系統辨識
正文
根據系統的輸入輸出時間函式來確定描述系統行為的數學模型,是現代控制理論中的一個分支。對系統進行分析的主要問題是根據輸入時間函式和系統的特性來確定輸出信號。對系統進行控制的主要問題是根據系統的特性設計控制輸入,使輸出滿足預先規定的要求。而系統辨識所研究的問題恰好是這些問題的逆問題。通常,預先給定一個模型類M={M}(即給定一類已知結構的模型),一類輸入信號u和等價準則J=L(y,yM)(一般情況下,J是誤差函式,是過程輸出y和模型輸出yM的一個泛函)。然後選擇使誤差函式J達到最小的模型,作為辨識所要求的結果。系統辨識包括兩個方面:結構辨識和參數估計。對於一個實際套用領域,要找到系統的合適的模型往往是很困難的,特別是結構的選擇,它主要取決於對系統已有的知識和套用模型的目的。由於套用領域的多樣性,結構的選擇很難有一般的規則可循。此外,有時也利用系統的輸入輸出來辨識模型的結構,特別是在已知系統是線性的情況下,模型的階或結構指標是通過辨識來得到的。如果模型的結構已知,辨識剩下的問題就是參數估計,即通過實驗數據確定模型中的未知參數。之所以用“估計”,是因為對於幾乎所有實際情形,實驗數據總是有誤差的。因此參數估計必須使用統計方法才能得到良好的結果。在實際的辨識過程中,隨著使用的方法不同,結構辨識和參數估計這兩個方面並不是截然分開的,而是可以交織在一起進行的。辨識的目的 在提出和解決一個辨識問題時,明確最終使用模型的目的是至關重要的。它對模型類(模型結構)、輸入信號和等價準則的選擇都有很大的影響。通過辨識建立數學模型通常有四個目的。
①估計具有特定物理意義的參數 有些表征系統行為的重要參數是難以直接測量的,例如在生理、生態、環境、經濟等系統中就常有這種情況。這就需要通過能觀測到的輸入輸出數據,用辨識的方法去估計那些參數。
②仿真 仿真的核心是要建立一個能模仿真實系統行為的模型。用於系統分析的仿真模型要求能真實反映系統的特性。用於系統設計的仿真,則強調設計參數能正確地符合它本身的物理意義。
③預測 這是辨識的一個重要套用方面,其目的是用迄今為止系統的可測量的輸入和輸出去預測系統輸出的未來的演變。例如最常見的氣象預報,洪水預報,其他如太陽黑子預報,市場價格的預測,河流污染物含量的預測等。預測模型辨識的等價準則主要是使預測誤差平方和最小。只要預測誤差小就是好的預測模型,對模型的結構及參數則很少再有其他要求。這時辨識的準則和模型套用的目的是一致的,因此可以得到較好的預測模型。
④控制 為了設計控制系統就需要知道描述系統動態特性的數學模型,建立這些模型的目的在於設計控制器。建立什麼樣的模型合適,取決於設計的方法和準備採用的控制策略。
辨識的基本步驟 下圖說明系統辨識過程主要步驟的流程。
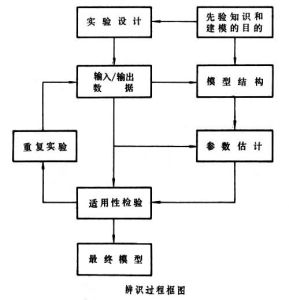 系統辨識
系統辨識其次,建模的目的對於確定模型的結構和辨識方法也有重要意義。用於不同目的的模型可能會有很大的差別。在估計具有特定物理意義的參數時,主要考慮模型的參數值與真實的參數值是否一致。在建立預測模型時,只需要考慮預測誤差。在建立仿真模型時,就要根據套用的要求去決定仿真的深度,也就是決定模型結構的複雜程度。而對於設計控制系統的模型,則出於不同的控制目的可選擇不同的模型類。
實驗設計 辨識的基礎是輸入和輸出數據,而數據來源於對系統的實驗和觀測,因此辨識歸根到底是從數據中提取有關係統的信息的過程,其結果是和實驗直接聯繫在一起的。設計實驗的目標之一是要使所得到的數據能包含系統的更多的信息。為此,首先要確定用什麼準則來比較數據的好壞。這種準則可以是從辨識的可行性出發的,也可以是從某種最優性原則出發的。實驗設計要解決的問題主要是:輸入信號的設計,採樣區間的設計,預採樣濾波器的設計等(見系統辨識實驗設計)。
模型結構 辨識中的模型結構是指辨識問題中所選擇的模型類中的數學模型M 的具體表達形式,例如一般的動態模型
除線性系統的結構可以通過輸入輸出數據進行辨識外,一般的模型結構主要通過先驗知識來得到。
參數估計 在知道被辨識的模型的結構之後,模型中可能還會有一些參數的值是未知的,例如前面所舉的動態模型中的向量θ和λ。用輸入輸出數據去確定這些參數值就是參數估計。實際的測量都是有誤差的,所以參數估計以統計方法為主。
對於給定的輸入輸出數據(在某種實驗下取得的)和參數估計算法,首先需要考慮的是能否得到唯一的參數估計值,這就是可辨識性問題。只有在可辨識的前提下,估計算法才是有效的。
參數估計算法按執行的方式可分為一次完成算法和遞推算法兩類。一次完成算法是將所有的數據一次進行處理,即根據全部數據得到參數的估計。遞推算法則是隨著數據的採集不斷用新的數據在原有的估計的基礎上,通過某種遞推的辦法得到新的估計。這種算法適合線上套用。
模型適用性檢驗 通過參數估計得到的模型,雖然按某種準則在選定的模型類中是最好的,但是並不一定能達到建模的目的,所以還必須進行適用性檢驗。這是辨識過程的重要一環,只有通過適用性檢驗的模型才是最終的模型。
造成模型不適用主要有三個方面的原因:模型類(模型的結構)選擇不當;實驗數據誤差過大或由於實驗條件限制,數據的代表性太差;辨識算法存在問題(例如沒有考慮必要的約束)。
模型是否適用與建模的目的緊密相關,所以很難得出統一的檢驗方法,而是要根據問題的性質採取不同的方法。一般來說,適用性檢驗在得到模型後進行,但也可以在辨識過程的各個階段進行。例如,考察模型的結構可辨識性本身就是一種適用性檢驗,不可辨識的模型當然是不適用的。
適用性檢驗的方法主要有兩類:利用先驗知識檢驗和利用數據檢驗。利用先驗知識是適用性檢驗的一條重要途徑。有一些模型從數據的擬合上看不出問題,但是根據對模型已有的知識卻可以斷定模型是否適用。例如辨識一個化學反應動力學模型:已經知道反應物濃度增大並不抑制反應,如果參數估計的結果反應係數是負的,就可斷定這是不合理的。又如辨識生理動力學模型:如果參數估計得到的參數值已超過生理學已知的可能範圍,這樣的模型也是不適用的。適用性檢驗的另一條途徑是,利用數據在同一模型類中或在不同的模型類中進行比較。在得到模型後常常用一組不同於辨識時用的數據去檢驗模型的精度。如果檢驗的結果有過大的誤差,則可能存在兩個問題:辨識用的數據缺乏代表性或所選的模型類不合適。在不同類的模型中進行比較所用的方法主要是統計檢驗(如 F檢驗、似然比檢驗)或者是在擬合誤差的基礎上加上評價模型的懲罰項(如赤池的AIC準則)。
套用 凡是需要通過實驗數據確定數學模型和估計參數的場合都要利用辨識技術,辨識技術已經推廣到工程和非工程的許多領域,如化學化工過程、核反應堆、電力系統、航空航天飛行器、生物醫學系統、社會經濟系統、環境系統、生態系統等。適應控制系統則是辨識與控制相結合的一個範例,也是辨識在控制系統中的套用。
參考書目
G.C.哥德溫、R.L.潘恩著,張永光、袁震東譯:《動態系統辨識》,科學出版社,北京,1983。(G.C.Goodwin and R.L.Payne,dynamic system Identification: Experiment Design and Data Analysis, Academic Press, New York,1977.)
