概念
圖3.1為一般控制系統的架構,此架構包含了五個主要部分,即:定義變數、模糊化、知識庫、邏輯判斷及反模糊化,下文將對每一部分做簡單的說明:
定義變數
也就是決定程式被觀察的狀況及考慮控制的動作,例如在一般控制問題上,輸入變數有輸出誤差E與輸出誤差變化率EC,而模糊控制還將控制變數作為下一個狀態的輸入U。其中E、EC、U統稱為模糊變數。
模糊化
將輸入值以適當的比例轉換到論域的數值,利用口語化變數來描述測量物理量的過程,根據適合的語言值(linguistic value)求該值相對的隸屬度,此口語化變數稱為模糊子集合(fuzzy subsets)。
知識庫
包括資料庫(data base)與規則庫(rule base)兩部分,其中資料庫提供處理模糊數據的相關定義;而規則庫則藉由一群語言控制規則描述控制目標和策略。
邏輯判斷
模仿人類下判斷時的模糊概念,運用模糊邏輯和模糊推論法進行推論,得到模糊控制訊號。該部分是模糊控制器的精髓所在。
解模糊化
解模糊化(defuzzify):將推論所得到的模糊值轉換為明確的控制訊號,做為系統的輸入值。
函式型式
Mamdani教授最初所用的模糊變數分為連續型和離散型兩種型式,因此隸屬度函式的型式也可以分為連續型與離散型兩種。由於語言變數及相對應隸屬度函式選擇的不同,將形成許多不同的模糊控制器架構;下面將對各隸屬度函式的型式加以介紹:
1. 連續型隸屬度函式
模糊控制器中常見的連續型隸屬度函式有下列三種:
(1)吊鐘形:如圖3.3(a)所示,其隸屬度函式可表示如下:
(2)三角形:如圖3.3(b)所示,其隸屬度函式可表示如下:
(3)梯形:如圖3.3所示,其隸屬度函式之表示法和三角形相類似。
在式中參數a為隸屬度函式中隸屬度為1時的x值,參數W為隸屬度函式涵蓋論域寬窄的程度。而圖中NB,NM,NS,ZO,PS,PM,PB等是論域中模糊集合的標記,其意義如下所示:
NB=負方向大的偏差(Negative Big)
NM=負方向中的偏差(Negative Medium)
NS=負方向小的偏差(Negative Small)
ZO=近於零的偏差(Zero)
PS=正方向小的偏差(Positive Small)
PM=正方向中的偏差(Positive Medium)
PB=正方向大的偏差(Positive Big)
圖上將模糊集合的全集合正規化為區間〔-1,1〕,在模糊控制上,使用標準化的模糊變數,其全集也常正規化,這時之的正規化常數(亦稱為增益常數),也是在設計模糊控制器時必須決定的重要參數。
2. 離散型隸屬度函式
Mamdani教授除了使用連續型全集合之外,也使用了由13個元素所構成的離散合。由於用微處理機計算時使用整數比用〔0,1〕之間的小數更方便,模糊集合的隸屬度均以整數表示,如表3.1所示。
模糊控制理論發展之初,大都採用吊鐘形的隸屬度函式,而近幾年幾乎都已改用三角形的隸屬度函式,這是由於三角形隸屬度函式計算比較簡單,性能與吊鐘形幾乎沒有差別。
控制規則
控制規則是模糊控制器的核心,它的正確與否直接影響到控制器的性能,其數目的多寡也是衡量控制器性能的一個重要因素,下面對控制規則做進一步的探討。
規則來源
模糊控制規則的取得方式:
(1) 專家的經驗和知識
模糊控制也稱為控制系統中的專家系統,專家的經驗和知識在其設計上有餘力的線索。人類在日常生活常中判斷事情,使用語言定性分析多於數值定量分析;而模糊控制規則提供了一個描述人類的行為及決策分析的自然架構;專家的知識通常可用if….then的型式來表述。
藉由詢問經驗豐富的專家,獲得系統的知識,並將知識改為if….then的型式,如此便可構成模糊控制規則。除此之外,為了獲得最佳的系統性能,常還需要多次使用試誤法,以修正模糊控制規則。
(2) 操作員的操作模式
現在流行的專家系統,其想法只考慮知識的獲得。專家可以巧妙地操作複雜的控制對象,但要將專家的訣竅加以邏輯化並不容易,這就需要在控制上考慮技巧的獲得。許多工業系統無法以一般的控制理論做正確的控制,但是熟練的操作人員在沒有數學模式下,卻能夠成功地控制這些系統:這啟發我們記錄操作員的操作模式,並將其整理為if….then的型式,可構成一組控制規則。
(3) 學習
為了改善模糊控制器的性能,必須讓它有自我學習或自我組織的能力,使模糊控制器能夠根據設定的目標,增加或修改模糊控制規則。
規則型式
模糊控制規則的形式主要可分為二種:
(1) 狀態評估模糊控制規則
狀態評估(state evaluation)模糊控制規則類似人類的直覺思考,它被大多數的模糊控制器所使用,其型式如下:
Ri:if x1 is Ai1 and x2 is Ai2 …. and xn is Ain
then y is Ci
其中x1,x2,…….,xn及y為語言變數或稱為模糊變數,代表系統的態變數和控制變數;Ai1,Ai2,….,Ain及Ci為語言值,代表論域中的模糊集合。該形式還有另一種表示法,是將後件部改為系統狀態變數的函式,其形式如下:
Ri:if x1 is Ai1 and x2 is Ai2 …. and xn is Ain
then y=f1(x1,x2,…….,xn)
(2)目標評估模糊控制規則
目標評估(object evaluation)模糊控制規則能夠評估控制目標,並且預測未來控制信號,其形式如下:
Ri:if(U is Ci→(x is A1 and y is B1))then U is Ci
規則流程
實際套用模糊控制時,最初的問題是控制器的設計,即如何設計模糊控制法則。到目前為止模糊控制還沒能像傳統的控制理論一樣,藉由一套發展完整的理論推導來設計。下面簡單介紹一下其設計概念:
圖3.4所示為單輸入和單輸出的定值控制時間回響圖,若使用狀態評估模糊控制規則的形式,前件部變數為輸出的誤差E和在一個取樣周期內E的變化量CE,後件部變數為控制器輸出量U的變化量CU。則誤差、誤差變化量及控制輸出變化量的表示為:
其中E表誤差,R表設定值,Y表系統輸出,U表控制輸出,下標n表在時刻n時的狀態。由此可知,誤差變化量CE是隨輸出Y的斜率的符號變號,當輸出上升時,CE<0, 下降時CE>0。
本文所設計的模糊控制器之輸出輸入關係為:
E,CE→CU
在一般控制的計算法上稱為速度型,這是由於其輸出為U對時間的微分,相當於速度的CU。在構造上也可採用以U為後件部變數的位置型,但前件部變數必需改用E的積分值。
由於由E與CE推論CU的構造中,CU與E的關係恰巧相當於積分關係U(t)=Ki∫E(t)dt,而CU與CE的關係相當於比例關係U(t)=KpE(t)的緣故,所以又稱為Fuzzy PI控制。
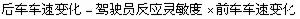 模糊控制
模糊控制設計模糊控制規則時,是在所構想對控制對象各階段的反應,記述採取哪一種控制比較好;首先選擇各階段的特徵點,記錄在模糊控制規則的前件部,然後思考在該點採取的動作,記錄在模糊控制規則的後件部。例如在圖3.6中,在第一循環之a1點附近,誤差為正且大,但誤差變化量幾乎是零,可以記為“E is PB and CE is ZO”在此點附近需要很大的控制輸出,記為”CU is PB”;同樣地,對於b1點、c1點、d1點等的附近,可分別得到如下的控制規則:
a1:If E is PB and CE is ZO then CU is PB
b1:If E is ZO and CE ix NB then XU is NB
c1:If E is NB and CE is ZO then CU is NB
d1:If E is ZO and CE is PB then CU is PB
在第二循環之a2,b2等之附近,其E和CE的絕對值比a1,b1點中之值相對減少,所以其CU值相對地也較小,其控制規則如下:
a2:If E is PM and CE is ZO then CU is PM
b2:If E is ZO and CE is NM then CU is NM
表3.2為依上述程式所構成的13條控制規則,其中縱列為E值,橫列為CE值,表中所列之值為控制輸出變化量CU值。由表3.2可知規則數最多可為49條,此表只使用了其中13條控制規則,設計者可依實際需要自行加減規則之數量,如19條、31條等等(表3.3,3.4所示),以改系統之回響。
特點
簡化系統設計的複雜性,特別適用於非線性、時變、滯後、模型不完全系統的控制。
不依賴於被控對象的精確數學模型。
利用控制法則來描述系統變數間的關係。
不用數值而用語言式的模糊變數來描述系統,模糊控制器不必對被控制對象建立完整的數學模式。
模糊控制器是一語言控制器,便於操作人員使用自然語言進行人機對話。
模糊控制器是一種容易控制、掌握的較理想的非線性控制器,具有較佳的魯棒性、適應性、強健性(Robustness)及較佳的容錯性(Fault Tolerance)。
系統
模糊控制以現代控制理論為基礎,同時與自適應控制技術、人工智慧技術、神經網路技術的相結合,在控制領域得到了空前的套用。
Fuzzy-PID複合控制
Fuzzy-PID複合控制將模糊技術與常規PID控制算法相結合,達到較高的控制精度。當溫度偏差較大時採用Fuzzy控制,回響速度快,動態性能好;當溫度偏差較小時採用PID控制,靜態性能好,滿足系統控制精度。因此它比單個的模糊控制器和單個的PID調節器都有更好的控制性能。
自適應模糊控制
這種控制方法具有自適應自學習的能力,能自動地對自適應模糊控制規則進行修改和完善,提高了控制系統的性能。對於那些具有非線性、大時滯、高階次的複雜系統有著更好的控制性能。
參數自整定模糊控制
也稱為比例因子自整定模糊控制。這種控制方法對環境變化有較強的適應能力,在隨機環境中能對控制器進行自動校正,使得控制系統在被控對象特性變化或擾動的情況下仍能保持較好的性能。
專家模糊控制EFC(Expert Fuzzy Controller)
模糊控制與專家系統技術相結合,進一步提高了模糊控制器智慧型水平。這種控制方法既保持了基於規則方法的價值和用模糊集處理帶來的靈活性,同時把專家系統技術的表達與利用知識的長處結合起來,能夠處理更廣泛的控制問題。
仿人智慧型模糊控制
IC算法具有比例模式和保持模式兩種基本模式的特點。這兩種特點使得系統在誤差絕對值變化時,可處於閉環運行和開環運行兩種狀態。這就能妥善解決穩定性、準確性、快速性的矛盾,較好地套用於純滯後對象。
神經模糊控制(Neuro-Fuzzy Control)
這種控制方法以神經網路為基礎,利用了模糊邏輯具有較強的結構性知識表達能力,即描述系統定性知識的能力、神經網路的強大的學習能力以及定量數據的直接處理能力。
多變數模糊控制
這種控制適用於多變數控制系統。一個多變數模糊控制器有多個輸入變數和輸出變數。
模糊推論
模糊推論
模糊控制理論發展至今,模糊推論的方法大致可分為三種,第一種推論法是依據模糊關係的合成法則,第二種推論法是根據模糊邏輯的推論法簡化而成,第三種推論法和第一種相類似,只是其後件部分改由一般的線性式組成的。模糊推論大都采三段論法,可表示如下:
條件命題:If x is A then y is B
事實:x is A’
結論:y is B’
表示法中的條件命題相當於模糊控制中的模糊控制規則,前件部和後件部的關係,可以用模糊關係式來表達;至於推論演算,則是將模糊關係和模糊集合A’進行合成演算,得到模糊集合B’。推論算法可以下式表示:
B’=A’。R
若前件部分含有多個命題時,則可表示如下:
條件命題:If x1 is A1 …. and xn is An
then y is B
事實:x is A’1 and ….and xn is A’n
結論:y is B’
這種模糊推論法其前件部用“”連結各命題,推論演算的過程則以模糊邏輯來結合前件部中各命題的模糊集合,故前件部的集合A可表示如下:
A=A1∩A2∩…. ∩An
=∩iAi
由(3.7)式可得到模糊集合A和後件部的模糊集合B,利用2.5節中模糊關係R的定義來求得條件命題的模糊關係,其隸屬度函式可用μR(x1,x2,….,xn,y)來表示。同樣地,事實部分的模糊集合A’,亦可表為:
A’=∩iAi
因此,以合成算法可得到推論結果如下:
μB’(y)=μA’(x)。μR(x1,x2,….,xn,y)
本章將針對第一種和第三種推論法做介紹:
(1) 第一種推論法
為Mamdani教授最初所使用的方法,其所用的控制規則如下所述:
R1:If x1 is A11 and
…
and xn is A1n
then y1 is B1
R2:If x1 is A21 and
…
and xn is A2n
then y2 is B2
‧ ‧
‧ ‧
‧ ‧
Rn:If x1 is Am1 and
…
and xn is Amn
then ym is Bm
其中Aij ,B i代表論域中的模糊集合。若使用模糊關係Rc和最大-最小合成的模糊推論,則推論結果可得到模糊集合Bi’的隸屬函式為:
(3.12)式中的值稱為前件部的適合度,因此藉由各條件命題的前件部,便可計算出各條模糊控制規則相對應的適合度。
在實行模糊控制時,將許多條適合的規則進行上述的推論演算,然後結合各個由算法得到的推論結果來獲得模糊集合B’,在此先不談論解模糊化的方法,於下一小節再做討論。
(2)第三種推論法
此種推論法為日本Takagi和Sugano所提出,將Mamdani模糊推論法的命題後件部改為控制器輸出入的線性函式式,其模糊控制規則型式表示如下:
此種型態的模糊控制規則其前件部大多使用梯形隸屬度函式,而後件部的線性函式式亦可使用非線性函式式取代。若算法則為Max-Min合成,則可得到如(3.12)式之適合度;若改採Max-product合成,則可得到上模糊控制規則Ri對應條件命題前件部之適合度,如下所示:
控制規則Ri後件之值Yi可由下列求得:
綜合上述各控制規則得到的推論結果,經解模糊化程式後,便可得到明確的控制器輸出值。
這種模糊控制推論藉由多個線性函式式表示控制器的輸出入關係。將輸入變數空間作模糊分割,並平滑各分割空間接續的地方,而被平滑化的地方即模糊的區域。
解模糊化
在實行模糊控制時,將許多控制規則進行上述推論演算,然後結合各個由演算得到的推論結果獲得控制輸出;為了求得受控系統的輸出,必須將模糊集合B’解模糊化,在此將對三種常用解模糊化的方法做簡單的介紹:
(1)重心法
為模糊控制中段常用的方法,其定義為:
其中y°相當於模糊控制集合B’重心位置,圖3.5、3.6為圖解模糊關係Rc和最大-最小合成及重心法的推論演算過程。
(2) 高度法
亦為時常使用之解模糊化的方法之一,其定義為:
圖3.7為圖解使用高度法計算解模糊化值。
(3) 面積法
與重心法相類似,其定義為:
