
模型概念
Logistic回歸模型是分析二分類型變數時常用的非線性統計模型,是最重要且套用最廣泛的非線性模型之一。該模型的因變數為二分類變數(y=0或y=1),結果變數與自變數間是非線性關係。形式如方程(1):
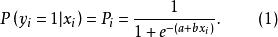 羅吉斯蒂克模型
羅吉斯蒂克模型 羅吉斯蒂克模型
羅吉斯蒂克模型指事件發生的機率,取0~1。
模型優缺點
優點:
第一,對變數要求低,可以接受非常態分配的數據;
第二,總體預測準確率較高;
第三,數據來源直接,操作簡便;
第四,判斷標準明確;
第五,模型穩定,利於推廣創新。
缺點:
第一,大多數時候對ST企業預測準確率較低;
第二,P值臨界點的選擇影響模型預測結果;
第三,違約樣本與正常樣本的比例影響預測結果。
模型原理
 羅吉斯蒂克模型
羅吉斯蒂克模型模型構造的原理簡單來說是運用對數運算將事件發生與否(即事件發生機率 或1)與自變數x間的非線性關係轉化為線性關係。以單一自變數為例,具體轉化步驟如下:
第一步,將上述Logistic模型方程(1)轉化為如下一個非線性方程(2)。
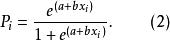 羅吉斯蒂克模型
羅吉斯蒂克模型第二步,方程(2)化簡轉化為如下方程(3)。
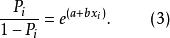 羅吉斯蒂克模型
羅吉斯蒂克模型第三步,方程(3)等式兩邊同時取對數轉化為如下方程(4)。
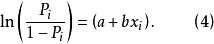 羅吉斯蒂克模型
羅吉斯蒂克模型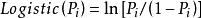 羅吉斯蒂克模型
羅吉斯蒂克模型模型(4)得出 與x間的線性關係方程。
羅吉斯蒂克模型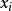 羅吉斯蒂克模型 羅吉斯蒂克模型
羅吉斯蒂克模型 羅吉斯蒂克模型此時, 與 雖然不存線上性關係,但是關於P的函式記作logistic(P)與 存線上性關係。同理,自變數可拓展為m個,則有如下模型方程(5)。
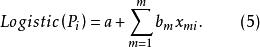 羅吉斯蒂克模型
羅吉斯蒂克模型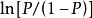 羅吉斯蒂克模型
羅吉斯蒂克模型以上得到的模型同樣可以用來預測事件的發生。預測時根據已知自變數與模型方程得出 ,可以進一步計算事件發生的機率P。P處於0與1之間,越接近1表示發生的機率越大。
模型基本假設
第一,數據必須來自隨機樣本;
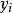 羅吉斯蒂克模型
羅吉斯蒂克模型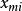 羅吉斯蒂克模型
羅吉斯蒂克模型第二, 為m個自變數 的函式;
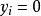 羅吉斯蒂克模型
羅吉斯蒂克模型第三, 或1;
第四,自變數不需要呈常態分配。
模型套用步驟
第一步,選取樣本、確定初始指標;
第二步,篩選指標;
運用SPSS軟體對所有指標進行Kolmogorov-Smirnov常態分配檢驗。符合常態分配的指標進行顯著性T檢驗,不符合常態分配的數據進行Mann-Whitney顯著性檢驗,去除不顯著指標。進行Pearson檢驗,去除與其他指標存在高度相關性的指標。進行多重共線性檢驗,去除與其他指標存在多重共線性的指標;
第三步,進行KMO檢驗,確定是否進行因子分析;
第四步,進行Logistic回歸,得到模型,觀察模型擬合程度及預測準確率;
第五步,用檢驗樣本檢驗模型預測能力;
第六步,利用模型預測事件的發生機率。
模型參數解釋
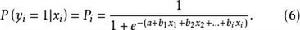 羅吉斯蒂克模型
羅吉斯蒂克模型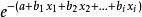 羅吉斯蒂克模型 羅吉斯蒂克模型
羅吉斯蒂克模型 羅吉斯蒂克模型當參數b大於0時,自變數x增大, 減小, 增大;
羅吉斯蒂克模型 羅吉斯蒂克模型當參數b小於0時,自變數x增大, 增大, 減小;
羅吉斯蒂克模型 羅吉斯蒂克模型當參數b等於0時,自變數x增加對 無影響, 不變。
因此,模型參量係數可以反映自變數x與事件發生機率P的關係。係數為正表明自變數x的增長促進事件的發生,係數為負表明自變數x的增長抑制事件的發生。
