
概述
Hadoop由ApacheSoftwareFoundation公司於2005年秋天作為Lucene的子項目Nutch的一部分正式引入。它受到最先由GoogleLab開發的MapReduce和GoogleFileSystem的啟發。2006年3月份,MapReduce和NutchDistributedFileSystem(NDFS)分別被納入稱為Hadoop的項目中。
Hadoop是最受歡迎的在Internet上對搜尋關鍵字進行內容分類的工具,但它也可以解決許多要求極大伸縮性的問題。例如,如果您要grep一個10TB的巨型檔案,會出現什麼情況?在傳統的系統上,這將需要很長的時間。但是Hadoop在設計時就考慮到這些問題,因此能大大提高效率。
由ApacheHadoop項目所提供的穩定、可擴展、支持分散式計算的開源軟體。Apache的hadoop軟體庫是支持通過簡單的開發模型在計算機集群上分散式地處理大數據集的框架,它被設計為允許從單個主機到數千個主機的擴展能力而且每個主機都提供本地的計算與存儲。與以往依賴於硬體來實現高可用性不同,該軟體庫在設計上是由套用層負責檢測並處理故障的。因而能夠在主機集群上提供高可用服務。
優點
 hadoop
hadoopHadoop是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。
Hadoop是高效的,因為它以並行的方式工作,通過並行處理加快處理速度。
Hadoop還是可伸縮的,能夠處理PB級數據。
此外,Hadoop依賴於社區服務,因此它的成本比較低,任何人都可以使用。
Hadoop是一個能夠讓用戶輕鬆架構和使用的分散式計算平台。用戶可以輕鬆地在Hadoop上開發和運行處理海量數據的應用程式。它主要有以下幾個優點:
高可靠性。Hadoop按位存儲和處理數據的能力值得人們信賴。
高擴展性。Hadoop是在可用的計算機集簇間分配數據並完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。
高效性。Hadoop能夠在節點之間動態地移動數據,並保證各個節點的動態平衡,因此處理速度非常快。
高容錯性。Hadoop能夠自動保存數據的多個副本,並且能夠自動將失敗的任務重新分配。
低成本。與一體機、商用數據倉庫以及QlikView、YonghongZ-Suite等數據集市相比,hadoop是開源的,項目的軟體成本因此會大大降低。
Hadoop帶有用Java語言編寫的框架,因此運行在Linux生產平台上是非常理想的。Hadoop上的應用程式也可以使用其他語言編寫,比如C++。
hadoop大數據處理的意義
Hadoop得以在大數據處理套用中廣泛套用得益於其自身在數據提取、變形和載入(ETL)方面上的天然優勢。Hadoop的分散式架構,將大數據處理引擎儘可能的靠近存儲,對例如像ETL這樣的批處理操作相對合適,因為類似這樣操作的批處理結果可以直接走向存儲。Hadoop的MapReduce功能實現了將單個任務打碎,並將碎片任務(Map)傳送到多個節點上,之後再以單個數據集的形式載入(Reduce)到數據倉庫里。
架構
Hadoop有許多元素構成。最底部是HadoopDistributedFileSystem(hdfs),它存儲Hadoop集群中所有存儲節點上的檔案。HDFS(對於本文)的上一層是MapReduce引擎,該引擎由JobTrackers和TaskTrackers組成。
HDFS
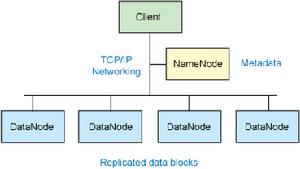 圖 1. Hadoop 集群的簡化視圖
圖 1. Hadoop 集群的簡化視圖存儲在HDFS中的檔案被分成塊,然後將這些塊複製到多個計算機中(DataNode)。這與傳統的RAID架構大不相同。塊的大小(通常為64MB)和複製的塊數量在創建檔案時由客戶機決定。NameNode可以控制所有檔案操作。HDFS內部的所有通信都基於標準的TCP/IP協定。
NameNode
NameNode是一個通常在HDFS實例中的單獨機器上運行的軟體。它負責管理檔案系統名稱空間和控制外部客戶機的訪問。NameNode決定是否將檔案映射到DataNode上的複製塊上。對於最常見的3個複製塊,第一個複製塊存儲在同一機架的不同節點上,最後一個複製塊存儲在不同機架的某個節點上。注意,這裡需要您了解集群架構。
實際的I/O事務並沒有經過NameNode,只有表示DataNode和塊的檔案映射的元數據經過NameNode。當外部客戶機傳送請求要求創建檔案時,NameNode會以塊標識和該塊的第一個副本的DataNodeIP位址作為回響。這個NameNode還會通知其他將要接收該塊的副本的DataNode。
NameNode在一個稱為FsImage的檔案中存儲所有關於檔案系統名稱空間的信息。這個檔案和一個包含所有事務的記錄檔案(這裡是EditLog)將存儲在NameNode的本地檔案系統上。FsImage和EditLog檔案也需要複製副本,以防檔案損壞或NameNode系統丟失。
DataNode
NameNode也是一個通常在HDFS實例中的單獨機器上運行的軟體。Hadoop集群包含一個NameNode和大量DataNode。DataNode通常以機架的形式組織,機架通過一個交換機將所有系統連線起來。Hadoop的一個假設是:機架內部節點之間的傳輸速度快於機架間節點的傳輸速度。
DataNode回響來自HDFS客戶機的讀寫請求。它們還回響創建、刪除和複製來自NameNode的塊的命令。NameNode依賴來自每個DataNode的定期心跳(heartbeat)訊息。每條訊息都包含一個塊報告,NameNode可以根據這個報告驗證塊映射和其他檔案系統元數據。如果DataNode不能傳送心跳訊息,NameNode將採取修復措施,重新複製在該節點上丟失的塊。
檔案操作
可見,HDFS並不是一個萬能的檔案系統。它的主要目的是支持以流的形式訪問寫入的大型檔案。如果客戶機想將檔案寫到HDFS上,首先需要將該檔案快取到本地的臨時存儲。如果快取的數據大於所需的HDFS塊大小,創建檔案的請求將傳送給NameNode。NameNode將以DataNode標識和目標塊回響客戶機。同時也通知將要保存檔案塊副本的DataNode。當客戶機開始將臨時檔案傳送給第一個DataNode時,將立即通過管道方式將塊內容轉發給副本DataNode。客戶機也負責創建保存在相同HDFS名稱空間中的校驗和(checksum)檔案。在最後的檔案塊傳送之後,NameNode將檔案創建提交到它的持久化元數據存儲(在EditLog和FsImage檔案)。
Linux 集群
Hadoop框架可在單一的Linux平台上使用(開發和調試時),但是使用存放在機架上的商業伺服器才能發揮它的力量。這些機架組成一個Hadoop集群。它通過集群拓撲知識決定如何在整個集群中分配作業和檔案。Hadoop假定節點可能失敗,因此採用本機方法處理單個計算機甚至所有機架的失敗。
應用程式
Hadoop的最常見用法之一是Web搜尋。雖然它不是惟一的軟體框架應用程式,但作為一個並行數據處理引擎,它的表現非常突出。Hadoop最有趣的方面之一是MapandReduce流程,它受到Google開發的啟發。這個流程稱為創建索引,它將Web爬行器檢索到的文本Web頁面作為輸入,並且將這些頁面上的單詞的頻率報告作為結果。然後可以在整個Web搜尋過程中使用這個結果從已定義的搜尋參數中識別內容。
MapReduce
最簡單的MapReduce應用程式至少包含3個部分:一個Map函式、一個Reduce函式和一個main函式。main函式將作業控制和檔案輸入/輸出結合起來。在這點上,Hadoop提供了大量的接口和抽象類,從而為Hadoop應用程式開發人員提供許多工具,可用於調試和性能度量等。
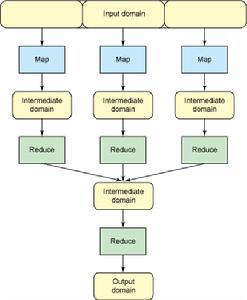 圖 2. MapReduce 流程的概念流
圖 2. MapReduce 流程的概念流這裡提供一個示例,幫助您理解它。假設輸入域是onesmallstepforman,onegiantleapformankind。在這個域上運行Map函式將得出以下的鍵/值對列表:
(one,1)(small,1)(step,1)(for,1)(man,1)
(one,1)(giant,1)(leap,1)(for,1)(mankind,1)
如果對這個鍵/值對列表套用Reduce函式,將得到以下一組鍵/值對:
(one,2)(small,1)(step,1)(for,2)(man,1)
(giant,1)(leap,1)(mankind,1)
結果是對輸入域中的單詞進行計數,這無疑對處理索引十分有用。但是,現在假設有兩個輸入域,第一個是onesmallstepforman,第二個是onegiantleapformankind。您可以在每個域上執行Map函式和Reduce函式,然後將這兩個鍵/值對列表套用到另一個Reduce函式,這時得到與前面一樣的結果。換句話說,可以在輸入域並行使用相同的操作,得到的結果是一樣的,但速度更快。這便是MapReduce的威力;它的並行功能可在任意數量的系統上使用。圖2以區段和疊代的形式演示這種思想。
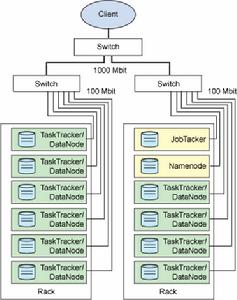 圖 3. 顯示處理和存儲的物理分布的 Hadoop 集群
圖 3. 顯示處理和存儲的物理分布的 Hadoop 集群Hadoop的這個特點非常重要,因為它並沒有將存儲移動到某個位置以供處理,而是將處理移動到存儲。這通過根據集群中的節點數調節處理,因此支持高效的數據處理。
商業領域
Hadoop是一個用於開發分散式應用程式的多功能框架;從不同的角度看待問題是充分利用Hadoop的好方法。回顧一下圖2,那個流程以階梯函式的形式出現,其中一個組件使用另一個組件的結果。當然,它不是萬能的開發工具,但如果碰到的問題屬於這種情況,那么可以選擇使用Hadoop。
Hadoop一直幫助解決各種問題,包括超大型數據集的排序和大檔案的搜尋。它還是各種搜尋引擎的核心,比如Amazon的A9和用於查找酒信息的AbleGrape垂直搜尋引擎。HadoopWiki提供了一個包含大量應用程式和公司的列表,這些應用程式和公司通過各種方式使用Hadoop。
當前,Yahoo擁有最大的HadoopLinux生產架構,共由10,000多個核心組成,有超過5PB位元組的儲存分布到各個DataNode。在它們的Web索引內部差不多有一萬億個連結。不過您可能不需要那么大型的系統,如果是這樣的話,您可以使用AmazonElasticComputeCloud(EC2)構建一個包含20個節點的虛擬集群。事實上,紐約時報使用Hadoop和EC2在36個小時內將4TB的TIFF圖像—包括405K大TIFF圖像,3.3MSGML文章和405KXML檔案—轉換為800K適合在Web上使用的PNG圖像。這種處理稱為雲計算,它是一種展示Hadoop的威力的獨特方式。
另外,阿里巴巴集團在商品推薦、用戶行為分析、信用計算領域也都有hadoop的套用。
區別
Hadoop是Apache軟體基金會發起的一個項目,在大數據分析以及非結構化數據蔓延的背景下,Hadoop受到了前所未有的關注。
Hadoop是一種分散式數據和計算的框架。它很擅長存儲大量的半結構化的數據集。數據可以隨機存放,所以一個磁碟的失敗並不會帶來數據丟失。Hadoop也非常擅長分散式計算——快速地跨多台機器處理大型數據集合。
MapReduce是處理大量半結構化數據集合的編程模型。編程模型是一種處理並結構化特定問題的方式。例如,在一個關係資料庫中,使用一種集合語言執行查詢,如SQL。告訴語言想要的結果,並將它提交給系統來計算出如何產生計算。還可以用更傳統的語言(C++,Java),一步步地來解決問題。這是兩種不同的編程模型,MapReduce就是另外一種。
MapReduce和Hadoop是相互獨立的,實際上又能相互配合工作得很好。
開源實現
Hadoop是項目的總稱。主要是由HDFS和MapReduce組成。
HDFS是GoogleFileSystem(GFS)的開源實現。
MapReduce是GoogleMapReduce的開源實現。
這個分散式框架很有創造性,而且有極大的擴展性,使得Google在系統吞吐量上有很大的競爭力。因此Apache基金會用Java實現了一個開源版本,支持Fedora、Ubuntu等Linux平台。雅虎和矽谷風險投資公司BenchmarkCapital聯合成立一家名為Hortonworks的新公司,接管被廣泛套用的數據分析軟體Hadoop的開發工作。
Hadoop實現了HDFS檔案系統和MapRecue。用戶只要繼承MapReduceBase,提供分別實現Map和Reduce的兩個類,並註冊Job即可自動分散式運行。
至今為止是2.4.1,穩定版本是1.2.1和yarn的2.4.0。
HDFS把節點分成兩類:NameNode和DataNode。NameNode是唯一的,程式與之通信,然後從DataNode上存取檔案。這些操作是透明的,與普通的檔案系統API沒有區別。
MapReduce則是JobTracker節點為主,分配工作以及負責和用戶程式通信。
HDFS和MapReduce實現是完全分離的,並不是沒有HDFS就不能MapReduce運算。
Hadoop也跟其他雲計算項目有共同點和目標:實現海量數據的計算。而進行海量計算需要一個穩定的,安全的數據容器,才有了Hadoop分散式檔案系統(HDFS,HadoopDistributedFileSystem)。
HDFS通信部分使用org.apache.hadoop.ipc,可以很快使用RPC.Server.start()構造一個節點,具體業務功能還需自己實現。針對HDFS的業務則為數據流的讀寫,NameNode/DataNode的通信等。
MapReduce主要在org.apache.hadoop.mapred,實現提供的接口類,並完成節點通信(可以不是hadoop通信接口),就能進行MapReduce運算。
子項目
HadoopCommon:在0.20及以前的版本中,包含HDFS、MapReduce和其他項目公共內容,從0.21開始HDFS和MapReduce被分離為獨立的子項目,其餘內容為HadoopCommon
HDFS:Hadoop分散式檔案系統(DistributedFileSystem)-HDFS(HadoopDistributedFileSystem)
MapReduce:並行計算框架,0.20前使用org.apache.hadoop.mapred舊接口,0.20版本開始引入org.apache.hadoop.mapreduce的新API
HBase:類似GoogleBigTable的分散式NoSQL列資料庫。(HBase和Avro已經於2010年5月成為頂級Apache項目)
Hive:數據倉庫工具,由Facebook貢獻。
Zookeeper:分散式鎖設施,提供類似GoogleChubby的功能,由Facebook貢獻。
Avro:新的數據序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制。
Pig:大數據分析平台,為用戶提供多種接口。
Ambari:Hadoop管理工具,可以快捷的監控、部署、管理集群。
Sqoop:於在HADOOP與傳統的資料庫間進行數據的傳遞。
研究
Hadoop是原Yahoo的DougCutting根據Google發布的學術論文研究而來。DougCutting給這個Project起了個名字,就叫Hadoop。
DougCutting在Cloudera公司任職。Cloudera的Hadoop是商用版。不同於Apache的開源版。
如果要研究Hadoop的話,下載Apache的開源版本是一種不錯的選擇。
只研究Apache版本的,不足以對Hadoop的理念理解。再對Cloudera版本的研究,會更上一層樓。
美國的AsterData,也是Hadoop的一個商用版,AsterData的MPP理念,ApplicationsWithin理念等等,也都是值得研究。
Google的成功已經說明了RDB的下一代就是Nosql(NotOnlySQL),比如說GFS,Hadoop等等。
Hadoop作為開源軟體來說,其魅力更是不可估量。
上文中說到Google的學術論文,其中包涵有:
GoogleFileSystem(大規模分散檔案系統)
MapReduce(大規模分散FrameWork)
BigTable(大規模分散資料庫)
Chubby(分散鎖服務)
大事記
2011年12月27日--1.0.0版本釋出。標誌著Hadoop已經初具生產規模。
2009年4月--贏得每分鐘排序,59秒內排序500GB(在1400個節點上)和173分鐘內排序100TB數據(在3400個節點上)。
2009年3月--17個集群總共24000台機器。
2008年10月--研究集群每天裝載10TB的數據。
2008年4月--贏得世界最快1TB數據排序在900個節點上用時209秒。
2007年4月--研究集群達到兩個1000個節點的集群。
2007年1月--研究集群到達900個節點。
2006年12月--標準排序在20個節點上運行1.8個小時,100個節點3.3小時,500個節點5.2小時,900個節點7.8個小時。
2006年11月--研究集群增加到600個節點。
2006年5月--標準排序在500個節點上運行42個小時(硬體配置比4月的更好)。
2006年5月--雅虎建立了一個300個節點的Hadoop研究集群。
2006年4月--標準排序(10GB每個節點)在188個節點上運行47.9個小時。
2006年2月--雅虎的格線計算團隊採用Hadoop。
2006年2月--ApacheHadoop項目正式啟動以支持MapReduce和HDFS的獨立發展。
2006年1月--DougCutting加入雅虎。
2005年12月--Nutch移植到新的框架,Hadoop在20個節點上穩定運行。
2004年--最初的版本(稱為HDFS和MapReduce)由DougCutting和MikeCafarella開始實施。
認證
Cloudera
Cloudera公司主要提供ApacheHadoop開發工程師認證(ClouderaCertifiedDeveloperforApacheHadoop,CCDH)和ApacheHadoop管理工程師認證(ClouderaCertifiedAdministratorforApacheHadoop,CCAH),更多相關信息,請參閱Cloudera公司官方網站。
Hortonworks
HortonworksHadoop培訓課程是由ApacheHadoop項目的領導者和核心開發人員所設計,代表了這一行業的最高水平。
Hortonworks是國際領先的開發、推廣和支持ApacheHadoop的商業供應商,它的Hadoop認證也是業界公認的Hadoop權威認證,分為開發者認證(HCAHD[10],HortonworksCertifiedApacheHadoopDeveloper)和管理員認證(HCAHA,HortonworkCertifiedApacheHadoopAdministrator)。
信息安全
通過Hadoop安全部署經驗總結,開發出以下十大建議,以確保大型和複雜多樣環境下的數據信息安全。
1、先下手為強!在規劃部署階段就確定數據的隱私保護策略,最好是在將數據放入到Hadoop之前就確定好保護策略。
2、確定哪些數據屬於企業的敏感數據。根據公司的隱私保護政策,以及相關的行業法規和政府規章來綜合確定。
3、及時發現敏感數據是否暴露在外,或者是否導入到Hadoop中。
4、蒐集信息並決定是否暴露出安全風險。
5、確定商業分析是否需要訪問真實數據,或者確定是否可以使用這些敏感數據。然後,選擇合適的加密技術。如果有任何疑問,對其進行加密隱藏處理,同時提供最安全的加密技術和靈活的應對策略,以適應未來需求的發展。
6、確保數據保護方案同時採用了隱藏和加密技術,尤其是如果我們需要將敏感數據在Hadoop中保持獨立的話。
7、確保數據保護方案適用於所有的數據檔案,以保存在數據匯總中實現數據分析的準確性。
8、確定是否需要為特定的數據集量身定製保護方案,並考慮將Hadoop的目錄分成較小的更為安全的組。
9、確保選擇的加密解決方案可與公司的訪問控制技術互操作,允許不同用戶可以有選擇性地訪問Hadoop集群中的數據。
10、確保需要加密的時候有合適的技術(比如Java、Pig等)可被部署並支持無縫解密和快速訪問數據。
Hadoop之父
生活中,可能所有人都間接用過他的作品,
他是Lucene、Nutch、Hadoop等項目的發起人。是他,把高深莫測的搜尋技術形成產品,貢獻給普通大眾;還是他,打造了在雲計算和大數據領域裡如日中天的Hadoop。他是某種意義上的盜火者,他就是DougCutting。
