
發展歷史
 原理圖
原理圖1992年,BernhardE.Boser,IsabelleM.Guyon和VladimirN.Vapnik提出了一種通過將核心技巧套用於最大餘量超平面來創建非線性分類器的方法。
目前的標準化身(軟裕度)由CorinnaCortes和Vapnik於1993年提出,並於1995年出版。
Vapnik等人在多年研究統計學習理論基礎上對線性分類器提出了另一種設計最佳準則。其原理也從線性可分說起,然後擴展到線性不可分的情況。甚至擴展到使用非線性函式中去,這種分類器被稱為支持向量機(Support Vector Machine,簡稱SVM)。支持向量機的提出有很深的理論背景。
支持向量機方法是在後來提出的一種新方法。
舉例說明
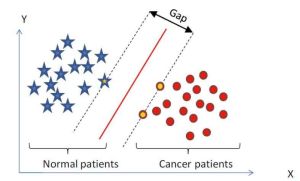
 svm
svmSVM屬於一類廣義線性分類器,可以解釋為感知器的擴展。它們也可以被認為是Tikhonov正則化的特殊情況。一個特殊的屬性是它們同時最小化經驗分類誤差並最大化幾何邊際;因此它們也被稱為最大餘量分類器。
Meyer,Leisch和Hornik對SVM與其他分類器進行了比較。
如右圖:
將1維的“線性不可分”上升到2維後就成為線性可分了。
它基於結構風險最小化理論之上在特徵空間中建構最優分割超平面,使得學習器得到全局最最佳化,並且在整個樣本空間的期望風險以某個機率滿足一定上界。
在學習這種方法時,首先要弄清楚這種方法考慮問題的特點,這就要從線性可分的最簡單情況討論起,在沒有弄懂其原理之前,不要急於學習線性不可分等較複雜的情況,支持向量機在設計時,需要用到條件極值問題的求解,因此需用拉格朗日乘子理論,但對多數人來說,以前學到的或常用的是約束條件為等式表示的方式,但在此要用到以不等式作為必須滿足的條件,此時只要了解拉格朗日理論的有關結論就行。
基本原理
SVM方法是通過一個非線性映射p,把樣本空間映射到一個高維乃至無窮維的特徵空間中(Hilbert空間),使得在原來的樣本空間中非線性可分的問題轉化為在特徵空間中的線性可分的問題.簡單地說,就是升維和線性化.升維,就是把樣本向高維空間做映射,一般情況下這會增加計算的複雜性,甚至會引起“維數災難”,因而人們很少問津.但是作為分類、回歸等問題來說,很可能在低維樣本空間無法線性處理的樣本集,在高維特徵空間中卻可以通過一個線性超平面實現線性劃分(或回歸).一般的升維都會帶來計算的複雜化,SVM方法巧妙地解決了這個難題:套用核函式的展開定理,就不需要知道非線性映射的顯式表達式;由於是在高維特徵空間中建立線性學習機,所以與線性模型相比,不但幾乎不增加計算的複雜性,而且在某種程度上避免了“維數災難”.這一切要歸功於核函式的展開和計算理論。
選擇不同的核函式,可以生成不同的SVM,常用的核函式有以下4種:
1、線性核函式K(x,y)=x·y;
2、多項式核函式K(x,y)=[(x·y)+1]^d;
3、徑向基函式K(x,y)=exp(-|x-y|^2/d^2)
4、二層神經網路核函式K(x,y)=tanh(a(x·y)+b)
思想特徵
SVM的主要思想可以概括為兩點:
1、它是針對線性可分情況進行分析,對於線性不可分的情況,通過使用非線性映射算法將低維輸入空間線性不可分的樣本轉化為高維特徵空間使其線性可分,從而使得高維特徵空間採用線性算法對樣本的非線性特徵進行線性分析成為可能。
2、它基於結構風險最小化理論之上在特徵空間中構建最優超平面,使得學習器得到全局最最佳化,並且在整個樣本空間的期望以某個機率滿足一定上界。
SVM學習問題可以表示為凸最佳化問題,因此可以利用已知的有效算法發現目標函式的全局最小值。而其他分類方法(如基於規則的分類器和人工神經網路)都採用一種基於貪心學習的策略來搜尋假設空間,這種方法一般只能獲得局部最優解。
SVM通過最大化決策邊界的邊緣來控制模型的能力。儘管如此,用戶必須提供其他參數,如使用核函式類型和引入鬆弛變數等。
通過對數據中每個分類屬性引入一個啞變數,SVM可以套用於分類數據。
SVM一般只能用在二類問題,對於多類問題效果不好。
擴展信息
支持向量聚類(SVC)
SVC是一種類似的方法,它也建立在核心函式上,但適用於無監督的學習和數據挖掘。它被認為是數據科學的基本方法。
多類SVM
多類SVM旨在通過使用支持向量機為實例分配標籤,其中標籤從有限的幾個元素集中繪製。這樣做的主要方法是將單個多類問題減少為多個二進制分類問題。這種減少的常見方法包括:
構建二進制分類器,區分(i)標籤之間的一個和其餘的(一對全部)或(ii)每對類之間(一對一)。一對一的情況的新實例的分類是通過獲勝者採取所有策略完成的,其中具有最高輸出函式的分類器分配類(重要的是輸出函式被校準以產生可比較的分數)。對於一對一的方法,通過最大勝利投票策略進行分類,其中每個分類器將實例分配給兩個類中的一個,然後對所分配的類的投票增加一個投票,最後是最多選票的課程決定了實例分類。
定向非循環圖SVM(DAGSVM)
糾錯輸出代碼
Crammer和Singer提出了一種多類SVM方法,將多類分類問題轉化為單個最佳化問題,而不是將其分解為多個二進制分類問題。
結構化SVM
SVM已經被推廣到結構化SVM,其中標籤空間被構造並且具有可能的無限大小。
潛在缺陷
SVM的潛在缺點包括以下幾個方面:
需要對輸入數據進行全面標註
非校準類成員機率-SVM源於Vapnik的理論,避免了有限數據的估計機率
SVM只適用於兩類任務。因此,必須套用將多類任務減少到幾個二進制問題的算法。
求解模型的參數難以解釋。
實現軟體
C/C++
Lush -- an Lisp-like interpreted/compiled language with C/C++/Fortran interfaces that haspackages to interface to a number of different SVM implementations. Interfaces to LASVM,LIBSVM,mySVM,SVQP,SVQP2 (SVQP3 in future) are available. Leverage these against Lush's other interfaces to machine learning,hidden markov models,numerical libraries (LAPACK,BLAS,GSL),and builtin vector/matrix/tensor engine.
SVMlight -- a popular implementation of the SVM algorithm by Thorsten Joachims; it can be used to solve classification,regression and ranking problems.
LIBSVM-- A Library for Support Vector Machines,Chih-Chung Chang and Chih-Jen Lin
YALE -- a powerful machine learning toolbox containing wrappers for SVMLight,LibSVM,and MySVM in addition to many evaluation and preprocessing methods.
LS-SVMLab - Matlab/C SVM toolbox - well-documented,many features
Gist -- implementation of the SVM algorithm with feature selection.
Weka -- a machine learning toolkit that includes an implementation of an SVM classifier; Weka can be used both interactively though a graphical interface or as a software library. (One of them is called "SMO". In the GUI Weka explorer,it is under the "classify" tab if you "Choose" an algorithm.)
OSU SVM - Matlab implementation based on LIBSVM
Torch - C++ machine learning library with SVMShogun - Large Scale Machine Learning Toolbox with interfaces to Octave,Matlab,Python,R
Spider - Machine learning library for Matlab
kernlab - Kernel-based Machine Learning library for R
TinySVM -- a small SVM implementation,written in C++
R
e1071 - Machine learning library for R
Matlab
SimpleSVM - SimpleSVM toolbox for Matlab
SVM and Kernel Methods Matlab Toolbox
PCP -- C program for supervised pattern classification. Includes LIBSVM wrapper.
python
numpy -fundamental package for scientific computing with Python
scipy -package of tools for science and engineering for Python
PHP
LibSVM是SVM分類和回歸問題的有效解決方案。這裡的以php接口封裝的svm擴展是為了在php腳本中更方便的套用。
SVM—TheSVMclass
SVM::__construct—ConstructanewSVMobject
SVM::crossvalidate—Testtrainingparamsonsubsetsofthetrainingdata.
SVM::getOptions—Returnthecurrenttrainingparameters
SVM::setOptions—Settrainingparameters
SVM::train—CreateaSVMModelbasedontrainingdata
SVMModel—TheSVMModelclass
SVMModel::checkProbabilityModel—Returnstrueifthemodelhasprobabilityinformation
SVMModel::__construct—ConstructanewSVMModel
SVMModel::getLabels—Getthelabelsthemodelwastrainedon
SVMModel::getNrClass—Returnsthenumberofclassesthemodelwastrainedwith
SVMModel::getSvmType—GettheSVMtypethemodelwastrainedwith
SVMModel::getSvrProbability—Getthesigmavalueforregressiontypes
SVMModel::load—LoadasavedSVMModel
SVMModel::predict_probability—Returnclassprobabilitiesforpreviousunseendata
SVMModel::predict—Predictavalueforpreviouslyunseendata
SVMModel::save—Saveamodeltoafile
主要軟體
Lush--anLisp-likeinterpreted/compiledlanguagewithC/C++/FortraninterfacesthathaspackagestointerfacetoanumberofdifferentSVMimplementations.InterfacestoLASVM,LIBSVM,mySVM,SVQP,SVQP2(SVQP3infuture)areavailable.LeveragetheseagainstLush'sotherinterfacestomachinelearning,hiddenmarkovmodels,numericallibraries(LAPACK,BLAS,GSL),andbuiltinvector/matrix/tensorengine.
SVMlight--apopularimplementationoftheSVMalgorithmbyThorstenJoachims;itcanbeusedtosolveclassification,regressionandrankingproblems.
LIBSVM--ALibraryforSupportVectorMachines,Chih-ChungChangandChih-JenLin
YALE--apowerfulmachinelearningtoolboxcontainingwrappersforSVMLight,LibSVM,andMySVMinadditiontomanyevaluationandpreprocessingmethods.
LS-SVMLab-Matlab/CSVMtoolbox-well-documented,manyfeatures
Gist--implementationoftheSVMalgorithmwithfeatureselection.
Weka--amachinelearningtoolkitthatincludesanimplementationofanSVMclassifier;Wekacanbeusedbothinteractivelythoughagraphicalinterfaceorasasoftwarelibrary.(Oneofthemiscalled"SMO".IntheGUIWekaexplorer,itisunderthe"classify"tabifyou"Choose"analgorithm.)
OSUSVM-MatlabimplementationbasedonLIBSVM
Torch-C++machinelearninglibrarywithSVMShogun-LargeScaleMachineLearningToolboxwithinterfacestoOctave,Matlab,Python,R
Spider-MachinelearninglibraryforMatlab
kernlab-Kernel-basedMachineLearninglibraryforR
e1071-MachinelearninglibraryforR
SimpleSVM-SimpleSVMtoolboxforMatlab
SVMandKernelMethodsMatlabToolbox
PCP--Cprogramforsupervisedpatternclassification.IncludesLIBSVMwrapper.
TinySVM--asmallSVMimplementation,writteninC++
套用領域
SVM可用於解決各種現實世界的問題:
支持向量機有助於文本和超文本分類,因為它們的應用程式可以顯著減少對標準感應和轉換設定中標記的訓練實例的需求。
圖像的分類也可以使用SVM進行。實驗結果表明,只有三到四輪的相關性反饋,支持向量機的搜尋精度要比傳統的查詢最佳化方案高得多。圖像分割系統也是如此,包括使用Vapnik建議的使用特權方法的修改版SVM的系統。
使用SVM可以識別手寫字元。
SVM算法已廣泛套用於生物科學和其他科學領域。它們已被用於對高達90%正確分類的化合物進行蛋白質分類。已經提出基於SVM權重的置換測試作為解釋SVM模型的機制。支持向量機權重也被用於解釋過去的SVM模型。Posthoc解釋支持向量機模型為了識別模型使用的特徵進行預測是一個比較新的研究領域,在生物科學中具有特殊的意義。
具體實施
最大餘量超平面的參數是通過求解最佳化得到的。存在幾種用於快速解決由SVM產生的QP問題的專用算法,主要依靠啟發式將問題分解成更小,更易於管理的塊。
一種方法是使用內點法,使用牛頓式疊代來找到原始和雙重問題的Karush-Kuhn-Tucker條件的解決方案。這種方法不是解決一系列分解問題,而是直接解決了這個問題。為了避免解決涉及大核心矩陣的線性系統,在核心技巧中經常使用對矩陣的低階逼近。
另一種常見的方法是Platt的順序最小最佳化(SMO)算法,將問題分解為分解解決的二維子問題,無需數字最佳化算法和矩陣存儲。該算法在概念上是簡單的,易於實現,通常更快,並且具有更好的縮放屬性,用於困難的SVM問題。
線性支持向量機的特殊情況可以通過用於最佳化其親密表達,邏輯回歸的相同種類的算法來更有效地解決;這類算法包括子梯度下降(例如,PEGASOS)和坐標下降(例如,LIBLINEAR)。LIBLINEAR有一些有吸引力的訓練時間屬性。每個收斂疊代在讀取列車數據所花費的時間都需要時間線性,並且疊代也具有Q線性收斂屬性,使算法非常快速。
一般核心支持向量機,也可更有效地解決了使用子梯度下降(例如P-packSVM),特別是當並行化是允許的。
核心支持向量機在很多機器學習工具包,其中包括可用的LIBSVM,MATLAB,SAS,SVMlight,kernlab,scikit學習,JKernelMachines,OpenCV。
