
定義
MapReduce是面向大數據並行處理的計算模型、框架和平台,它隱含了以下三層含義:
1)MapReduce是一個基於集群的高性能並行計算平台(Cluster Infrastructure)。它允許用市場上普通的商用伺服器構成一個包含數十、數百至數千個節點的分布和並行計算集群。
2)MapReduce是一個並行計算與運行軟體框架(Software Framework)。它提供了一個龐大但設計精良的並行計算軟體框架,能自動完成計算任務的並行化處理,自動劃分計算數據和計算任務,在集群節點上自動分配和執行任務以及收集計算結果,將數據分布存儲、數據通信、容錯處理等並行計算涉及到的很多系統底層的複雜細節交由系統負責處理,大大減少了軟體開發人員的負擔。
3)MapReduce是一個並行程式設計模型與方法(Programming Model & Methodology)。它藉助於函式式程式設計語言Lisp的設計思想,提供了一種簡便的並行程式設計方法,用Map和Reduce兩個函式編程實現基本的並行計算任務,提供了抽象的操作和並行編程接口,以簡單方便地完成大規模數據的編程和計算處理 。
由來
MapReduce最早是由Google公司研究提出的一種面向大規模數據處理的並行計算模型和方法。Google公司設計MapReduce的初衷主要是為了解決其搜尋引擎中大規模網頁數據的並行化處理。Google公司發明了MapReduce之後首先用其重新改寫了其搜尋引擎中的Web文檔索引處理系統。但由於MapReduce可以普遍套用於很多大規模數據的計算問題,因此自發明MapReduce以後,Google公司內部進一步將其廣泛套用於很多大規模數據處理問題。到目前為止,Google公司內有上萬個各種不同的算法問題和程式都使用MapReduce進行處理。
2003年和2004年,Google公司在國際會議上分別發表了兩篇關於Google分散式檔案系統和MapReduce的論文,公布了Google的GFS和MapReduce的基本原理和主要設計思想。
Hadoop的思想來源於Google的幾篇論文,Google的那篇MapReduce論文裡說:Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages。這句話提到了MapReduce思想的淵源,大致意思是,MapReduce的靈感來源於函式式語言(比如Lisp)中的內置函式map和reduce。函式式語言也算是陽春白雪了,離我們普通開發者總是很遠。簡單來說,在函式式語言裡,map表示對一個列表(List)中的每個元素做計算,reduce表示對一個列表中的每個元素做疊代計算。它們具體的計算是通過傳入的函式來實現的,map和reduce提供的是計算的框架。不過從這樣的解釋到現實中的MapReduce還太遠,仍然需要一個跳躍。再仔細看,reduce既然能做疊代計算,那就表示列表中的元素是相關的,比如我想對列表中的所有元素做相加求和,那么列表中至少都應該是數值吧。而map是對列表中每個元素做單獨處理的,這表示列表中可以是雜亂無章的數據。這樣看來,就有點聯繫了。在MapReduce里,Map處理的是原始數據,自然是雜亂無章的,每條數據之間互相沒有關係;到了Reduce階段,數據是以key後面跟著若干個value來組織的,這些value有相關性,至少它們都在一個key下面,於是就符合函式式語言裡map和reduce的基本思想了。
這樣我們就可以把MapReduce理解為,把一堆雜亂無章的數據按照某種特徵歸納起來,然後處理並得到最後的結果。Map面對的是雜亂無章的互不相關的數據,它解析每個數據,從中提取出key和value,也就是提取了數據的特徵。經過MapReduce的Shuffle階段之後,在Reduce階段看到的都是已經歸納好的數據了,在此基礎上我們可以做進一步的處理以便得到結果。這就回到了最初,終於知道MapReduce為何要這樣設計。
2004年,開源項目Lucene(搜尋索引程式庫)和Nutch(搜尋引擎)的創始人Doug Cutting發現MapReduce正是其所需要的解決大規模Web數據處理的重要技術,因而模仿Google MapReduce,基於Java設計開發了一個稱為Hadoop的開源MapReduce並行計算框架和系統。自此,Hadoop成為Apache開源組織下最重要的項目,自其推出後很快得到了全球學術界和工業界的普遍關注,並得到推廣和普及套用。
MapReduce的推出給大數據並行處理帶來了巨大的革命性影響,使其已經成為事實上的大數據處理的工業標準。儘管MapReduce還有很多局限性,但人們普遍公認,MapReduce是到目前為止最為成功、最廣為接受和最易於使用的大數據並行處理技術。MapReduce的發展普及和帶來的巨大影響遠遠超出了發明者和開源社區當初的意料,以至於馬里蘭大學教授、2010年出版的《Data-Intensive Text Processing with MapReduce》一書的作者Jimmy Lin在書中提出:MapReduce改變了我們組織大規模計算的方式,它代表了第一個有別於馮·諾依曼結構的計算模型,是在集群規模而非單個機器上組織大規模計算的新的抽象模型上的第一個重大突破,是到目前為止所見到的最為成功的基於大規模計算資源的計算模型。
映射和化簡
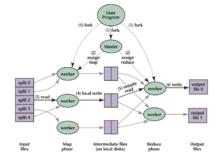 執行步驟
執行步驟簡單說來,一個映射函式就是對一些獨立元素組成的概念上的列表(例如,一個測試成績的列表)的每一個元素進行指定的操作(比如前面的例子裡,有人發現所有學生的成績都被高估了一分,它可以定義一個“減一”的映射函式,用來修正這個錯誤。)。事實上,每個元素都是被獨立操作的,而原始列表沒有被更改,因為這裡創建了一個新的列表來保存新的答案。這就是說,Map操作是可以高度並行的,這對高性能要求的套用以及並行計算領域的需求非常有用。
而化簡操作指的是對一個列表的元素進行適當的合併(繼續看前面的例子,如果有人想知道班級的平均分該怎么做?它可以定義一個化簡函式,通過讓列表中的元素跟自己的相鄰的元素相加的方式把列表減半,如此遞歸運算直到列表只剩下一個元素,然後用這個元素除以人數,就得到了平均分。)。雖然他不如映射函式那么並行,但是因為化簡總是有一個簡單的答案,大規模的運算相對獨立,所以化簡函式在高度並行環境下也很有用。
分布可靠
MapReduce通過把對數據集的大規模操作分發給網路上的每個節點實現可靠性;每個節點會周期性的返回它所完成的工作和最新的狀態。如果一個節點保持沉默超過一個預設的時間間隔,主節點(類同Google File System中的主伺服器)記錄下這個節點狀態為死亡,並把分配給這個節點的數據發到別的節點。每個操作使用命名檔案的原子操作以確保不會發生並行執行緒間的衝突;當檔案被改名的時候,系統可能會把他們複製到任務名以外的另一個名字上去。(避免副作用)。
化簡操作工作方式與之類似,但是由於化簡操作的可並行性相對較差,主節點會儘量把化簡操作只分配在一個節點上,或者離需要操作的數據儘可能近的節點上;這個特性可以滿足Google的需求,因為他們有足夠的頻寬,他們的內部網路沒有那么多的機器。
用途
在Google,MapReduce用在非常廣泛的應用程式中,包括“分布grep,分布排序,web連線圖反轉,每台機器的詞矢量,web訪問日誌分析,反向索引構建,文檔聚類,機器學習,基於統計的機器翻譯...”值得注意的是,MapReduce實現以後,它被用來重新生成Google的整個索引,並取代老的ad hoc程式去更新索引。
MapReduce會生成大量的臨時檔案,為了提高效率,它利用Google檔案系統來管理和訪問這些檔案。
在谷歌,超過一萬個不同的項目已經採用MapReduce來實現,包括大規模的算法圖形處理、文字處理、數據挖掘、機器學習、統計機器翻譯以及眾多其他領域。
其他實現
Nutch項目開發了一個實驗性的MapReduce的實現,也即是後來大名鼎鼎的hadoop
Phoenix是史丹福大學開發的基於多核/多處理器、共享記憶體的MapReduce實現。
主要功能
MapReduce提供了以下的主要功能:
1)數據劃分和計算任務調度:
系統自動將一個作業(Job)待處理的大數據劃分為很多個數據塊,每個數據塊對應於一個計算任務(Task),並自動 調度計算節點來處理相應的數據塊。作業和任務調度功能主要負責分配和調度計算節點(Map節點或Reduce節點),同時負責監控這些節點的執行狀態,並 負責Map節點執行的同步控制。
2)數據/代碼互定位:
為了減少數據通信,一個基本原則是本地化數據處理,即一個計算節點儘可能處理其本地磁碟上所分布存儲的數據,這實現了代碼向 數據的遷移;當無法進行這種本地化數據處理時,再尋找其他可用節點並將數據從網路上傳送給該節點(數據向代碼遷移),但將儘可能從數據所在的本地機架上尋 找可用節點以減少通信延遲。
3)系統最佳化:
為了減少數據通信開銷,中間結果數據進入Reduce節點前會進行一定的合併處理;一個Reduce節點所處理的數據可能會來自多個 Map節點,為了避免Reduce計算階段發生數據相關性,Map節點輸出的中間結果需使用一定的策略進行適當的劃分處理,保證相關性數據傳送到同一個 Reduce節點;此外,系統還進行一些計算性能最佳化處理,如對最慢的計算任務採用多備份執行、選最快完成者作為結果。
4)出錯檢測和恢復:
以低端商用伺服器構成的大規模MapReduce計算集群中,節點硬體(主機、磁碟、記憶體等)出錯和軟體出錯是常態,因此 MapReduce需要能檢測並隔離出錯節點,並調度分配新的節點接管出錯節點的計算任務。同時,系統還將維護數據存儲的可靠性,用多備份冗餘存儲機制提 高數據存儲的可靠性,並能及時檢測和恢復出錯的數據。
主要技術特徵
MapReduce設計上具有以下主要的技術特徵:
1)向“外”橫向擴展,而非向“上”縱向擴展
即MapReduce集群的構建完全選用價格便宜、易於擴展的低端商用伺服器,而非價格昂貴、不易擴展的高端伺服器。
對於大規模數據處理,由於有大 量數據存儲需要,顯而易見,基於低端伺服器的集群遠比基於高端伺服器的集群優越,這就是為什麼MapReduce並行計算集群會基於低端伺服器實現的原 因。
2)失效被認為是常態
MapReduce集群中使用大量的低端伺服器,因此,節點硬體失效和軟體出錯是常態,因而一個良好設計、具有高容錯性的並行計算系統不能因為節點 失效而影響計算服務的質量,任何節點失效都不應當導致結果的不一致或不確定性;任何一個節點失效時,其他節點要能夠無縫接管失效節點的計算任務;當失效節 點恢復後應能自動無縫加入集群,而不需要管理員人工進行系統配置。
MapReduce並行計算軟體框架使用了多種有效的錯誤檢測和恢復機制,如節點自動重 啟技術,使集群和計算框架具有對付節點失效的健壯性,能有效處理失效節點的檢測和恢復。
3)把處理向數據遷移
傳統高性能計算系統通常有很多處理器節點與一些外存儲器節點相連,如用存儲區域網路(Storage Area,SAN Network)連線的磁碟陣列,因此,大規模數據處理時外存檔案數據I/O訪問會成為一個制約系統性能的瓶頸。
為了減少大規模數據並行計算系統中的數據 通信開銷,代之以把數據傳送到處理節點(數據向處理器或代碼遷移),應當考慮將處理向數據靠攏和遷移。MapReduce採用了數據/代碼互定位的技術方法,計算節點將首先儘量負責計算其本地存儲的數據,以發揮數據本地化特點,僅當節點無法處理本地數據時,再採用就近原則尋找其他可用計算節點,並把數據傳送到該可用計算節點。
4)順序處理數據、避免隨機訪問數據
大規模數據處理的特點決定了大量的數據記錄難以全部存放在記憶體,而通常只能放在外存中進行處理。由於磁碟的順序訪問要遠比隨機訪問快得多,因此 MapReduce主要設計為面向順序式大規模數據的磁碟訪問處理。
為了實現面向大數據集批處理的高吞吐量的並行處理,MapReduce可以利用集群中 的大量數據存儲節點同時訪問數據,以此利用分布集群中大量節點上的磁碟集合提供高頻寬的數據訪問和傳輸。
5)為套用開發者隱藏系統層細節
軟體工程實踐指南中,專業程式設計師認為之所以寫程式困難,是因為程式設計師需要記住太多的編程細節(從變數名到複雜算法的邊界情況處理),這對大腦記憶是 一個巨大的認知負擔,需要高度集中注意力;而並行程式編寫有更多困難,如需要考慮多執行緒中諸如同步等複雜繁瑣的細節。由於並發執行中的不可預測性,程式的 調試查錯也十分困難;而且,大規模數據處理時程式設計師需要考慮諸如數據分布存儲管理、數據分發、數據通信和同步、計算結果收集等諸多細節問題。
MapReduce提供了一種抽象機制將程式設計師與系統層細節隔離開來,程式設計師僅需描述需要計算什麼(What to compute),而具體怎么去計算(How to compute)就交由系統的執行框架處理,這樣程式設計師可從系統層細節中解放出來,而致力於其套用本身計算問題的算法設計。
6)平滑無縫的可擴展性
這裡指出的可擴展性主要包括兩層意義上的擴展性:數據擴展和系統規模擴展性。
理想的軟體算法應當能隨著數據規模的擴大而表現出持續的有效性,性能上的下降程度應與數據規模擴大的倍數相當;在集群規模上,要求算法的計算性能應能隨著節點數的增加保持接近線性程度的增長。絕大多數現有的單機算法都達不到 以上理想的要求;把中間結果數據維護在記憶體中的單機算法在大規模數據處理時很快失效;從單機到基於大規模集群的並行計算從根本上需要完全不同的算法設計。奇妙的是,MapReduce在很多情形下能實現以上理想的擴展性特徵。
多項研究發現,對於很多計算問題,基於MapReduce的計算性能可隨節點數目增長保持近似於線性的增長。
案例
:統計詞頻
如果想統計下過去10年計算機論文出現最多的幾個單詞,看看大家都在研究些什麼,那收集好論文後,該怎么辦呢?
方法一:我可以寫一個小程式,把所有論文按順序遍歷一遍,統計每一個遇到的單詞的出現次數,最後就可以知道哪幾個單詞最熱門了。
這種方法在數據集比較耗時,是非常有效的,而且實現最簡單,用來解決這個問題很合適。
方法二:寫一個多執行緒程式,並發遍歷論文。
這個問題理論上是可以高度並發的,因為統計一個檔案時不會影響統計另一個檔案。當我們的機器是多核或者多處理器,方法二肯定比方法一高效。但是寫一個多執行緒程式要比方法一困難多了,我們必須自己同步共享數據,比如要防止兩個執行緒重複統計檔案。
方法三:把作業交給多個計算機去完成。
我們可以使用方法一的程式,部署到N台機器上去,然後把論文集分成N份,一台機器跑一個作業。這個方法跑得足夠快,但是部署起來很麻煩,我們要人工把程式copy到別的機器,要人工把論文集分開,最痛苦的是還要把N個運行結果進行整合(當然我們也可以再寫一個程式)。
方法四:讓MapReduce來幫幫我們吧!
MapReduce本質上就是方法三,但是如何拆分檔案集,如何copy程式,如何整合結果這些都是框架定義好的。我們只要定義好這個任務(用戶程式),其它都交給MapReduce。
MapReduce偽代碼
實現Map和Reduce兩個函式
Map函式和Reduce函式是交給用戶實現的,這兩個函式定義了任務本身。
Map函式
接受一個鍵值對(key-value pair),產生一組中間鍵值對。MapReduce框架會將map函式產生的中間鍵值對里鍵相同的值傳遞給一個reduce函式。
ClassMapper
methodmap(String input_key, String input_value):
// input_key: text document name
// input_value: document contents
for eachword w ininput_value:
EmitIntermediate(w, "1");
Reduce函式
接受一個鍵,以及相關的一組值,將這組值進行合併產生一組規模更小的值(通常只有一個或零個值)。
ClassReducer
method reduce(String output_key,Iterator intermediate_values):
// output_key: a word
// output_values: a list of counts
intresult = 0;
for each v in intermediate_values:
result += ParseInt(v);
Emit(AsString(result));
在統計詞頻的例子裡,map函式接受的鍵是檔案名稱,值是檔案的內容,map逐個遍歷單詞,每遇到一個單詞w,就產生一個中間鍵值對<w, "1">,這表示單詞w咱又找到了一個;MapReduce將鍵相同(都是單詞w)的鍵值對傳給reduce函式,這樣reduce函式接受的鍵就是單詞w,值是一串"1"(最基本的實現是這樣,但可以最佳化),個數等於鍵為w的鍵值對的個數,然後將這些“1”累加就得到單詞w的出現次數。最後這些單詞的出現次數會被寫到用戶定義的位置,存儲在底層的分散式存儲系統(GFS或HDFS)。
工作原理
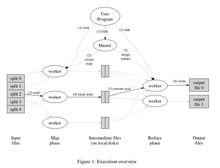 MapReduce執行流程
MapReduce執行流程右圖是論文裡給出的流程圖。一切都是從最上方的user program開始的,user program連結了MapReduce庫,實現了最基本的Map函式和Reduce函式。圖中執行的順序都用數字標記了。
1.MapReduce庫先把user program的輸入檔案劃分為M份(M為用戶定義),每一份通常有16MB到64MB,如圖左方所示分成了split0~4;然後使用fork將用戶進程拷貝到集群內其它機器上。
2.user program的副本中有一個稱為master,其餘稱為worker,master是負責調度的,為空閒worker分配作業(Map作業或者Reduce作業),worker的數量也是可以由用戶指定的。
3.被分配了Map作業的worker,開始讀取對應分片的輸入數據,Map作業數量是由M決定的,和split一一對應;Map作業從輸入數據中抽取出鍵值對,每一個鍵值對都作為參數傳遞給map函式,map函式產生的中間鍵值對被快取在記憶體中。
4.快取的中間鍵值對會被定期寫入本地磁碟,而且被分為R個區,R的大小是由用戶定義的,將來每個區會對應一個Reduce作業;這些中間鍵值對的位置會被通報給master,master負責將信息轉發給Reduce worker。
5.master通知分配了Reduce作業的worker它負責的分區在什麼位置(肯定不止一個地方,每個Map作業產生的中間鍵值對都可能映射到所有R個不同分區),當Reduce worker把所有它負責的中間鍵值對都讀過來後,先對它們進行排序,使得相同鍵的鍵值對聚集在一起。因為不同的鍵可能會映射到同一個分區也就是同一個Reduce作業(誰讓分區少呢),所以排序是必須的。
6.reduce worker遍歷排序後的中間鍵值對,對於每個唯一的鍵,都將鍵與關聯的值傳遞給reduce函式,reduce函式產生的輸出會添加到這個分區的輸出檔案中。
7.當所有的Map和Reduce作業都完成了,master喚醒正版的user program,MapReduce函式調用返回user program的代碼。
所有執行完畢後,MapReduce輸出放在了R個分區的輸出檔案中(分別對應一個Reduce作業)。用戶通常並不需要合併這R個檔案,而是將其作為輸入交給另一個MapReduce程式處理。整個過程中,輸入數據是來自底層分散式檔案系統(GFS)的,中間數據是放在本地檔案系統的,最終輸出數據是寫入底層分散式檔案系統(GFS)的。而且我們要注意Map/Reduce作業和map/reduce函式的區別:Map作業處理一個輸入數據的分片,可能需要調用多次map函式來處理每個輸入鍵值對;Reduce作業處理一個分區的中間鍵值對,期間要對每個不同的鍵調用一次reduce函式,Reduce作業最終也對應一個輸出檔案。
經典實例
MapReduce的一個經典實例是Hadoop。用於處理大型分散式資料庫。由於Hadoop關聯到雲以及雲部署,大多數人忽略了一點,Hadoop有些屬性不適合一般企業的需求,特別是移動應用程式。下面是其中的一些特點:
•Hadoop的最大價值在於資料庫,而Hadoop所用的資料庫是移動應用程式所用資料庫的10到1000倍。對於許多人來說,使用Hadoop就是殺雞用牛刀。
•Hadoop有顯著的設定和處理開銷。 Hadoop工作可能會需要幾分鐘的時間,即使相關數據量不是很大。
•Hadoop在支持具有多維上下文數據結構方面不是很擅長。例如,一個定義給定地理變數值的記錄,然後使用垂直連線,來連續定義一個比hadoop使用的鍵值對定義更複雜的數據結構關係。
•Hadoop必須使用疊代方法處理的問題方面用處不大——尤其是幾個連續有依賴性步驟的問題。
MapReduce (EMR),這是一項Hadoop服務。Hadoop旨在同期檔案系統工作,以HDFS著稱。
當用戶用EMR創建了一個Hadoop集群,他們可以從AWS S3或者一些其他的數據存儲複製數據到集群上的HDFS,或者也可以直接從S3訪問數據。HDFS使用本地存儲,而且通常提供了比從S3恢復更好的性能,但是在運行Hadoop工作之前,也需要時間從S3複製數據到HDFS。如果EMR集群要運行一段時間,且針對多項工作使用相同的數據,可能值得額外的啟動時間來從S3複製數據到HDFS。
參考
Dean, Jeffrey & Ghemawat, Sanjay (2004). "MapReduce: Simplified Data Processing on Large Clusters". Retrieved Apr. 6, 2005
"Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages." -"MapReduce: Simplified Data Processing on Large Clusters"
