資料
原出版社: O'Reilly Media 《Hadoop權威指南》
《Hadoop權威指南》叢書名: 清華大學出版社O'Reilly系列
上架時間:2010-5-17
版次:1-1
所屬分類: 計算機 > 計算機科學理論與基礎知識 > 計算理論 > 算法
內容簡介
本書從Hadoop的緣起開始,由淺入深,結合理論和實踐,全方位地介紹Hado叩這一高性能處理海量數據集的理想工具。全書共14章,3個附錄,涉及的主題包括:Haddoop簡介:MapReduce簡介:Hadoop分散式檔案系統;Hadoop的I/O、MapReduce應用程式開發;MapReduce的工作機制:MapReduce的類型和格式;MapReduce的特性:如何安裝Hadoop集群,如何管理Hadoop;Pig簡介:Hbase簡介:zookeeper簡介,最後還提供了豐富的案例分析。
本書是Hadoop權威參考,程式設計師可從中探索如何分析海量數據集,管理員可以從中了解如何安裝與運行Hadoop集群。
什麼是谷歌帝國的基石?MapReduce算法是也!Apache Hadoop架構作為MapReduce算法的一種開源套用,是應對海量數據的理想工具。項目負責人TomWhite透過本書詳細闡述了如何使用Hadoop構建可靠、可伸縮的分散式系統,程式設計師可從中探索如何分析海量數據集,管理員可以從中了解如何安裝和運行Hadoop集群。
本書結合豐富的案例來展示如何用Hadoop解決特殊問題,它將幫助您:
使用Hadoop分散式檔案系統(hdfs)來存儲海量數據集,
通過MapReduce對這些數據集運行分散式計算
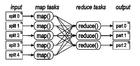 Hadoop運用
Hadoop運用熟悉Hadoop的數據和IlO構件,用於壓縮、數據集成、序列化和持久處理
洞悉編~MapReduce實際套用時的常見陷阱和高級特性
設計、構建和管理一個專用的Hadoop集群或在雲上運行Hadoop
使用高級查詢語言Pig來處理大規模數據
利用Hadoop資料庫HBase來保存和處理結構化/半結構化數據
學會使用ZooKeeper來構建分散式系統
如果您擁有海量數據,無論是GB級還是PB級,Hadoop都將是您的完美解決方案。
目錄
第1章 初識Hadoop 1
1.1 數據!數據 1
1.2 數據的存儲和分析 3
1.3 相較於其他系統 4
1.3.1 關係型資料庫管理系統 5
1.3.2 格線計算 6
1.3.3 志願計算 8
1.4 Hadoop發展簡史 9
1.5 Apache Hadoop項目 12
第2章 MapReduce簡介 15
2.1 一個氣象數據集 15
2.2 使用Unix Tools來分析數據 17
2.3 使用Hadoop進行數據分析 19
2.3.1 map和reduce 19
2.3.2 Java MapReduce 20
2.4 分布化 30
2.4.1 數據流 30
2.4.2 具體定義一個combiner 34
2.4.3 運行分散式MapReduce作業 35
.2.5 Hadoop流 35
2.5.1 Ruby語言 36
2.5.2 Python 38
2.6 Hadoop管道 40
第3章 Hadoop分散式檔案系統 44
3.1 HDFS的設計 44
 Hadoop運用
Hadoop運用3.2 HDFS的概念 45
3.2.1 塊 45
3.2.2 名稱節點與數據節點 47
3.3 命令行接口 48
3.4 Hadoop檔案系統 50
3.5 java接口 54
3.5.1 從Hadoop URL中讀取數據 54
3.5.2 使用FileSystem API讀取數據 56
3.5.3 寫入數據 59
3.5.4 目錄 62
3.5.5 查詢檔案系統 62
3.5.6 刪除數據 67
3.6 數據流 68
3.6.1 檔案讀取剖析 68
3.6.2 檔案寫入剖析 71
3.6.3 一致模型 73
3.7 通過distcp進行並行複製 75
3.9 Hadoop歸檔檔案 77
3.9.1 使用Hadoop Archives 77
3.8.2 不足 79
第4章 Hadoop的I/O 80
4.1 數據完整性 80
4.1.1 HDFS的數據完整性 81
4.1.2 本地檔案系統 82
4.1.3 ChecksumFileSystem 82
4.2 壓縮 83
4.2.1 編碼/解碼器 84
4.2.2 壓縮和輸入分割 89
4.2.3 在MapReduce中使用壓縮 90
4.3 序列化 92
4.3.1 Writable接口 93
4.3.2 Writeable類 96
4.3.3 實現自定義的Writable 104
4.3.4 序列化框架 109
4.4 基於檔案的數據結構 111
4.4.1 SequenceFile類 112
4.4.2 MapFile 120
第5章 MapReduce套用開發 125
5.1 API的配置 126
5.1.1 合併資源 127
5.1.2 各種擴展形式 128
5.2 配置開發環境 128
5.2.1 配置的管理 129
5.2.2 GenericOptionsParser,Tool和ToolRunner 131
5.3 編寫單元測試 134
5.3.1 Mapper 135
5.3.2 reducer 137
5.4 本地運行測試數據 138
5.4.1 在本地作業運行器上運行作業 139
5.4.2 測試驅動程式 142
5.5 在集群上運行 144
5.5.1 打包 144
5.5.2 啟動作業 144
5.5.3 MapReduce網路用戶界面 146
5.5.4 獲取結果 150
5.5.4 調試作業 151
5.5.5 使用遠程調試器 157
5.6 作業調優 159
5.7 MapReduce的工作流 162
5.7.1 將問題分解成MapReduce作業 163
 Hadoop運用
Hadoop運用5.7.2 運行獨立的作業 164
第6章 MapReduce的工作原理 166
6.1 運行MapReduce作業 166
6.1.1 提交作業 166
6.1.2 作業的初始化 168
6.1.3 任務的分配 168
6.1.4 任務的執行 169
6.1.5 進度和狀態的更新 170
6.1.6 作業的完成 171
6.2 失敗 172
6.2.1 任務失敗 172
6.2.2 TaskTracker失敗 174
6.2.3 jobtracker失敗 174
6.3 作業的調度 174
6.4 shuffle和排序 175
6.5.1 map端 176
6.5.2 reduce端 177
6.5.3 配置的調整 178
6.6 任務的執行 181
6.6.1 推測式執行 181
6.6.2 任務JVM重用 183
6.6.3 跳過壞記錄 184
6.6.4 任務執行環境 185
第7章 MapReduce的類型與格式 188
7.1 MapReduce類型 188
7.2 輸入格式 198
7.2.1 輸入分片與記錄 198
7.2.2 文本輸入 210
7.2.3 二進制輸入 214
7.2.4 多種輸入 215
7.2.5 資料庫格式的輸入/輸出 216
7.3 輸出格式 217
7.3.1 文本輸出 217
7.3.2 二進制輸出 218
7.3.3 多個輸出 218
7.3.4 延遲輸出 226
7.3.5 資料庫輸出 226
第8章 MapReduce 特性 227
8.1 計數器 227
8.1.1 內置計數器 227
8.1.2 用戶自定義Java計數器 230
8.1.3 用戶自定義流計數器 235
8.2 排序 235
8.2.1 準備 235
8.2.2 部分排序 237
8.2.3 全局排序 242
8.2.4 二次排序 246
8.3 聯接 252
8.3.1 map端聯接 253
8.3.2 reduce端聯接 254
8.4 次要數據的分布 258
8.4.1 使用作業配置 258
8.4.2 分散式快取 258
8.5 MapReduce的類庫 263
第9章 Hadoop集群的安裝 264
9.1 集群說明 264
9.2 集群的建立和安裝 268
9.2.1 安裝Java 268
9.2.2 創建Hadoop用戶 269
9.2.3 安裝Hadoop 269
9.2.4 測試安裝 270
9.3 SSH配置 270
9.4 Hadoop配置 271
9.4.1 配置管理 271
9.4.2 環境設定 274
9.4.3 重要的Hadoop後台程式屬性 278
9.4.4 Hadoop後台程式地址和連線埠 283
9.4.5 其他Hadoop屬性 284
9.5 安裝之後 286
9.6 Hadoop集群基準測試 286
9.6.1 Hadoop基準測試 287
9.6.2 用戶作業 290
9.7 雲計算中的Hadoop 290
第10章 Hadoop的管理 293
10.1 HDFS 293
10.1.1 持久化的數據結構 293
10.1.2 安全模式 298
10.1.3 審計日誌 300
10.1.4 工具 300
10.2 監控 306
10.2.1 日誌 306
10.2.2 度量 307
10.2.3 Java 管理擴展 310
10.3 維護 313
10.3.1 例行管理程式 313
10.3.2 委託節點和撤消節點 314
10.3.3 升級 317
第11章 Pig簡介 321
11.1 安裝和運行Pig 322
11.1.1 執行類型 322
11.1.2 運行Pig程式 324
11.1.3 Grunt 324
11.1.4 Pig Latin編輯器 325
11.2 實例 325
11.3 與資料庫比較 329
11.4 Pig Latin 330
11.4.1 結構 330
11.4.2 語句 331
11.4.3 表達式 334
11.4.4 類型 335
11.4.5 模式 337
11.4.6 函式 341
11.5 用戶定義函式 343
11.5.1 過濾UDF 343
11.5.2 求值UDF 347
11.5.3 載入UDF 348
11.6 數據處理操作符 353
11.6.1 載入和存儲數據 353
11.6.2 過濾數據 353
11.6.3 數據的分組和聯接 356
11.6.4 數據的排序 361
11.6.5 數據的合併和分割 362
11.7 Pig實踐提示與技巧 363
11.7.1 並行 363
11.7.2 參數替換 364
第12章 Hbase簡介 366
12.1 HBase基礎 366
12.2 概念 367
12.2.1 數據模型速覽 367
12.2.2 實現 368
12.3 安裝 371
12.4 客戶端 374
12.4.1 Java 374
12.4.2 REST和thrift 376
12.5 示例 377
12.5.1 架構 378
12.5.2 載入數據 379
12.5.3. Web查詢 382
12.6 HBase與RDBMS的比較 385
12.6.1 成功的服務 386
12.6.2 HBase 387
12.6.3 用例:streamy.com的Hbase 388
12.7 實踐 390
12.7.1 版本 390
12.7.2 Hbase和HDFS的愛與恨 390
12.7.3 用戶界面 392
12.7.4 度量 392
12.7.5 架構設計 392
第13章 ZooKeeper簡介 394
13.1 ZooKeeper的安裝和運行 395
13.2 範例 396
13.2.1 ZooKeeper中的組成員制 397
13.2.2 創建組 397
13.2.3 加入組 400
13.2.4 列出組成員 401
13.2.5 刪除一個組 404
13.3 ZooKeeper服務 405
 Hadoop運用
Hadoop運用13.3.1 數據模型 405
13.3.2 操作 407
13.3.3 執行 411
13.3.4 一致性 412
13.3.5 會話 414
13.3.6 狀態 416
13.4 使用ZooKeeper建立應用程式 417
13.4.1 配置服務 417
13.4.2 可恢復的ZooKeeper套用 421
13.4.3 鎖服務 425
13.4.4 更多分散式數據結構和協定 427
13.5 工業界中的ZooKeeper 428
13.5.1 恢復力及性能 428
13.5.2 配置 429
第14章 案例研究 431
14.1 Hadoop在Last.fm的套用 431
14.1.1 Last.fm:社會音樂革命 431
14.1.2 使用Hadoop生成排行榜 432
14.1.3 單曲統計程式 433
14.1.4 小結 440
14.2 Hadoop和Hive在Facebook的套用 441
14.2.1 簡介 441
14.2.2 Hadoop在Facebook的套用 441
14.2.3 虛擬案例研究 444
14.2.4 Hive 446
14.2.5 存在的問題及未來的工作 450
14.3 Hadoop在Nutch搜尋引擎 451
14.3.1 背景 451
14.3.2 數據結構 453
14.3.3 Nutch中Hadoop數據處理精選實例 455
14.3.4 小結 465
14.4 Hadoop用於Rackspace的日誌處理 466
14.4.1 需求/存在的問題 466
14.4.2 簡史 467
14.4.3 選擇Hadoop 467
14.4.4 收集和存儲 467
14.4.5 日誌的MapReduce 468
14.5 Cascading項目 474
14.5.1 欄位、元組和管道 475
14.5.2 操作 477
14.5.3 Tap、Sheme和Flow 479
14.5.4 Cascading實踐 480
 Hadoop運用
Hadoop運用14.5.5 靈活性 483
14.5.6 Hadoop和Cascading在ShareThis的套用 484
14.5.7 小結 487
14.6 Apache Hadoop的1 TB排序 488
附錄A Apache Hadoop的安裝 491
附錄B Cloudera的Hadoop分發包 497
附錄C 預備NCDC氣象資料 502
作譯者介紹
Tom White從2007年2月以來,一直擔任Apache Hadoop項目負責人。他是Apache軟體基金會的成員之一,同時也是Cloudera的一名工程師。tome為O’Reilly.com,Java.net以及IBM的developerWorks撰寫過大量文章,並經常在很多行業大會上舉行Hadoop主題演講。.
Cloudera為Hadoop提供商業支持並志願貢獻社區,不收取任何費用。不管是打算在雲中運行Hadoop,還是在自己的伺服器上運行Hadoop,Cloudera都能使其輕鬆實現。
譯者序
隨著數據規模的急劇增加、套用類型的巨大豐富,企業和個人用戶信息使用模式的變化已經遠遠超過了原有系統乎台所提供的局限。越來越多的套用和平台,不論對企業級還是個人級用戶都不堪重負,應接不暇。系統的大集中,企業套用平台的不斷累加;個人用戶桌面套用更是五花八門呈爆炸式增長;sars、5.12和H1N1,傳統數據分析處理領域在面臨新的重大問題時,需要更多領域數據的融合和協作。在這種巨大的潮流和趨勢力的推動下,鳳起“雲”涌。雲計算被推上了計算機科學和套用的舞台,帶來信息使用模式的巨大變革。
我也曾思考,為什麼將其稱為雲,這是一個為用戶禁止了底層異構的軟硬體資源,為其提供服務和資源的平台,各種不同類型的資源經過層層的虛擬化技術之後,針對虛擬資源的分配、共享和使用。是分散式計算技術和信息處理技術,以及網路技術、Web技術等,在架構層、套用層全面融合之後產生的必然結果。SaaS,PaaS,CAAS,IasS,DAAS,雲上的套用種類繁多,仍在發展中,將其定義成雲或者什麼其他都是不重要的,重要的是我們在之上,將數據、軟體和平台等等的複雜構建、安裝和維護工作轉嫁給雲提供商,通過大型的用戶池共享資源來降低基礎設施成本,不同層面的用戶將在雲上輕鬆得到自己想要的,做到thin;client和on.demand service。
Google的App Engine允許用戶通過使用其提供的API,在Google雲上構建自己的套用;Amazon的雲平台EC3,S3等為用戶提供了種類豐富的雲計算服務;Google和IBM聯合宣布推廣“雲計算”的計畫,包括卡內基梅隆大學,斯坦福、伯克利、華盛頓大學、MIT、清華大學都加入了這項計畫。通過這項計畫,高校的研究者能夠更方便地利用Google和IBM的雲計算資源,搭建出各種創新性的套用。未來的雲計算平台中,用戶個人維護的作業系統將被瀏覽器所取代。這使信息工業界面臨一次重新洗牌的機會,我國的軟體技術企業應抓住這個機會為雲計算的本土化市場占領先機,同時學術界也將面臨新的挑戰和機遇。Microsoft感到了來自Google的威脅,微軟MSRA的WebStudio就已經能夠提供在Web規模上快速搭建套用。國內外各種雲計算相關會議和論壇更是不計其數。在這其中,他們都無一例外的將Hadoop作為雲計算中的重要技術之一。
Apache Hadoop作為一個開源項目,克隆了Google運行系統的主要框架,包括檔案系統HDFS、計算架構MapReduce及對於結構化數據處理的HBase等。基於此的其他開源項目,比如Pig,Zookeeper,HIVE等,為Hadoop的使用和系統架構也帶來了更多的福音。目前正在進行Hadoop Avro等,各種工作也將推進Hadoop在雲計算的實現中扮演越來越重要的角色。利用Hadoop,對底層,可以實現對集群的控制和管理;對上層,可以更加便捷的構建企業級的套用。Hadoop實現海量數據的管理和分散式數據處理,使傳統的分散式計算中的數據分割和錯誤管理等複雜問題禁止在於系統本身,從而取得更好的系統伸縮性。使用者可以更多地關注於數據處理本身和對套用問題本身的分析。
本書的作者Tom White是Hadoop開發團體的重要高級成員,是Hadoop項目中許多技術方向的專家,參與了多項Hadoop主要技術方向的設計、改進和實施。他對Hadoop的卓越貢獻,使他成為項目管理委員會成員,並且他是推廣Hadoop開發和使用的專家。
本書內容組織得很好,思路清晰,緊密結合實際問題,閱讀並在實際中實踐本書內容將是一個愉快的、充滿收穫的過程。對於Hadoop的開發使用者深刻全面理解其內部原理、使用以及二次開發,將很有幫助。
Cloudera作為一個商業公司致力乾推廣和培訓Hadoop的使用,這是它出版的第一本Hadoop書籍,頗具代表性和全面性。國外使用這門技術已經比較成熟了,並且發揮了較高經濟效益。
為了推動該技術在國內的普及,讓更多讀者更早受益,本書經過我們精心雕琢而成。在此期間,文開琪編輯為該書的出版付出了非常多的努力和辛勤工作,令人敬佩。由於時間有限、工作繁重,譯著不足紕漏難免,歡迎廣大讀者批評、指正和交流。尾聲:在雲得到了蓬勃的發展和廣泛的機會的同時,我們也該警醒。這時候更加歡迎負面和反對的聲音。關注於雲安全及相關規範的制訂,相關技術的合理使用,以及配套應急措施的實施。只有這樣才能使雲以更低的代價受益於更多的人,對於雲在未來的擴展和推廣,更具有普遍的意義。
曾大聃
前言
馬丁·加德納(數學家和科學作家),曾經在一次採訪中說道:
“沒有微積分,我的生命就失去了意義。這是我成功的秘訣。我花了如此長的時間了解我在寫什麼,所以我知道如何寫作才能讓大多數讀者明白我的意思。”在許多方面,這就是我對Hadoop的感覺。它的內部工作機制是複雜的、相互依賴的,因為它運行在分散式系統的理論、實用技術和技術常識這些複雜的基礎之上。對於門外漢來說,Hadoop就像是異形一樣難以理解。
但事實上並不是這樣的。剝離其核心,Hadoop提供給組件分散式系統的工具——如數據存儲、數據分析和協調一一是十分簡單的。如果有一個共同的主題,那么它將與提高抽象水平相關的一一為程式設計師創建用於處理這些事情的基礎架構,這些程式設計師中,或者正好有大量數據需要存儲,或者有大量數據需要分析。或者有大量機器需要協調,或者沒有時間、技能或興趣成為分散式系統專家。
藉由這樣一個簡單的、普遍適用的功能組合,在開始使用這個理當被廣泛普及的Hadoop的時候,我的想法逐漸清晰起來。然而,在當時(2006年初),設定、配置和編寫程式來使用Hadoop稱得上是一門藝術。幸運的是,此後有了明顯的進步,因為有更多的檔案,更多的例子,一旦有疑問,還有那么多郵件地址可以發過去幫助你解惑。但對大多數新手來說,最大的障礙是理解這項技術能做什麼,它的長處何在,如何使用它。這就是我寫這本書的原因。
恤ache Hadoop社區已經走過了漫長的道路。在三年的過程中,Hadoop項目已經拓展並分成許多子項目。在這個時候,軟體已在性能、可靠性、可擴展性和可管理性上有了很大的飛躍。然而為了獲得更為廣泛地套用,我相信我們需要讓Hadoop變得更容易使用。這將涉及三方面的工作:編寫更多的工具;與更多的系統集成;編寫新的改進後的API。我期待成為完成這項工作的一員,並且我希望這本書也能鼓勵和幫助其他人完成這些事情。
寫作風格的說明
在文中特定Java類的討論中,我往往會省略其包名以減少混亂。如果需要知道一個類是放在哪個包里的,可以輕鬆地從Hadoop的Java APl文檔中查找到有關的子項目,這些條目與Apache Hadoop的主頁http://hadoop.apache.org連結。或者,如果使用的是IDE,它可以幫助使用其自動完成機制。
同樣,雖然它偏離一貫的教學規則,但是從相同的使用星號通配符的包中導入不同的類還是能節省空間的(例如:importorg.apache.hadoop.io.*)。
本書的示例程式可以從本書相關網站下載,網址為http://www.hadoopbook.com/。還可以在此找到獲得本書所用資料庫的指令以及更多運行本書程式的註解、更新連結、其他資源以及我的blog。
本書內容
奉書其餘部分內容如下。第2章介紹MapReduce。第3章著眼於Hadoop的檔案系統,特別深入地講解HDFS。第4章涵蓋Hadoop基礎的I/O輸入和輸出,主題包括:數據的完整性、壓縮、序列化和基於檔案的數據結構。
接下來的4章更深入地涉及MapReduce。第5章講述全程開發一個MapReduce應用程式的實際步驟。第6章著眼於從用戶的觀點來看MapReduce如何在Hadoop上實現。第7章涉及MapReduce編程模型及MapReduce可以處理的各種數據格式。第8章的主題為如何改進MapReduce,包括排序和聯接(JOIN)數據。
第9章和第10章是寫給Hadoop管理員看的,闡述如何建立和維持在Hadoop集群上運行HDFS和MapReduce。
第11章、第12章和第13章分別提供了Pig,HBase和ZooKeeper套用示例。最後,第14章提供ApaheHadoop社區成員貢獻的綜合案例研究。
本書所用約定
本書採用如下印刷約定。
斜體
表示新名詞,URL,電子郵件地址,檔案名稱,檔案擴展名,路徑名,目錄和Unix實用程式。
等寬字型
表示命令、選項、開關、變數、屬性、鍵值,函式、類型、類、命名空間、方法、模組、參數、參數、值、對象、事件、事件句柄、XML標籤、HTML標籤、檔案內容或者命令輸出。
等寬粗體
顯示需要用戶逐字輸入的命令或者其他文字。也用於代碼中的強調。等寬斜體
顯示應該被用戶輸入值代替的文字。
【…】
表示引用參考文獻。
注意:該圖示表示一個技巧,建議或一般註解。
警告:該圖示表示警告或注意事項。
示例代碼的使用
本書的目的是幫助你完成任務。一般來說,可以使用在本書的程式和文檔中的代碼。不需要聯絡我們即可獲得許可,除非是要複製代碼的重要部分。例如,寫一個使用本書幾大塊代碼的程式並不需要經過我們許可。銷售或分發含有來自O’Reilly書籍中的例子的光碟需要許可。回答問題援引本書和引用示例代碼也不需要許可。把本書中的大量示例代碼納入到你的產品文檔需要經過我們許可。
我們對提供著作權說明的說法表示讚賞,但不強求。著作權說明通常包括書名、作者;出版商和ISBN。例如:“Hadoop:TheDefinitiveGuide,Tom著。著作權所有2009Tom White,978-0-596-52197-4。
如果覺得自己使用示例代碼使用上或以上的要求有失公允,請隨時聯繫我們,電子郵件地址為permissions@oreilly.com。
Safari圖書線上
看到Safari圖書線上標識出現在你最喜歡的技術書籍封面上時,便意味著此書(英文版)是可以通過O’Reilly線上書店購買。
Safari提供了一個比電子書更好的解決方案。它提供一個虛擬的圖書館,讓你輕鬆地搜尋數千本頂尖的科技圖書,剪下和貼上代碼示例,下載章節,並按自己的需要最準確、最及時的信息時,能夠尋找到快速解答。免費試用請訪問http://my.safartbooksonline.com。
聯繫我們
對於本書,如果有任何意見或疑問,請按照以下地址聯繫本書出版商:
美國:
O’Reilly Media,Inc.
1005 Gravenstein Highway North
Sebastopol,CA 95472
中國:
北京市西城區西直門南大街2號成銘大廈C座807室(100035)
奧萊利技術諮詢(北京)有限公司
本書也有相關的網頁,我們在上面列出了勘誤表、範例以及其他一些信息。你可以訪問:
http://www, orei!ly, com/catalog/9 780596521974 (中文版)
http://www, oreilly, com. cn/book.php ? bn =9 78- 7-302-22424-2(中文版)
對本書做出評論或者詢問技術問題,請傳送E-mail至:
[email protected]
希望獲得關於本書、會議、資源中心和O’Reilly網路的更多信息,請訪問:
http://www. oreilly.com
http://www. oreilly. com. cn
序言
Hadoop起源於Nutch。當時,我們少數幾個人正在打算構建一個開源的網路搜尋引擎,但受困於如何管理僅運行於幾台計算機的計算。在Google發布GFS和MapRduce的論文後,我們解決這個問題的思路變得清晰起來。他們設計的系統準確解決了我們在Nutch中碰到的問題。因此,我們兩個中途開始嘗試重建這些系統,將其作為Nutch的一部分。
我們成功地讓Nutch運行在20台計算機上,但很快我們意識到,要想處理Web的巨大規模,我們需要在上千台計算機上運行它,顯然,這遠遠不是兩個half-time開發人員能夠對付的。。
在那段時間,Yahoo!對其產生興趣,並迅速組建了一個團隊,我也加入其中。我們將Nutch的分散式運算這部分獨立出來,命名為Hadoop。在Yahoo!的幫助下,Hadoop很快成為確實可擴展套用於Web的技術。
2006年,Tom White開始效力於Hadoop。由於之前已通過他寫的一篇有關Nutch的精彩論文認識他,所以,我知道他能夠用清晰的語言表達複雜的理念。我也很快意識到,他還能編寫體現其思想的軟體。
首先,Tom對Hadoop的貢獻體現了他對用戶和項目的關注。與大多開源工作者不同,Tom並不怎么關心如何將系統調整到更符合他的需求,而是努力使它變得更方便所有人使用。
一開始,Tom著重於使Hadoop在亞馬遜的EC2和S3上順暢運行。而後他轉向各種各樣的問題。包括改進MapReduce的API,改善網站,設計對象序列化框架。在任何時候,Tom都很清晰地表達他的構想。很快,Tom贏得Hadoop項目負責人的身份並很快成為Hadoop項目管理委員會的成員。
現在,Tom是Hadoop開發社區一名令人尊敬的高級成員。儘管他是這個項目的技術多面手,但他最大的專長還是讓Hadoop更易於使用和理解。
因此,當我得知Tom有意寫一本有關Hadoop的書時,我非常開心。還有誰更具備這個資格呢?現在您有此良機向大師學習Hadoop,在享用技術本身的同時,品味他的睿智和清晰的文風。
計算機與網際網路技術圖書
| 計算機與網路圖書:力圖從傳播知識與套用層次談計算機與網際網路,從人文角度介紹相關知識與技術,以客觀的態度,獨特的視角,生動的方式,將重要實用的知識、信息、技能、經驗及時奉獻給讀者。 |
