統計模式識別
正文
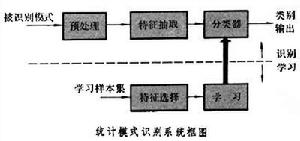 對模式的統計分類方法,即把模式類看成是用某個隨機向量實現的集合,又稱為決策理論識別方法(見模式識別)。屬於同一類別的各個模式之間的差異,部分是由環境噪聲和感測器的性質所引起的,部分是模式本身所具有的隨機性質。前者如紙的質量、墨水、污點對書寫字元的影響;後者表現為同一個人書寫同一字元時,雖形狀相似,但不可能完全一樣。因此當用特徵向量來表示這些在形狀上稍有差異的字元時,同這些特徵向量 對應的特徵空間中的點便不同一,而是分布在特徵空間的某個區域中。這個區域就可以用來表示該隨機向量實現的集合。假使在特徵空間中規定某種距離度量,從直觀上看,兩點之間的距離越小,它們所對應的模式就越相似。在理想的情況下,不同類的兩個模式之間的距離要大於同一類的兩個模式之間的距離,同一類的兩點間連線線上各點所對應的模式應屬於同一類。一個畸變不大的模式所對應的點應緊鄰沒有畸變時該模式所對應的點。在這些條件下,可以準確地把特徵空間劃分為同各個類別相對應的區域。在不滿足上述條件時,可以對每個特徵向量估計其屬於某一類的機率,而把有最大機率值的那一類作為該點所屬的類別。統計模式識別方法就是用給定的有限數量樣本集,在已知研究對象統計模型或已知判別函式類條件下根據一定的準則通過學習算法把d 維特徵空間劃分為c個區域,每一個區域與每一類別相對應。模式識別系統在進行工作時只要判斷被識別的對象落入哪一個區域,就能確定出它所屬的類別。由噪聲和感測器所引起的變異性,可通過預處理而部分消除;而模式本身固有的變異性則可通過特徵抽取和特徵選擇得到控制,儘可能地使模式在該特徵空間中的分布滿足上述理想條件。因此一個統計模式識別系統應包含預處理、特徵抽取、分類器等部分(見圖)。
對模式的統計分類方法,即把模式類看成是用某個隨機向量實現的集合,又稱為決策理論識別方法(見模式識別)。屬於同一類別的各個模式之間的差異,部分是由環境噪聲和感測器的性質所引起的,部分是模式本身所具有的隨機性質。前者如紙的質量、墨水、污點對書寫字元的影響;後者表現為同一個人書寫同一字元時,雖形狀相似,但不可能完全一樣。因此當用特徵向量來表示這些在形狀上稍有差異的字元時,同這些特徵向量 對應的特徵空間中的點便不同一,而是分布在特徵空間的某個區域中。這個區域就可以用來表示該隨機向量實現的集合。假使在特徵空間中規定某種距離度量,從直觀上看,兩點之間的距離越小,它們所對應的模式就越相似。在理想的情況下,不同類的兩個模式之間的距離要大於同一類的兩個模式之間的距離,同一類的兩點間連線線上各點所對應的模式應屬於同一類。一個畸變不大的模式所對應的點應緊鄰沒有畸變時該模式所對應的點。在這些條件下,可以準確地把特徵空間劃分為同各個類別相對應的區域。在不滿足上述條件時,可以對每個特徵向量估計其屬於某一類的機率,而把有最大機率值的那一類作為該點所屬的類別。統計模式識別方法就是用給定的有限數量樣本集,在已知研究對象統計模型或已知判別函式類條件下根據一定的準則通過學習算法把d 維特徵空間劃分為c個區域,每一個區域與每一類別相對應。模式識別系統在進行工作時只要判斷被識別的對象落入哪一個區域,就能確定出它所屬的類別。由噪聲和感測器所引起的變異性,可通過預處理而部分消除;而模式本身固有的變異性則可通過特徵抽取和特徵選擇得到控制,儘可能地使模式在該特徵空間中的分布滿足上述理想條件。因此一個統計模式識別系統應包含預處理、特徵抽取、分類器等部分(見圖)。 分類器有多種設計方法,如貝葉斯分類器、樹分類器、線性判別函式、近鄰法分類、最小距離分類、聚類分析等。
參考書目
C.H.Chen, Statistical Pattern Recognition,Hayden(Sparton Books), New York,1973.
K.Fukunaga,Introduction to Statistical Pattern Recognition,Academic Press, New York,1972.
S.Watanabe,ed.,Methodologies of Pattern Recognition,Academic Press, New York, 1969.
