問題
BGP路由協定分為I-BGP和E-BGP兩個部分。I-BGP用於自治域內的路由器之間,E-BGP用於自治域間的路由器之間。為了防止產生環迴路由,BGP協定要求一個路由器通過I-BGP學到的路由,不再向其他I-BGP鄰居廣播,所以一個自治域內所有參加I-BGP協定的路由器都要與其他路由器建立會話,從而保證路由信息能夠正確地廣播到每一個路由器。依照這個原則,一個自治域內總的I-BGP會話數為N×(N-1)/2 (N為運行I-BGP的路由器數),當N不斷增大時,這個數字會大得驚人:如100台路由器,則會話數為4950。這對網路設備而言是個非常大的負擔,而且還將使網路的管理與配置變得異常複雜。而骨幹網通常由大量的運行I-BGP的路由器組成,因此,這個問題是否能夠解決,直接影響到網路規模的大小。
(2)更改路由策略時路由振盪的問題
BGP屬於增量更新的路由協定,當有新的路由要發布時,路由器會向鄰居傳送Update信息,而如果要刪除某條路由時,就會傳送Withdraw信息。BGP路由的Flap的定義是:當一條路由在被收回(Withdraw)後,又被廣播(Update)出來,視為一次Flap。由於任何一條路由的收回和更新都會導致一台路由器整個路由表重新計算,因此當Flap的情況比較多時,對路由器設備的負載將產生巨大的壓力。根據筆者在實際工作中的經驗,一般情況下,一台高端路由器在計算BGP路由的時候,CPU的負載基本上在80%~90%左右,有時甚至達到100%,占用了幾乎所有的CPU資源。雖然目前大部分的高端路由器都將路由計算的模組與轉發模組分布在不同的硬體上,來減少主CPU忙導致的路由器性能下降的問題,但是路由表的頻繁變化和更新,對整個設備的運行還是有一定的影響的,而且這樣的計算會隨著路由的收回或廣播,繼續向自治域內部擴展,使內部的路由器產生同樣的問題。
(3)其他需要考慮的問題
除了上面的兩個問題會導致對路由器資源過量消耗之外,還有其他的一些因素,如路由的數目、BGP路由表的大小和路由計算的方式等,同樣也會影響路由器的性能。
另外,網路越大,路由條目越多,配置和管理的工作也就越複雜,這就需要在網路設計的時候儘量簡化配置,降低管理人員的工作強度,避免人為原因造成故障。
2 如何解決制約BGP擴展性的問題
針對以上問題,介紹一些相關的解決方法。
(1)解決I-BGP會話數瓶頸的方法
上面提到的I-BGP的會話數過多的問題,可以採取兩種辦法來解決:
1)聯盟的方法(Confederations)
聯盟的工作原理是:將原來一個自治域的網路分成多個子自治域,通過Confederations id將原AS號配置到每個路由器上。這樣有兩個好處:一是可以保留原有的I-BGP屬性,包括Local Preference、MED和NEXT_HOP;二是能在Confederations的功能中自動實現,無需管理員在網路的出口處配置過濾內部AS號信息的操作。
2)路由反射器(Route-Reflector)
採用路由反射器是目前套用最廣泛的方法,較之前面聯盟的方法,具有更好的擴展性。路由反射器的工作原理是:將一個自治域內的路由器分成幾個Cluster,每個Cluster由Reflector和Client組成。Reflector之間形成Full Mesh,運行常規的I-BGP;Client只與Reflector運行I-BGP,對於Client來說,Reflector只是普通的鄰居而已,Reflector則扮演了路由集散地的角色,將從其他Reflector學到的I-BGP路由轉發給Client,同時,將從Client學到的I-BGP路由轉發給Cluster內的其他Clients和Cluster外的其他Reflector,再藉由Reflectors廣播到其所在的Cluster。在實際的網路中,為了提高冗餘度,通常一個Client與多個Reflector建立鄰居關係,而且不局限於Client所在Cluster的Reflector。
由此可見,Client上的I-BGP會話數一般為1~2個,與聯盟的方法相比,只要Reflector的性能足夠高,Cluster就可以做得很大,而Client的負載不會隨Cluster的變化有太大的變化。對於前一種方法,由於一個子自治域的所有路由器還是要做到Full Mesh,所以最低性能的路由器決定了一個子自治域的大小;而路由反射器法則通常是一個或多個最高性能的路由器決定Cluster的大小,因此,具有更好的網路擴展性能。
另外,一個Reflector也可以成為另外一個Reflector的Client,形成層級結構,這特別適用於按照分層結構建設的網路,可以很容易地把平面的網路管理演變為分層管理。
當然,在使用路由反射器的時候,也有一些需要注意的地方,比如:Reflector並不是純粹的轉發路由,所有收到的路由在Reflector上同樣要經過最優計算,然後將優選路由向外廣播,所以Reflector的選擇要依據網路結構而定,儘量使I-BGP鄰居關係與實際的電路連線關係相對應。
(2)控制路由振盪
目前,控制Route Flap主要採取Damping的方法:一個BGP路由器對收到的E-BGP路由設定Penalty值,每一次路由Flap都會使該路由的Penalty值增大,而路由穩定時,Penalty值會隨時間而減小;當Penalty值超過預設的抑制限制時,該路由就不再被廣播,而當Penalty減小至低於重用限制時,該路由才會被重新向外廣播。這種方法主要是針對E-BGP鄰居而言的。這樣,當一個網路內部發生路由振盪時,與之相連的其他網路通過Damping可以有效地防禦對各自網路的影響。
在網路維護中,經常會遇到這樣的情況:寧願一條電路中斷一段時間,也不希望它在不停地震盪。因為中斷一段時間後,只要電路恢復,網路流量也會隨之恢復;與此相反,振盪的電路恢復後,需要等待一段時間才能恢復正常的流量(其他網路都在抑制振盪的路由)。Damping則可以有效地保證網際網路的穩定,但同時也會導致一些故障的延時恢復。
當前的設備基本都支持Damping的功能,而且提供可以配置的參數來精細控制Damping。一般情況下,設備提供的預設配置能夠滿足大多數網路的需求,如果確有特殊需要,則一定要經過仔細計算,否則,不是沒有效果,就是把別人的路由抑制後很長時間不能恢復。
(3)Peer Group的套用
在實際的網路中,有一種非常普遍的現象,即一個路由器會有多個屬於一類的BGP Peer。這裡的“屬於一類”是指BGP的策略相同或類似,當Peer比較多時,BGP的配置會變得臃腫,同時,路由器的負載也會加重,因為一旦有路由的更新,路由器需要針對每個Peer做一次策略計算(雖然策略都相同)。另外,套用Peer Group還有一個好處,就是降低了對路由器設備的資源消耗,因為路由器對同一Group更新路由時,由於使用相同策略,因此只進行一次路由計算,從而大大減少了占用CPU的時間。
在實際的網路維護中,即使當同一類的Peer很少時,一般也建議採用Peer Group的方式,因為這樣具有很好的擴展性。Peer Group不但適用於I-BGP的Peer,也適用於E-BGP的Peer。
(4)關於route refresh的措施
骨幹網路維護中,經常會遇到修改BGP策略的情況,如更新某個Peer的as-path限制列表,在配置修改後需要使其生效,以前的做法是中斷當前的BGP會話,然後重新建立,命令如下:
clear ip bgp x.x.x.x
這么做主要是因為路由器在收到對方的BGP路由表後,先進行策略運算,然後將最優路由存儲在本機的BGP路由表中,而不是把原始的路由統統保存。當策略改變時,必須重新建立連線來獲得對方的全部路由,然後利用新策略再次計算。這種方式的弊端顯而易見,如網路阻斷、大量消耗路由器的CPU資源等。
解決這個問題目前通常採用兩種方法:一種方法是設法保存原始的BGP路由,這樣,重新計算時就不需要重傳了;另外一種方法是在啟用新策略的時候,在不中斷BGP會話的前提下,向對方請求重發全部BGP路由表。
第一種方法是利用軟體配置實現的,配置的命令如下:
neighbor 1.1.1.1 soft-reconfiguration inbound
在啟用新策略的時候輸入命令:
clear ip bgp 1.1.1.1 soft [in|out]
這樣,所有的原始BGP路由就會被存儲在另外一張路由表裡面,在修改策略的時候,通過對這張路由表進行運算,就可以得到最優的BGP路由表,這樣對路由產生的資源消耗較小;而且有這樣一張原始的路由表,可以在修改策略後、正式啟用之前使用命令來檢查策略修改後的效果。但這種方法需要額外的記憶體資源來存儲路由表。
第二種方法是由路由器設備的BGP 能力(BGP Capabilities)決定的,也就是系統軟體本身內置的功能模組。在建立BGP會話的時候,這個參數通過BGP OPEN在兩個路由器間進行交換。一個設備是否支持BGP Refresh Capabilites,可以用命令下列來檢查:
show ip bgp n x.x.x.x
如果參與BGP的兩個路由器都具備這個功能,那么不需要任何配置,當執行clear ip bgp n x.x.x.x in 時,本端BGP進程不會中斷BGP會話,而是向對端請求重發全部的BGP路由表。相對於第一種方法,這種方法的好處是可以節省記憶體資源,缺點是網路管理員無法了解對方發過來的原始路由,而且重發了全部路由表,效率上也沒有第一種方法高。目前骨幹網內的設備基本上都支持這個功能。
3 總結
以上對BGP擴展性相關的幾個問題和相關的措施進行了論述,在實際的套用中還需要根據具體情況來部署。但是總的思路和原則都是一樣的,即一方面要降低設備的資源消耗,另外一方面要簡化維護管理,從硬體、軟體兩方面來提高網路的擴展性。
鄰居協商過程
BGP有5種message
1. Open (code 1):用於建立連線,包含版本號(如BGP3/BGP4)Hold Time=180s(是一個協商的過程,以較小的Hold Time為準),Router-ID(OSPF和BGP可以手動配置),AS號(範圍從1~65535,其中64512~65535 的AS編號範圍留作私有);
2. KeepAlives(code 4):周期傳送用於維護連線檢查路徑(這個包是不可靠的),T=Hold Time/3, Hold Time=0 => No KeepAlive.,keepalive 是個19 位元組周期傳送的BGP 訊息頭標,沒有數據域。
3. Update(code 2):訊息包含了三個組件:網路層可達性訊息(NLRI)、路徑屬性和被撤銷的路由。包括到達目的網路的路徑和屬性,更新路由信息用,一次更新只有一條路徑,但可以有多條網路。Update可以刪除(宣告不可達)和增加(宣告可達)路由.其內容是前綴的長度。
4. Notification(code 3):網路中出現錯誤(Error),檢測到後下線並傳送通知給對方。
5.Route-Reflesh message:一個可選的message (negotiated during capability advertisement) that is sent to request dynamic BGP route updates from the Adj-RIB-Out table of a remote BGP speaker
協商過程基本上是:Idel,connect,open sent,open confirm,establish。
BGP鄰居建立會話的5種狀態:
1. Idle:查找路由表,該過程BGP對它的資源進行初始化,復位一個連線重試計時器,發起一條TCP 連線,並開始傾聽遠程對等體所發起的連線。
2. Connect:找到路由表後進行TCP三次握手,TCP 連線成功,則轉到OpenSent狀態,TCP連線失敗,則轉到active 狀態,將嘗試再次連線。
3. Open Sent:握上手後傳送Open message訊息,等待其對等體傳送打開訊息,如果出錯,則傳送一條出錯訊息並退回空閒狀態,如果無錯,則開始傳送Keepalive 並復位keepalive 計時器。
4. Open Confirm:收到對方發來的Open訊息,如果收到keepalive 訊息,BGP 就進入established狀態,鄰居關係協商完成;如果系統收到一條更新或keepalive 訊息,它將重新啟動保持計時器;如果收到Notification訊息,BGP 就退回到空閒狀態。
5. Established:會話建立,鄰居關係協商過程最終狀態;這時BGP將開始與它的對等體交換路由更新數據包。
PS: Active狀態:當路由器傳送出OPEN包給鄰居等待回應,如果長時間未接收到回應則逾時,逾時後狀態更改為Idle還是connect狀態?試圖發起TCP連線獲得對等體,成功轉到Open Sent狀態,連線重試計時器逾時,退回連線狀態,這是由於TCP鏈路上出現了問題所致。??
產生問題的原因主要有:
1. Neighbor命令後面的ip-address配置有錯;
2. 沒有打上Neighbor命令(兩邊都要)
3. 更新源錯誤,或者更新源不可達。
answer:
1.當BGP speaker處於active狀態,BGP嘗試通過初始化傳輸協定連線來形成peer。如果傳輸連線建立,則進入OpenSent狀態。(同時傳送OPEN信息)。如果ConnectRetry 計時器逾時,BGP重啟ConnectRetry計時器,並且退回到Connect 狀態。只有當系統中止,或者人為地把TCP中止時才退到Idle狀態。
2.問:在IBGP關係中,在sh ip b的時候看到的那個next-hop的ip 地址。下一跳地址,就是通告該路由的IBGP 的 更新源。???還是Router-id???
answer:next-hop的IP位址是更新源地址。Router-ID其實只是路由器的一個標識而已,沒有太多的意義。可以是虛擬的。比如,它通常就是loopback地址。不要求一定TCP可達。但是更新源必須TCP可達。否則怎么保障路由信息更新的一定傳達目的地?對吧。
還有一個解決方法關鍵看sh ip bgp nei裡面的tcp會話那一塊,又還是沒有。如果沒有,檢查路由和acl。
在可擴展的網路中
橫向隔離規則規定:
通過IBGP學到的路由永遠不能被傳輸到其它IGBP對等體。
路由反射器(Route Reflector)
路由反射器讓被配置為路由反射器的路由器向其他IBGP對等體傳輸由IBGP所學到的路由來修改BGP的橫向隔離規則。
路由反射器的優點:
配置了BGP路由反射器,就不再需要全互連的IBGP對等體。路由反射器被允許向其它IBGP對等體傳輸IBGP路由。當內部鄰居命令語句數量過多時,I SP就會採用路由反射器技術。路由反射器通過讓主要路由器給它們的路由反射器客戶複製路由更新來減少AS內BGP鄰居關係的數量(這樣可以減少T CP連線)。
路由反射器不影響IP數據包所要經過的路徑;只有發布路由信息的那條路徑受影響。如果路由反射器沒有被正確配置,那么將可能產生路由環路。
路由反射器的術語:
路由反射器:是被配置為允許它把通過IBGP所學到的路由通告(或反射)到其他IBGP對等體的路由器。
集群:路由反射器出其它客戶的組合;
客戶:路由反射器和其他路由有部分IBGP對等關係的這些路由器
非客戶:不是路由反射器的客戶的其他IBGP的對等體;
originator(始發者) ID:是任選的、非傳遞BGP屬性,它被路由反射器創建。這個屬性帶有本能AS內部由始發者的路由ID;
路由反射器集群表:路由報經過的集群ID序列。
originator(始發者) ID、集群ID和集群表有助於在路由反射器配置中防止產生路由環路。
用來將路由器配置為BGP路由反射器,並且將指定的鄰居配置為它的客戶:
neighbor ip-address route-reflector-client
ip-address:將被標識為客戶的BGP鄰居的IP位址
bgpcluster-id cluster-id: 配置集群ID
show ip bgp neighbors: 顯示那個鄰居是路由反射器客戶
策略控制和前綴列表(Prefix list)
發布列表利用訪問控制列表來指定哪些路由信息將被過濾。
採用前綴列表的優點:
*在大型列表的載入和路由查找方面比訪問控制列表有顯著的性能改進
*支持增量修改;
*較友好的命令行接口
*更大的靈活性
配置前綴列表:
ip prefix list-name [seq seq-value][deny | permit]network/len [ge ge-value] [le le-value]
關閉前綴列表條目序號
no ip prefix-list sequence-number
重新啟用序號自動生成功能
ip prefix-list sequence-number
查看前綴列表
show ip prefix-list
配置鄰居連線權重
neighbor {ip-address | peer-group-name} weight weight
改變預設的本地優先值
bgp default local-preference value
路由的最佳化
 bgp
bgp當BGP選擇一個路由時,如果能考慮到每個ISP連線所能提供路由通路的性能等因素的話,情況肯定會更好。
RouteScience的PathControl是這樣一種新產品,它不僅可以衡量通過每個BGP對等體的路由性能,還可以根據這些信息來改變通過BGP的優先路由。
PathControl勇挑重任
PathControl 1.1運行在Linux上,提供獨立的功能,一個用於報告,一個用於管理,還有一個給核心引擎,對於每個外部BGP對等體都有一個接口。
PathControl 1.1提供了一個強健的Java程式工具。下一個版本將允許從GUI(圖形用戶界面)配置PathControl,但在目前的版本中必須通過基於IOS的命令行界面管理設備。
PathControl所能提供的不只是連線性能和它們的相應通路等內部信息,還可以讓你通過配置一些變數來控制使用那些連線。
PathControl可被放置於邊緣路由器之後的任何位置。對路由器的連線可以通過一個專用連線埠或一個通道連線建立,無論哪種方式,PathControl都需要對外部世界和邊緣路由器進行訪問。
測試見性能
將PathControl直接連線到一個Cisco Catalyst 6500交換機上,交換機被配置為接收來自兩個Nortel Web交換機(一台180e和一台AD4)的外部BGP輸入數據。PathControl被設定與Cisco交換器對等,監視被每個Nortel設備聲明的路由。PathControl可以保持在被動狀態,監視並報告每個遠程對等體的性能;它也可以被置於聲明模式,這使它可以在確定了哪一條連線性能更好後,在邊緣路由器上改變首選路由。
用戶可以配置PathControl更改路由的頻度,使用戶的邊緣路由器不會被壓制。最好讓PathControl至少在被動模式下持續運行幾天,使用報告發生器來觀察PathControl聲明一個新路由的頻度,然後針對具體情況確定最佳的更改頻度。
PathControl用一個TCP握手的往返時間作為其性能度量的基礎,經由HTTP向一台客戶機傳送一幅1x1像素的GIF圖像來被動檢索衡量性能的數據,還可通過探查用戶設定的Web站點來進行主動檢索。對於後者,PathControl打開一個到達某站點的TCP連線並測量完成三向TCP握手的時間。
為實現被動測量,設備上的每一個測量接口都被配置一個虛擬IP位址(Virtual IP Address,VIP)。當經由HTTP或HTTPS訪問該地址時,返回一個1x1像素的GIF圖像。PathControl直接提供這個GIF,測量與一台客戶機建立起一個TCP通話的時間。只要將VIP位址嵌入進站點網頁的一個HREF,一旦某台客戶機發出對該頁的請求,測量就開始。此中的關鍵是對基於策略路由的使用,該路由在邊緣路由器上配置,根據源地址連貫地轉送通訊數據。這樣PathControl會連續測量每條路徑的性能,而不必考慮路由表中的其它項。
默認狀態下PathControl為執行對數據的計算至少需要6次測量。計算過程賦予每條路徑一個等級,該等級將用於確定哪條連線工作得更好。在默認狀態下,如果兩個或更多的等級被賦的數值差別不超過25點,它們都會被認為“更好”。如果某條連線的等級比另一條高出25點,則它被認為是“最好”的,PathControl會經由內部邊界網關協定(interior BGP,iBGP)向與之對等的邊緣路由器聲明這條路由。
ISP網內部署
 bgp
bgp從總體上,在域內部署BGP路由協定應考慮以下幾點:
1.網路實際的拓撲結構;
2.設備性能是否滿足啟動BGP的要求,通常BGP的路由表非常龐大,以從50,000條增加到現在約100,000餘條。這對路由器的記憶體及性能要求很高;
3.在有多條INTERNET接入線路時,線路的備份和流量的分布。
以下將通過一些例子來具體說明這些問題。在繼續討論前,我們先提及幾個概念:
核心層:具有高速交換能力的骨幹網路,位於網路的核心。
分布層:在核心層的外圍,通常用於實現各種路由策略或實施訪問控制等功能。
接入層:在網路的最外層,在該範圍內的路由器是用戶聯入ISP的接入點。
在網路發展初期,網路結構比較簡單(如圖一),ISP只有一條線路連線到INTERNET。通常人們不會在這種簡單的網路結構中使用BGP,而會使用簡單方便的靜態路由進行互聯。這樣可以簡化路由器配置,便於管理,同時降低對邊界路由器的性能要求,減少成本。
如果需要啟用BGP,操作也很簡單只需在路由器R1上啟用BGP,並將R1作為網內其它路由器的預設網關,從而達到將外部路由注入網內的目的。
隨著網路的近一步發展,ISP需要通過不同的網路提供商,通過多條線路與INTERNET連線,以保證網路的可靠性。這時BGP才有了真正的用武之地。在這種情況下,網路通常會出現以下幾種結構。如圖二,圖三。兩種網路結構看起來有些類似,圖三中網路結構只是增加了一台路由器以排除圖二中路由器R1產生單點故障的可能,但在如何部署BGP路由時卻完全不同。
在圖二中只需在R1上配置BGP,並將R1作為網內其它路由器的預設網關,並通過
BGP路由協定所提供的Weight這個路由參數,調節網內流量在兩條線路上的分布。這樣即可實現線路的互為備份,又可有效的調節流量分布。
有兩台路由器擁有外部路由,通常為保證域內的路由一致性,需在圖中路由器R1和R2之間建立IBGP連線,使其建立一致的BGP路由表。在這個過程中,也可人為的使用BGP路由協定所提供的Local-Preference這個路由參數,最佳化路由選擇,以控制數據流量線上路上的分布。但如何將這些外部路由告知網內的其它路由器,簡單的有以下兩種方法:
1.在網路結構相對簡單時,網路沒有分布層,核心層直接與接入層連線。這時接入層路由器往往不能在傳輸大量的用戶數據的同時, 滿足啟用BGP所需的性能要求。在這種情況下,只有依據流量的分布情況,將網內接入路由器劃分組別,不同的組別將預設網關指向不同的邊界網關路由器。
這種設計只能作為網路結構不完善,設備性能不高時的臨時方案,不能作為永久性方案。因為它經常需要人為干預,依據網路流量變化情況重新劃分路由器組別,否則會出現某一路由器負載過重,而另為一台負載較輕的情況,從而不能有效的使用設備資源。而且當互聯的線路增多時,這種設計會面臨更多的問題。
2.最好的方法是首先要建立完善網路結構,網路結構應具備核心層,分布層和接入層。通過IBGP路由協定將外部路由注入到分布層路由器中,如圖二中路由器R3,R4。進而將分布層的路由器作為某一區域接入層路由器的預設網關,將通往域外的負載均勻的分布到各個分布層路由器上,從減少對具體某個路由器的壓力。
這種設計是網路結構日趨完善,網路規模日趨擴大的ISP最終的選擇。
最近CISCO公司有從另一角度提出一個部署BGP路由協定的新思路,使用IBGP作為內部路由協定,交換網內用戶路由信息。及在網路的接入層路由器上啟用IBGP路由協定,並將指向用戶的靜態路由分布到IBGP中。這主要是考慮,BGP路由協定在路由變動時,只更新發生變動的路由,不會象OSPF和ISIS,重新計算SPF資料庫。因而利用BGP這一特性減少路由收斂時間,提高網路的穩定性。但在使用這種方法時,應注意BGP對路由器性能的要求,應避免將外部路由注入到接入層路由器中,導致路由器工作性能下降。
綜上所述,我們簡單討論了如何在ISP的網路上部署BGP路由協定。實際上,BGP的套用重點和優勢在於其對路由信息的控制能力, 從而達到對數據流量的控制和分配。這是一項非常複雜的工作,要依據具體的情況而定,在本文就不多談了。但有一點需要注意,僅僅依靠BGP自身的手段來滿足各種不同的實際需要是不可行的,還需與互聯夥伴共同協作才能實現,因為BGP中的許多參數需要互聯雙方共同商定,才能生效。
建立連線及衛星鏈路
一、技術介紹
 bgp
bgp在建立BGP動態路由時,要使路由器間處在一個自治域中,建立鄰居路由更新從環路地址更新。
由於BGP生成動態協定是建立在TCP的基礎上,它通過環路地址的鄰居關係建立雙向握手,從而生成動態路由,它的級別是200,所以ISDN備份的動態路由級別要大於200,級別越大優先權越低。
策略路由在主站和小站之間都不是不須的,為了使配置易於理解,建議配置策略路由。
在BGP發出握手請求時,要有一條路由到達對方路由器,我們的配置中使用默認路由到達DBN24 (如果沒有默認路由必須增加到對方環路地址的靜態路有),所以在DBN24上要添加到對方(遠程小站路由器)環路地址的靜態路由。
遠程小站路由器也必須配置一條到達主站環路地址的靜態路由(如果小站沒有默認路由)。
二、配置
路由器中建立環路地址:
Interface loopbackup 0
Ip address 172.31.254.1 255.255.255.0
路由器中建立BGP 自治域:
Router bgp 65500
Network 172.16.5.0 mask 255.255.255.0 (本地網路)
Network 172.16.6.0 mask 255.255.255.0 (本地網路)
Neighbor 172.25.10.1 remote-as 65500 (使鄰居在同一個自治域)
Neighbor 172.25.10.1 update-source loopback0(設定鄰居更新在環路接口0)
Neighbor 172.25.10.1 route-map jinhua in (使用策略路由)
策略路由樣例:
route-map jinhua permit 5
macth ip address 30
set ip next-hop 172.16.5.200
策略路由觀察的訪問列表:
access-list 30 permit ip 172.19.10.0 0.0.0.255
三、容易忽略的地方及問題
1、容易忽略的地方是:在路由器中有了路由,因為路由是到dbn24的,所以不能忘了在dbn24中的各遠程點路由部分增加到對方環路地址的路由。
2、問題1:bgp中的network地址指的是什麼地址?
答 :network地址指的是與鄰居網絡能建立通信的地址,在本網路中指本地兩個網段地址。
3、問題2:為什麼鄰居與本地網路必須配置在同一個自治域內?
答:不在一個自治域的路由器必須是直接相聯的才可以互相通信。
4、問題3:路由表中配置了默認路由,同時還有浮動靜態ISDN路由,級別是201,那么靜態路由比默認路由級別高,為什麼在建立TCP會話中不使用浮動靜態路由,而使用默認路由。
答:因為在BGP建立握手時,它尋找的目標地址是對方的環路地址,而ISDN的目標地址是對方的以太口地址,所以建立TCP握手使用默認路由(也可以設定一條指向對方環路地址的靜態路由,級別明顯高於ISDN路由,易於理解)。BGP建立動態路由的級別是200,在建立TCP握手後,它生成的路由表也是指向對方以太口地址,但它的優先權高於ISDN設定的路由級別201,而禁止ISDN路由生效,如果不能建立起指向對方以太口的BGP動態路由,那么在主站與小站的連線時,就是啟用ISDN路由,引起ISDN撥號。
5、問題4:為什麼配置串口的時候,必須加上ignore-dcd、no keepalive、ip igmp unidirectional-link、ip multicast ttl-threshold 14、ip pim dense-mode、ip igmp static-group 239.16.5.144。
答:因為在衛星鏈路中路由器串口不傳送cd信號必須忽略,keepalive是指第二層的保持活動協定,如果讓keepalive生效,那么它將監測某一鏈路的第二層雙向是否保持活動,由於衛星鏈路在串口是單向的(小站指向主站),它將會是串口down掉,ip igmp unidirectional-link標示串口是單向鏈路,ip multicast ttl-threshold 14標示讓小站的組播包的默認ttl-threshold為14,而讓小站的組播包不至於未到主站就被丟失,也不能設大於14的值。ip pim dense-mode啟用協定無關組播協定,ip igmp static-group 239.16.5.144標示小站的路由器加入239.16.5.144組播組。
四、BGP是否生效查詢
1、使用命令:show ip bgp neighbors 查詢bgp 狀態。(注意黑體)
tongji#sh ip bgp neighbors
BGP neighbor is 172.25.10.1, remote AS 65500, internal link
BGP version 4, remote router ID 172.25.10.1
BGP state = Established, up for 00:41:10
Last read 00:00:11, hold time is 180, keepalive interval is 60 seconds
Neighbor capabilities:
Route refresh: advertised and received(new)
Address family IPv4 Unicast: advertised and received
Received 1763 messages, 0 notifications, 0 in queue
Sent 1766 messages, 0 notifications, 0 in queue
Route refresh request: received 0, sent 0
Default minimum time between advertisement runs is 5 seconds
For address family: IPv4 Unicast
BGP table version 4, neighbor version 4
Index 1, Offset 0, Mask 0x2
1 accepted prefixes consume 36 bytes
Prefix advertised 6, suppressed 0, withdrawn 2
Number of NLRIs in the update sent: max 2, min 0
Connections established 3; dropped 2
Last reset 00:41:43, due to User reset
Connection state is ESTAB, I/O status: 1, unread input bytes: 0
Local host: 172.31.254.1, Local port: 179
Foreign host: 172.25.10.1, Foreign port: 11045
Enqueued packets for retransmit: 0, input: 0 mis-ordered: 0 (0 bytes)
Event Timers (current time is 0x644BFAC):
Timer Starts Wakeups Next
Retrans 48 1 0x0
TimeWait 0 0 0x0
AckHold 45 39 0x0
SendWnd 0 0 0x0
KeepAlive 0 0 0x0
GiveUp 0 0 0x0
PmtuAger 0 0 0x0
DeadWait 0 0 0x0
iss: 1548750689 snduna: 1548751630 sndnxt: 1548751630 sndwnd: 15985
irs: 127891366 rcvnxt: 127892303 rcvwnd: 15985 delrcvwnd: 399
SRTT: 771 ms, RTTO: 806 ms, RTV: 35 ms, KRTT: 0 ms
minRTT: 568 ms, maxRTT: 1032 ms, ACK hold: 200 ms
Flags: passive open, nagle, gen tcbs
Datagrams (max data segment is 536 bytes):
Rcvd: 90 (out of order: 0), with data: 45, total data bytes: 936
Sent: 87 (retransmit: 1, fastretransmit: 0), with data: 46, total data bytes: 940
2、使用命令:show ip route (注意黑體)
tongji#sh ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF nssa external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static route
Gateway of last resort is 172.16.5.200 to network 0.0.0.0
172.16.0.0/24 is subnetted, 7 subnets
C 172.16.4.0 is directly connected, FastEthernet0/0.4
C 172.16.5.0 is directly connected, FastEthernet0/0.5
C 172.16.6.0 is directly connected, FastEthernet0/0.6
C 172.16.1.0 is directly connected, FastEthernet0/0.1
C 172.16.2.0 is directly connected, FastEthernet0/0.2
C 172.16.3.0 is directly connected, FastEthernet0/0.3
S 172.16.100.0 [1/0] via 172.16.5.200
172.19.0.0/16 is variably subnetted, 11 subnets, 2 masks
B 172.19.10.0/24 [200/0] via 172.25.10.1, 00:57:53
C 172.19.101.24/30 is directly connected, Serial4/2
C 172.19.101.28/30 is directly connected, Serial4/3
C 172.19.101.16/30 is directly connected, Serial4/0
C 172.19.101.20/30 is directly connected, Serial4/1
C 172.19.101.8/30 is directly connected, Serial3/2
C 172.19.101.12/30 is directly connected, Serial3/3
C 172.19.101.0/30 is directly connected, Serial3/0
C 172.19.101.4/30 is directly connected, Serial3/1
C 172.19.101.32/30 is directly connected, Serial5/0
C 172.19.101.36/30 is directly connected, Serial5/1
172.20.0.0/24 is subnetted, 1 subnets
S 172.20.2.0 [1/0] via 10.0.20.2
172.31.0.0/24 is subnetted, 1 subnets
C 172.31.254.0 is directly connected, Loopback0
203.91.153.0/29 is subnetted, 1 subnets
C 203.91.153.240 is directly connected, FastEthernet0/0.5
210.74.232.0/32 is subnetted, 1 subnets
S 210.74.232.178 [1/0] via 172.16.1.28
10.0.0.0/24 is subnetted, 2 subnets
C 10.0.20.0 is directly connected, Dialer20
C 10.0.254.0 is directly connected, Dialer10
S* 0.0.0.0/0 [1/0] via 172.16.5.200
S 192.168.0.0/16 [1/0] via 172.16.1.253
S 202.120.176.0/20 [1/0] via 172.16.1.253
3、 更改bgp後,必須更新,使用命令:
clear ip bgp *
國內知名的BGP機房
1.鄭州BGP機房
機房性質:景安網路自建自營
機房位置:鄭州市經開第五大街經北三路河南通信產業園二樓西
景安網路鄭州BGP機房總面積6600平米,擁有獨立自治域及4B的IP位址,移動、聯通、電信、鐵通等多線路接入,總出口規模超過40G,為全國30萬網站提供接入服務,全國單個機房接入網站數量第一。
2.兆維機房
機房性質:電信五星級IDC機房,通過ISO27001信息安全體系認證
機房位置:北京市朝陽區酒仙橋路14號兆維工業園區D區1樓2門3層
3.數字北京機房
機房性質:聯通5A級機房北京重要的核心機房
機房位置:作為2008年奧運標誌性建築之一的數字北京大廈,位於奧體中心核心區,水立方北側。
4.北京國門機房
機房性質:IBM團隊自建自營
機房位置:位於北京市朝陽區三元橋國門商務大廈,機房總面積:5000平米,抗靜電地板600mm,抗震強度高達8級,承重能力每平方米1000公斤。
相關辭彙
網路協定
| 網路上的計算機之間又是如何交換信息的呢?就像我們說話用某種語言一樣,在網路上的各台計算機之間也有一種語言,這就是網路協定,不同的計算機之間必須使用相同的網路協定才能進行通信。 |
