
曲線估計的概念
線性回歸可以滿足許多數據分析,然而線性回歸不會對所有的問題都適用,有時被解釋變數與解釋變數是通過一個已知或未知的非線性函式關係相聯繫的。變數之間的 非線性關係可以劃分為 本質線性關係和 非本質線性關係。所謂本質線性關係是指變數關係形式上雖然是非線性關係,但可通過變數變換化為線性關係,並可最終進行線性回歸分析建立線性模型;非本質線性關係是指變數關係不僅形式上呈非線性關係,而且也無法通過變數變換化為線性關係,最終無法進行線性回歸分析建立線性模型。而曲線估計是解決本質線性關係問題的。
11種常用模型
用戶如果不能馬上根據專業知識或是觀測量數據本身的特點確定一種最佳模型,也可以利用曲線估計在11種不同的回歸模型中選擇建立一個簡單而又比較適合的模型。SPSS可完成表1中有關曲線擬合的功能。
| 模型名 | 回歸方程 | 變數變換後的線性方程 |
| 二次曲線(Quadratic) | 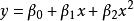 曲線估計 曲線估計 | 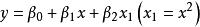 曲線估計 曲線估計 |
| 複合曲線(Compound) | 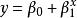 曲線估計 曲線估計 | 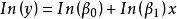 曲線估計 曲線估計 |
| 增長曲線(Growth) | 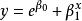 曲線估計 曲線估計 | 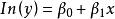 曲線估計 曲線估計 |
| 對數曲線(Logarithmic) | 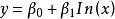 曲線估計 曲線估計 | 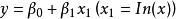 曲線估計 曲線估計 |
| 三次曲線(Cubic) | 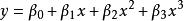 曲線估計 曲線估計 | 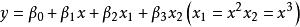 曲線估計 曲線估計 |
| S曲線(S) | 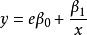 曲線估計 曲線估計 | 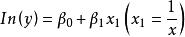 曲線估計 曲線估計 |
| 指數曲線(Exponential) | 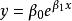 曲線估計 曲線估計 | 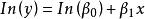 曲線估計 曲線估計 |
| 逆函式(Inverse) | 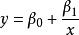 曲線估計 曲線估計 | 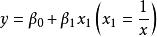 曲線估計 曲線估計 |
| 冪函式(Power) | 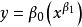 曲線估計 曲線估計 | 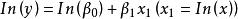 曲線估計 曲線估計 |
| 邏輯函式(Logistic) | 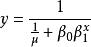 曲線估計 曲線估計 | 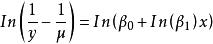 曲線估計 曲線估計 |
在SPSS曲線估計中,首先,在不能明確究竟哪種模型更接近樣本數據時可在多種可選擇的模型中選擇幾種模型;然後,SPSS自動完成模型的參數估計,並輸出回歸方程顯著性檢驗的F值和相伴機率p值、判定係數R 等統計量;最後,以判定係數為主要依據選擇其中的最優模型,並進行預測分析等。另外,SPSS曲線估計還可以以時間為解釋變數,實現時間序列的簡單回歸分析和趨勢外推分析。
曲線估計的步驟
在實際問題中,當不能確定哪種曲線模型最接近樣本數據時,可以運用曲線估計、曲線估計過程可以用於擬合許多常用的曲線,原則上只要兩個變數之間存在某種可以被它所描述的數量關係,就可以用曲線估計過程來分析,曲線估計的基本步驟是:
(1)根據實際問題本身特點,選擇幾種常見的曲線模型;
(2)運用最小二乘法來完成每一種曲線模型的參數估計,並顯示R方、F檢驗值、相伴機率值以及模型的相關係數等統計量;
(3)對參數估計的相關統計量進行檢驗,看其是否通過顯著性檢驗;
(4)預測。選擇R方統計量值最大的模型作為首選的曲線模型。
曲線估計的數據要求
(1)解釋變數與被解釋變數應該是數值型變數。如果在解釋變數中選擇了時間選項,要求被解釋變數是以一定的時間量度的變數。在進行時間分析時,要求數據檔案中的每一個觀測量所使用的時間間隔和長度單位是完全統一的;
(2)模型的殘差應該是任意且呈現常態分配的。如果選擇了線性模型,被解釋變數必須是常態分配的,且所有的觀測值應該是獨立的。
曲線估計在SPSS中的實現
1.打開注對話框
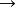 曲線估計 曲線估計
曲線估計 曲線估計建立或打開數據檔案後,按AnalyzeRegressionCurve Estimation的順序打開主對話框。
2.選擇被解釋變數
在源變數框中選擇一個或多個被解釋變數,送人Dependent(s)框中。
3.選擇解釋變數
在源變數框中選擇解釋變數,送人Independent框中,或者直接指定時間選項(time)作為解釋變數。如果選擇了時間作為解釋變數,那么被解釋變數應該是用時間量度的變數。
4.選擇觀測量
在左側源變數框中選擇標示觀測量的變數放入Case Labels框中。
5.選擇擬合模型
在Models欄中選擇一個或多個擬合模型,各模型解釋見表1。
6.選擇相關選項
(1)Include constant in equation:方程包含常數項,系統默認值。
(2)Plot models:繪製曲線擬合圖,系統默認值。
(3)Display ANOVA Table:結果中顯示方差分析表。
7.打開Save對話框
單擊“Save”變數儲存按鈕,激活變數儲存對話框。
(1)Save Variables選項:保存變數。點擊一個或全部選項,可將相應的數值以新變數形式儲存到資料庫中,這些變數的定義將在結果中顯示。其中,Predicted Values代表被解釋變數的預測值;Residuals代表殘差(觀察值與預測值之差)選項;Prediction Intervals代表預測值區間(上下限)選項;Confidence Interval代表可信區間選項。
(2)Predict Case選項:預測觀測量。如果解釋變數為時間變數,可以在該欄中指定一種超出當前數據時間序列範圍的預測周期。
曲線估計①Predict from estimation period through last case選項:使用預先設定好的估計周期中的數據,求出所有觀測量的預測值。要完成這一步,必須先通過Data選單中Select Cases選項中的SelectBase on time or case range定義估計周期,當前的估計周期顯示在對話框的底部。如果沒有預先設定估計周期,計算時使用所有的觀測量。
②Predict through選項:根據預先設定的周期,使預測值通過特定的數據、時間或者特定的觀測量。如果預測值的範圍超出了時間序列的範圍,應該選擇該選項,並在隨後的Observation框中輸入一個預測周期的末端值。
8.單擊OK按鈕提交運行
在大多數情況下,對變數之間關係的認識往往模糊不清,需要先繪製散點圖。
根據數據分布的特點,確定應採用的模型。可以多指定幾個模型進行擬合檢驗,根據輸出的統計量,例如R 值,結合圖形綜合考慮,確定最佳圖形。
