
簡介
訊息用從一個對象的生命線到另一個對象生命線的箭頭表示。箭頭以時間順序在圖中從上到下排列。
 順序圖
順序圖和合作圖、活動圖一樣,UML順序圖( Rumbaugh、Jacobson、和booch, 1999)是一種動態建模方法。 UML順序圖一般用於:確認和豐富一個使用情境的邏輯。一個使用情境就是系統潛在的使用方式的描述,也就是它的名稱所要描述的。一個使用情境的邏輯可能是一個用例的一部分,或是一條備選線路;一個貫穿單個用例的完整流程,例如動作基本過程的邏輯描述,或是動作的基本過程的一部分再加上一個或多個的備用情境的邏輯描述。或是包含在幾個用例中的流程,例如一個學生註冊入學之後,立即就要在三個班級註冊。
研究你的設計,因為它們為你提供了一種方式,你可以使用這種方式來可視化的調用類定義的操作。檢測面向對象的設計中的瓶頸。 通過觀察什麼訊息被傳送給一個對象,以及通過概略的觀察運行被調用的方法需要花費多長時間,你很快就能了解那裡的設計需要變化,以達到在系統內部平衡負荷的目的。 實際上某些CASE工具甚至能夠讓你模擬軟體這些特徵。
使你能夠感覺到你的應用程式的那個類將會變得複雜的,這是個信號,意味著你需要為那些類畫狀態圖了。
準則
 順序圖
順序圖盡力保持訊息的順序是從左到右排列的。
一個順序圖的訊息流開始於左上方,訊息乙的位置比訊息甲低,這意味著訊息乙的順序比訊息甲要遲。因為西方的閱讀習慣是從左到右,你應該儘量按照和描述訊息流一樣的方式,從左至右排列分類器(角色、類、對象,和用例)。 在圖1中你可以看到分類器已經按照這種方式排列好了,如果Seminar對象在controller的左邊,那排列方式就不是標準的了。 注意有時候訊息流從左到右的排列是不可能的,例如一對對象彼此調用操作的情形。
分類器
分層是一個通用的面向對象設計的方法,系統通常來說,總是組織成user interface、process/controller、business、persistence、和system層( Ambler 2001)。 當系統是以這種方式設計的時候,通常會加強同屬於一層的分類器合作,而降低不同層的分類器的耦合度。 因此按類似的方式對你的順序圖進行分層是有意義的。 就這個使用情境的例子來說,一種分層的方法就是先註明人類角色,然後是表示情境的邏輯的controller類,然後是user interface類,接著是business類,最後是相關的技術類,它封裝了對資料庫和系統資源的訪問。 以這種方式對你的順序圖分層,會使得順序圖更容易閱讀,也更容易發現分層的邏輯問題。 圖1就採取這種方法。
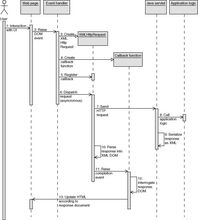
圖⒈一次學生的註冊。
用和你的用例圖一致的名稱命名角色。
 順序圖
順序圖當你在對一個使用情境建模時,你的順序圖一般會涉及一個或多個角色。 為了保持一致性,顯示在順序圖中的角色的名稱應該和用例圖上的相同。
用和你的類圖一致的名稱命名類。
順序圖中的類和類圖中的類是相同的,因此它們應該有相同的名稱。
一個角色的名稱可以和類的名稱相同。
在圖1你可以看到一個命名為學生的角色和一個命名為學生的類。 這樣做是合理的,因為這兩個分類器表示兩個不同的概念,角色表示在現實中的學生,而類則表示你正在構建的商業應用程式中的學生。
包含一個邏輯的敘述性描述。
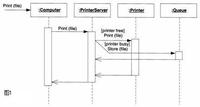
圖1可以很難理解--特別是對於不熟悉閱讀順序圖人來說--因為它是很接近於實際的源程式。 在你模型中包含一個業務邏輯的描述是很常見的,特別當該順序圖描述一個使用情境時,就像在在圖⒉的左邊看到的,這可以增加圖的可理解性,並且Rosenberg和Scott(1999)指出,這也為跟蹤用例和順序圖間的信息提供了重要的信息。
圖⒉線上定單付款。
在圖的最左邊放置人和組織角色。
對業務套用軟體來說,在大多數的中,主要的角色是一個人或一個組織。這些角色經常是該情境的發起人,同時也是順序圖的閱讀焦點,因此它們應該放在模型的"可看見的開始之處"。
在圖的最右邊放置反應系統角色。
反應系統角色是那些你與之互動的系統,應該放在圖的最右邊。因為在許多的業務套用軟體中,這些角色經常被當做" backend entities ",也就是那些你的系統通過存取技術互動的系統,例如C APIs、CORBAIDL、訊息佇列、或web service。 換句話說,把後端的系統放在圖最後的位置。
在圖的最左邊放置系統角色。
先導系統角色是那些與你的系統互動的系統,根據力爭從左到右排列訊息和分類器層的原則,應該放在圖的最左邊。
建模對象
雖然記憶體管理是很重要的的問題,特別是對象在適當的時候的銷毀,許多建模者不願意在順序圖上建模對象的銷毀操作,而是在activation條(就是表示對象生命周期的那個豎條)的底部使用一個"X"符號,或使用一個帶<>版型的訊息。 比較圖1和圖2,注意圖1中引入了對象的銷毀,沒帶來明顯的好處,卻弄亂了圖的布局。而圖2則沒有註明對象銷毀。 記住遵循敏捷建模(AM)的實踐簡單的描述模型。
這項指南的意義在於兩個理由∶ 首先,很多種語言都擁有稱作垃圾收集的技術,實現自動的記憶體管理,例如Java和Smalltalk。 其次,在那些你需要明確的管理記憶體的語言中,例如C++,你的程式設計師一般地都能夠了解該怎么做,並不需要模型中的這些附加信息。
注意在實時系統中,記憶體管理通常是一個關鍵性問題,你可能需要建模對象的銷毀操作。
原則
注意∶分類器命名規則的在別處描述。 其中,類和接口的命名規則在UML類圖的風格指南中描述,用例的命名規則在UML用例圖的風格指南中描述,而組件的命名規則在UML組件圖的風格指南中描述。
 順序圖
順序圖當你在訊息上引用對象時要命名他們。
順序圖上的對象應使用標準的UML格式" name: ClassName "來標記,其中" name "可選的(擁有一個名稱的對象稱作已命名的對象,而那些沒有名稱的對象則被稱作匿名對象)。在圖1中,Student的實例以theStudent來命名,因為它是一條訊息已引用返回值,然而SecurityLogon類的實例則不需要名稱,因為圖的其它地方並沒有套用它,因此它可以使匿名的。
當存在部分相同的類型時需要命名對象。
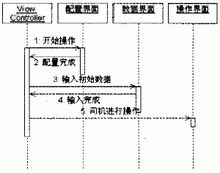
當一個順序圖包含幾個同樣類型的對象時,例如圖3存在兩個Account類的實例,你應該為該類型的所有對象命名,以避免圖的意義含糊不清。
圖⒊在賬戶間轉帳。
一致地套用文本版型。
表1總結了一些通用版型,你可以在順序圖的分類器上套用它們。 不要花過多的時間來爭論應該使用哪個版型,例如<>和<>都是不錯的版型,只要隨便選擇一個並保證一致性就好了。
表⒈通用的版型.
版型 用法
<> 在設計期間表示微軟的Active Server Page。
<> 在設計期間用於註明一個組件。
<> 用來註明一個控制器類,實現了和使用情境有關的業務邏輯,或包括幾個業務類的邏輯。
<> 設計期間表示一個圖形用戶界面螢幕。
<> 設計期間表示一個超文本頁。
<> 設計期間表示一個Java接口
<> 設計期間表示一個Java Server Page。
<> 設計期間表示一個列印的或電子的報告。
<> 表示系統角色。
<> 一個一般的用戶界面類。 一般使用在分析級的圖上,此時你尚未決定使用何種的實現平台。
少量地套用可視化的版型。
在你的順序圖上套用可視化的版型時完全正確的,就如同你在圖2和圖3所見的,但它並非一個十分通用的慣例,因此它可能會減少圖的可理解性。 在圖2中,顧客是一個角色(使用與用例圖相同的符號),OrderCheckout是一個控制器類,CheckoutPage是一個用戶界面類,而Order是一個業務實體類。
注意,那些需要開發穩定性較高的圖的團隊會使用可視化的版型Rosenberg & Scott 1999; Ambler 2002),就像在圖2描繪的可視化的版型一樣,因此對項目中的所有人都必須熟悉這些符號。
集中在關鍵的互動。
AM的實踐--創建簡單內容建議,當創建一個模型時,你應當集中於系統的關鍵性特徵,而不要包含無關的細節。 因此,如果順序圖是探究業務邏輯的,你就不要包含對象和資料庫的具體互動,諸如save ()和delete ()的操作就已經足夠了,你可以簡單地假定持久性已經能夠處理,而不需要去理會細節。 例如,在圖2中,你看不到從資料庫或對象快取中讀取orders和order items的任何邏輯,只是他們會在適當點發生而已。 你也看不到CreditCardPayment類連線到payment處理器的邏輯,但這個邏輯是必定會發生的。 只把注意力集中在和你正在建模的東西相關的關鍵性互動上,你可以在儘可能的保持圖的簡單的同時達到目的,不但提高了建模者的生產力,也增加了圖的可讀性。
注意∶操作符號的命名規則,和訊息、參數、返回值的命名有關的原則都在UML類圖的風格指南中描述。
把訊息名放在箭頭旁邊。
大多數的建模者都會調整訊息名,例如圖2中的calculateTotal (),因此訊息名總是靠近箭頭的。 一般我們認為訊息的接受者將會實現相應的操作,因此把訊息名放在離分類器接近的位置是有意義的。
注意,圖3並沒有遵循這些原則,所有的訊息名都排列在接近傳送者的地方。 這種方法的優點在於它很容易看出欲建模的情境的邏輯,而且,如果你使用了清楚的訊息和參數名稱,那你也許可以不用遵循包含邏輯的敘述性描述的原則。而這種方法的缺點是很難判斷哪個操作是被圖右方的分類器所調用的。 象往常一樣,選擇一種方法並一致的套用它。
類型
有時參數傳遞的信息和你正在建模的信息並沒有什麼關係,雖然這些信息對你而言非常的重要。 在這種情況下就需要註明參數的類型,如圖3中的start ( UserID)。
原則
當返回值非常明顯時就不要對返回值建模。
返回值的顯示是使用帶返回值標記的虛線箭頭,返回值是可選的。 例如,圖1中返回值theStudent表示了對SecurityLogon類調用的訊息的返回值,然而圖2中對order傳送getTotal ()訊息就沒有返回值。 在第一個例子中,創建一個security logon對象會產生一個student對象,這是不明顯的,然而向order要求一個小計的返回值是很明顯的。
只有當你需要在別處引用返回值時才對返回值建模。
如果你需要在順序圖的另一處(一般是作為參數傳遞給另一個訊息)引用返回值,那就需要在圖中著名返回值,這樣就能清楚的表明它的出處。
在箭頭旁邊調整返回值。
大多數的建模者都會把返回值放在靠近箭頭地方,例如圖2中的theStudent。 一般我們認為返回值的接受者將會使用返回值,因此把返回值放在靠近分類器的位置是有意義的。
返回值建模為方法調用的一部分。
不要使用虛線來弄亂順序圖,考慮在訊息名上註明返回值來替代虛線。使用符號message ( parameters) : returnValue,圖2就使用了這種符號:reserve () : AuthorizationCode。用這個方法,你只會有單條訊息路線,而不會有一條訊息路線和一條返回值路線。
注類型
有時返回值傳遞的信息和你的模型並沒有什麼關係,儘管這些信息對你而言非常的重要。 在這種情況下就需要註明參數的類型,如圖2中的reserve () : AuthorizationCode。
實際值
圖1中isValid () message返回了值yes,這就清楚的表明了該學生的名稱和編號是合法的。如果返回值命名為Boolean,就只是註明回應的類型,如果命名為eligibilityIndicator,就只是註明了返回值的名稱,這樣就不夠明確了。
