
功能
集成組件
UIMA 架構允許您輕鬆插入定製的分析組件,並將它們與其他組件合併。您的 UIMA 應用程式不需要知道分析組件共同合作生成結果的細節。集成和組織多個分析組件是 UIMA 框架的工作。
識別
UIMA 應用程式可能分析純文本並識別人員、位置和組織;它也可能識別關係,比如為誰工作或在什麼地方工作。應用程式通常可以拆分成組件。例如 “語言識別” => “特定於語言的部分” => “句子範圍檢測” => “實體檢測(人員/位置的名稱等等)”。
組件之間可能存在依賴性。例如,“句子範圍檢測” 必須先於 “特定於語言的部分”。 每個組件都是自含的並且可以與其他組件組合。每個組件(用 Java 或 C++ 編寫)實現由其他框架定義的接口,並通過 XML 描述符檔案提供自我描述元數據。UIMA 框架管理組件和在它們之間流動的數據。分析引擎、注釋器和 Common Analysis Structure 分析引擎 是 UIMA 中的中央構建塊。分析引擎包含一個或多個 注釋器 或其他分析引擎。每個注釋器實現一個特定的文本分析功能。這種遞歸式打包允許您通過簡單的分析引擎構建複雜的分析引擎。每個注釋器將其結果儲存在具有類型的 特徵結構 中,該結構僅是包含類型和一組屬性/值對的數據結構。
注釋 是一種特殊的特徵結構,它被附加到需要分析的工件的某個區域。例如,注釋可能被附加到文檔中的一段文本上。對於這種情況,注釋在文檔中包含一個特定的開始和結束位置。這意味著可以方便地使用注釋指定信息提取結果。例如,在以下文本中,Company 注釋覆蓋的位置是從 19 到 21:
UIMA started as an IBM initiative, but has gone open source in 2008所有特徵結構(包括注釋)都用 UIMA Common Analysis Structure (CAS) 表示,CAS 是中央數據結構,所有 UIMA 組件都通過它進行通信。
圖 1 顯示一個包含用於已命名實體識別、語法分析和關係探測的注釋器的分析引擎。注意,Relationship Annotator 通過分析在 CAS 中預先存在的概念和語法注釋探測關係,而不需要查看實際的文檔文本。
圖 1. 包含用於已命名實體識別、語法分析和關係探測的注釋器的文本分析引擎
類型
UIMA 類型系統 定義能夠在文檔中找到並且能夠被分析引擎提取的各種對象的類型。例如,Person 就是一個類型。
類型包括 特徵。例如 Age 和 Occupation 可能被定義為 Person 類型的特徵。類型的例子還有 Organization、Company、Money、Product 或 NounPhrase。
類型系統特定於領域和特定於應用程式。您可以將類型併入到不同的類中。例如 Company 可以定義為 Organization 的子類型,或 NounPhrase 可以定義為 ParseNode 的子類型。
在文本分析中,用於派生其他類型的概括性的通用類型被稱為 Annotation 類型,它由 UIMA 框架提供。您可以使用 Annotation 類型在文檔中標記區域。Annotation 類型包含 Begin 和 End 特徵,這些特徵的值將確定一個跨段。例如,在以下文本字元串(與圖 1 分析的字元串一樣)中,注釋 Person 從位置 0 開始在位置 10 結束:
Fred Center is the CEO of Center Micros
開發注釋器的第一步是定義需要使用的 CAS Feature Structure 類型。這在一個稱為 Type System Descriptor 的 XML 檔案中完成。UIMA 定義內置類型 TOP(它是類型系統的根,類似於 Java 中的 Object)和以上描述的 Annotation 等。UIMA 還為 Boolean、Integer 和 Double 等特徵定義基礎範圍類型,並為執行原始類型定義數組。
Processing Engine ARchives (PEAR) 檔案
開發並成功測試了分析引擎之後,您可以打包它並將其作為預配置(文本)分析組件部署到另一個應用程式中。在 UIMA 中,一種注釋器打包格式稱為 PEAR,它是 Processing Engine ARchive 的縮寫。PEAR 格式包含運行打包注釋器組件所需的所有信息。要詳細了解 PEAR 打包格式,請查看 UIMA 參考文檔的 PEAR Reference 章節。
通過在 InfoSphere Warehouse Design Studio 中使用 Text Analyzer 操作器,您可以導入任何 Apache UIMA 支持的分析引擎,以注釋非結構化文本中的概念。使用 Analysis Engine Import 嚮導可以導入這些預配置的 PEAR 檔案。對於使用以前的 UIMA 版本(比如 IBM UIMA)創建的分析引擎,首先要遷移它。本文的下一小節將描述遷移過程。
UIMA 和 InfoSphere Warehouse
如前面小節所述,您可以將預配置的 UIMA 分析引擎(PEAR 檔案)導入到 InfoSphere Warehouse 中。這允許您擴展 InfoSphere Warehouse 的文本分析功能,以滿足特定的需求。
本文概述如何在資料庫中表示由分析引擎創建的文本分析結果。此外,還解釋了如何使用 InfoSphere Warehouse 導入並執行使用以前版本的 UIMA 創建的文本分析引擎。
將分析結果映射到資料庫的列上
在 InfoSphere Warehouse 中,分析非結構化數據要求該數據作為列儲存在資料庫中,並且使用的字元數據類型為 CHAR、VARCHAR 或 CLOB。UIMA 將每個表行的特定文本列內容作為一個文本文檔處理。
生成的分析結果(都來自 Annotation 類型)存儲在 CAS 中。通過 CAS Consumer 將選擇的結果的內容寫入到使用 JDBC 的資料庫中。每個選擇的特徵都儲存在一個新列中。
為了指定應該將哪個分析結果寫入到資料庫,您應該配置 Text Analyzer 操作器的屬性,具體而言,就是配置 Analysis Results 選項卡。使用這個選項卡指定哪個注釋類型包含分析結果(例如,類型 Company)。
如前所述,每個注釋都包含 Begin 和 End 等特徵,同時也可以包含自定義特徵,比如 Company 類型的 Full_Legal_Name 或 CEO。 選擇的注釋類型指定您感興趣的結果,而該注釋類型中選擇的特徵指定感興趣的細節部分。每個特徵都存儲在一個資料庫列中。
最終生成的資料庫表不一定要包含從分析創建的列。它也可以包含來自輸入表的列。這允許您在隨後,例如,將結果與原始文本關聯起來。
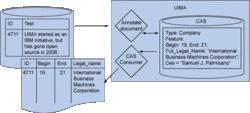
圖 2 總結了這個流程。在圖中可以看到,Text Analyzer 操作器的 Analysis Result 選項卡配置 CAS Consumer,以將 Begin、End 和 Full_Legal_Name 特徵的內容寫到結果表中。
圖 2. 分析文本列並將分析結果寫到表中的 UIMA 流
 UIMA
UIMA 如果 UIMA 注釋器的結果大於它們映射到的結果列,那么可能出現難以識別的問題。例如,如果列的類型為 VARCHAR(256),大於 256 個字元的結果將導致失敗的流和 SQL 錯誤。識別該問題的簡易方法是臨時使用 CLOB 類型作為目標列,它沒有任何大小限制。 如果這能夠解決該問題,那么注釋器將返回一個比較長的返回值。在注釋器代碼中確保創建注釋時不超過特定長度是非常有用的。如果沒有可用的特定長度的 DB2 表空間,可能會導致另一個問題。
將基於 IBM UIMA 的分析引擎遷移到 Apache
InfoSphere Warehouse V9.5.1 和更新版本不支持基於 IBM UIMA 的打包文本分析組件。不過,通過遵循以下步驟之一,您就可以在這些版本中使用提到的組件:
使用 IBM UIMA 到 Apache UIMA 的轉換工具遷移 PEAR 檔案的原始碼。要了解更多信息,請在 UIMA Web 站點上查看 Migrating from IBM UIMA to Apache UIMA 部分。 使用 IBM UIMA Adapter Wrapper for Apache UIMA 在基於 Apache UIMA 的運行時環境中運行基於 IBM UIMA 的 PEAR 檔案。當沒有可以用 IBM UIMA 到 Apache UIMA 轉換工具轉換的原始碼時,您可以對基於 IBM UIMA 的解釋器使用 IBM UIMA Adapter 包。要處理這些 IBM UIMA 解釋器,請在新的 Apache UIMA 運行時中使用 IBM UIMA Adapter 包。要了解更多信息,請訪問 alphaWorks 上的 UIMA 頁面。 通過開啟 InfoSphere Warehouse 中的 UIMA 日誌識別問題
InfoSphere Warehouse 將在注釋器代碼中發生的錯誤訊息轉發到執行分析流跟蹤中。如果您對流程、數據流或挖掘流啟用內容跟蹤,那么 CONFIG 級別和該級別以上的 UIMA 日誌將路由到 InfoSphere Warehousing 日誌。
在某些情況下,有必要從更細的級別獲取 UIMA 日誌訊息來調試注釋器的問題。這將涵蓋在注釋器的 UIMA 代碼中發生的問題,以及在定製注釋器的注釋器代碼中發生的問題。查看 InfoSphere Warehouse 文檔 了解如何查看挖掘流或數據流的 UIMA 日誌,以及如果更改 UIMA 跟蹤級別獲得更多信息。
通過開啟 InfoSphere Warehouse 中的 UIMA 日誌識別問題
InfoSphere Warehouse 將在注釋器代碼中發生的錯誤訊息轉發到執行分析流跟蹤中。如果您對流程、數據流或挖掘流啟用內容跟蹤,那么 CONFIG 級別和該級別以上的 UIMA 日誌將路由到 InfoSphere Warehousing 日誌。
在某些情況下,有必要從更細的級別獲取 UIMA 日誌訊息來調試注釋器的問題。這將涵蓋在注釋器的 UIMA 代碼中發生的問題,以及在定製注釋器的注釋器代碼中發生的問題。查看 InfoSphere Warehouse 文檔 了解如何查看挖掘流或數據流的 UIMA 日誌,以及如果更改 UIMA 跟蹤級別獲得更多信息。
