
研究綜述
 網路爬蟲
網路爬蟲隨著網路的迅速發展,全球資訊網成為大量信息的載體,如何有效地提取並利用這些信息成為一個巨大的挑戰。搜尋引擎(Search Engine),例如傳統的通用搜尋引擎AltaVista,Yahoo!和Google等,作為一個輔助人們檢索信息的工具成為用戶訪問全球資訊網的入口和指南。但是,這些通用性搜尋引擎也存在著一定的局限性,如:
(1) 不同領域、不同背景的用戶往往具有不同的檢索目的和需求,通用搜尋引擎所返回的結果包含大量用戶不關心的網頁。
(2) 通用搜尋引擎的目標是儘可能大的網路覆蓋率,有限的搜尋引擎伺服器資源與無限的網路數據資源之間的矛盾將進一步加深。
(3) 全球資訊網數據形式的豐富和網路技術的不斷發展,圖片、資料庫、音頻/視頻多媒體等不同數據大量出現,通用搜尋引擎往往對這些信息含量密集且具有一定結構的數據無能為力,不能很好地發現和獲取。
(4) 通用搜尋引擎大多提供基於關鍵字的檢索,難以支持根據語義信息提出的查詢。
為了解決上述問題,定向抓取相關網頁資源的聚焦爬蟲應運而生。聚焦爬蟲是一個自動下載網頁的程式,它根據既定的抓取目標,有選擇的訪問全球資訊網上的網頁與相關的連結,獲取所需要的信息。與通用爬蟲(generalpurpose web crawler)不同,聚焦爬蟲並不追求大的覆蓋,而將目標定為抓取與某一特定主題內容相關的網頁,為面向主題的用戶查詢準備數據資源。
工作原理
 網路爬蟲
網路爬蟲網路爬蟲是一個自動提取網頁的程式,它為搜尋引擎從全球資訊網上下載網頁,是搜尋引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件,流程圖所示。聚焦爬蟲的工作流程較為複雜,需要根據一定的網頁分析算法過濾與主題無關的連結,保留有用的連結並將其放入等待抓取的URL佇列。然後,它將根據一定的搜尋策略從佇列中選擇下一步要抓取的網頁URL,並重複上述過程,直到達到系統的某一條件時停止,如圖1(b)所示。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,並建立索引,以便之後的查詢和檢索;對於聚焦爬蟲來說,這一過程所得到的分析結果還可能對以後的抓取過程給出反饋和指導。
相對於通用網路爬蟲,聚焦爬蟲還需要解決三個主要問題:
(1) 對抓取目標的描述或定義;
(2) 對網頁或數據的分析與過濾;
(3) 對URL的搜尋策略。
抓取目標的描述和定義是決定網頁分析算法與URL搜尋策略如何制訂的基礎。而網頁分析算法和候選URL排序算法是決定搜尋引擎所提供的服務形式和爬蟲網頁抓取行為的關鍵所在。這兩個部分的算法又是緊密相關的。
抓取目標
現有聚焦爬蟲對抓取目標的描述可分為基於目標網頁特徵、基於目標數據模式和基於領域概念3種。
基於目標網頁特徵的爬蟲所抓取、存儲並索引的對象一般為網站或網頁。根據種子樣本獲取方式可分為:
1) 預先給定的初始抓取種子樣本;
2) 預先給定的網頁分類目錄和與分類目錄對應的種子樣本,如Yahoo!分類結構等;
3) 通過用戶行為確定的抓取目標樣例,分為:
a) 用戶瀏覽過程中顯示標註的抓取樣本;
b) 通過用戶日誌挖掘得到訪問模式及相關樣本。
其中,網頁特徵可以是網頁的內容特徵,也可以是網頁的連結結構特徵,等等。
現有的聚焦爬蟲對抓取目標的描述或定義可以分為基於目標網頁特徵,基於目標數據模式和基於領域概念三種。
基於目標網頁特徵的爬蟲所抓取、存儲並索引的對象一般為網站或網頁。具體的方法根據種子樣本的獲取方式可以分為:(1)預先給定的初始抓取種子樣本;(2)預先給定的網頁分類目錄和與分類目錄對應的種子樣本,如Yahoo!分類結構等;(3)通過用戶行為確定的抓取目標樣例。其中,網頁特徵可以是網頁的內容特徵,也可以是網頁的連結結構特徵,等等。
爬蟲技術研究綜述
基於目標數據模式的爬蟲針對的是網頁上的數據,所抓取的數據一般要符合一定的模式,或者可以轉化或映射為目標數據模式。
另一種描述方式是建立目標領域的本體或詞典,用於從語義角度分析不同特徵在某一主題中的重要程度。
網頁搜尋策略
網頁的抓取策略可以分為深度優先、廣度優先和最佳優先三種。深度優先在很多情況下會導致爬蟲的陷入(trapped)問題,目前常見的是廣度優先和最佳優先方法。
廣度優先搜尋策略
廣度優先搜尋策略是指在抓取過程中,在完成當前層次的搜尋後,才進行下一層次的搜尋。該算法的設計和實現相對簡單。在目前為覆蓋儘可能多的網頁,一般使用廣度優先搜尋方法。也有很多研究將廣度優先搜尋策略套用於聚焦爬蟲中。其基本思想是認為與初始URL在一定連結距離內的網頁具有主題相關性的機率很大。另外一種方法是將廣度優先搜尋與網頁過濾技術結合使用,先用廣度優先策略抓取網頁,再將其中無關的網頁過濾掉。這些方法的缺點在於,隨著抓取網頁的增多,大量的無關網頁將被下載並過濾,算法的效率將變低。
最佳優先搜尋策略
最佳優先搜尋策略按照一定的網頁分析算法,預測候選URL與目標網頁的相似度,或與主題的相關性,並選取評價最好的一個或幾個URL進行抓取。它只訪問經過網頁分析算法預測為“有用”的網頁。存在的一個問題是,在爬蟲抓取路徑上的很多相關網頁可能被忽略,因為最佳優先策略是一種局部最優搜尋算法。因此需要將最佳優先結合具體的套用進行改進,以跳出局部最優點。將在第4節中結合網頁分析算法作具體的討論。研究表明,這樣的閉環調整可以將無關網頁數量降低30%~90%。
網頁分析算法
網頁分析算法可以歸納為基於網路拓撲、基於網頁內容和基於用戶訪問行為三種類型。
基於網路拓撲的分析算法
基於網頁之間的連結,通過已知的網頁或數據,來對與其有直接或間接連結關係的對象(可以是網頁或網站等)作出評價的算法。又分為網頁粒度、網站粒度和網頁塊粒度這三種。
網頁(Webpage)粒度的分析算法
PageRank和HITS算法是最常見的連結分析算法,兩者都是通過對網頁間連結度的遞歸和規範化計算,得到每個網頁的重要度評價。PageRank算法雖然考慮了用戶訪問行為的隨機性和Sink網頁的存在,但忽略了絕大多數用戶訪問時帶有目的性,即網頁和連結與查詢主題的相關性。針對這個問題,HITS算法提出了兩個關鍵的概念:權威型網頁(authority)和中心型網頁(hub)。
基於連結的抓取的問題是相關頁面主題團之間的隧道現象,即很多在抓取路徑上偏離主題的網頁也指向目標網頁,局部評價策略中斷了在當前路徑上的抓取行為。文獻提出了一種基於反向連結(BackLink)的分層式上下文模型(Context Model),用於描述指向目標網頁一定物理跳數半徑內的網頁拓撲圖的中心Layer0為目標網頁,將網頁依據指向目標網頁的物理跳數進行層次劃分,從外層網頁指向內層網頁的連結稱為反向連結。
網站粒度的分析算法
網站粒度的資源發現和管理策略也比網頁粒度的更簡單有效。網站粒度的爬蟲抓取的關鍵之處在於站點的劃分和站點等級(SiteRank)的計算。SiteRank的計算方法與PageRank類似,但是需要對網站之間的連結作一定程度抽象,並在一定的模型下計算連結的權重。
網站劃分情況分為按域名劃分和按IP位址劃分兩種。在分散式情況下,通過對同一個域名下不同主機、伺服器的IP位址進行站點劃分,構造站點圖,利用類似PageRank的方法評價SiteRank。同時,根據不同檔案在各個站點上的分布情況,構造文檔圖,結合SiteRank分散式計算得到DocRank。利用分散式的SiteRank計算,不僅大大降低了單機站點的算法代價,而且克服了單獨站點對整個網路覆蓋率有限的缺點。附帶的一個優點是,常見PageRank 造假難以對SiteRank進行欺騙。
網頁塊粒度的分析算法
在一個頁面中,往往含有多個指向其他頁面的連結,這些連結中只有一部分是指向主題相關網頁的,或根據網頁的連結錨文本表明其具有較高重要性。但是,在PageRank和HITS算法中,沒有對這些連結作區分,因此常常給網頁分析帶來廣告等噪聲連結的干擾。在網頁塊級別(Blocklevel)進行連結分析的算法的基本思想是通過VIPS網頁分割算法將網頁分為不同的網頁塊(page block),然後對這些網頁塊建立pagetoblock和blocktopage的連結矩陣,分別記為Z和X。於是,在pagetopage圖上的網頁塊級別的PageRank為Wp=X×Z;在blocktoblock圖上的BlockRank為Wb=Z×X。已經有人實現了塊級別的PageRank和HITS算法,並通過實驗證明,效率和準確率都比傳統的對應算法要好。
基於網頁內容的網頁分析算法
基於網頁內容的分析算法指的是利用網頁內容(文本、數據等資源)特徵進行的網頁評價。網頁的內容從原來的以超文本為主,發展到後來動態頁面(或稱為hidden web)數據為主,後者的數據量約為直接可見頁面數據(PIW,Publicly Indexable Web)的400~500倍。另一方面,多媒體數據、Web Service等各種網路資源形式也日益豐富。因此,基於網頁內容的分析算法也從原來的較為單純的文本檢索方法,發展為涵蓋網頁數據抽取、機器學習、數據挖掘、語義理解等多種方法的綜合套用。本節根據網頁數據形式的不同,將基於網頁內容的分析算法,歸納以下三類:第一種針對以文本和超連結為主的無結構或結構很簡單的網頁;第二種針對從結構化的數據源(如RDBMS)動態生成的頁面,其數據不能直接批量訪問;第三種針對的數據界於第一和第二類數據之間,具有較好的結構,顯示遵循一定模式或風格,且可以直接訪問。
基於文本的網頁分析算法
1) 純文本分類與聚類算法
很大程度上借用了文本檢索的技術。文本分析算法可以快速有效的對網頁進行分類和聚類,但是由於忽略了網頁間和網頁內部的結構信息,很少單獨使用。
2) 超文本分類和聚類算法
補充
這些處理被稱為網路抓取或者蜘蛛爬行。很多站點,尤其是搜尋引擎,都使用爬蟲提供最新的數據,它主要用於提供它訪問過頁面的一個副本,然後,搜尋引擎就可以對得到的頁面進行索引,以提供快速的訪問。蜘蛛也可以在web上用來自動執行一些任務,例如檢查連結,確認html代碼;也可以用來抓取網頁上某種特定類型信息,例如抓取電子郵件地址(通常用於垃圾郵件)。一個網路蜘蛛就是一種機器人,或者軟體代理。大體上,它從一組要訪問的URL連結開始,可以稱這些URL為種子。爬蟲訪問這些連結,它辨認出這些頁面的所有超連結,然後添加到這個URL列表,可以稱作檢索前沿。這些URL按照一定的策略反覆訪問。
主要內容
·1爬行策略
o1.1選擇策略
§1.1.1限定訪問連結
§1.1.2路徑檢索
§1.1.3聚焦檢索
§1.1.4抓取深層的網頁
§1.1.5Web3.0檢索
o1.2重新訪問策略
o1.3平衡禮貌策略
o1.4並行化策略
2網路爬蟲體系結構
2.1URL規範化
3爬蟲身份識別
4網路爬蟲的例子
o4.1開源的網路爬蟲
1.爬行策略
下述的三種網路特徵,造成了設計網頁爬蟲抓取策略變得很難:
它巨大的數據量;
它快速的更新頻率;
動態頁面的產生
它們三個特徵一起產生了很多種類的爬蟲抓取連結。
巨大的數據量暗示了爬蟲,在給定的時間內,只可以抓取所下載網路的一部分,所以,它需要對它的抓取頁面設定優先權;快速的更新頻率說明在爬蟲抓取下載某網站一個網頁的時候,很有可能在這個站點又有很的網頁被添加進來,或者這個頁面被更新或者刪除了。
最近新增的很多頁面都是通過伺服器端腳本語言產生的,無窮的參數組合也增加了爬蟲抓取的難度,只有一小部分這種組合會返回一些獨特的內容。例如,一個很小照片存儲庫僅僅通過get方式可能提供就給用戶三種操作方式。如果這裡存著四種分類方式,三種縮略圖方式,兩種檔案格式,和一個禁止用戶提供內容的選項,那么,同樣的內容就可以通過48種方式訪問。這種數學組合給網路爬蟲創造的難處就是,為了獲取不同的內容,他們必須篩選無窮僅有微小變化的組合。
正如愛德華等人所說的:“用於檢索的頻寬不是無限的,也不是免費的;所以,如果引入衡量爬蟲抓取質量或者新鮮度的有效指標的話,不但伸縮性,連有效性都將變得十分必要”(愛德華等人,2001年)。一個爬蟲就必須小心的選擇下一步要訪問什麼頁面。網頁爬蟲的行為通常是四種策略組合的結果。
♦選擇策略,決定所要下載的頁面;
♦重新訪問策略,決定什麼時候檢查頁面的更新變化;
♦平衡禮貌策略,指出怎樣避免站點超載;
♦並行策略,指出怎么協同達到分散式抓取的效果;
1.1選擇策略:
就現在網路資源的大小而言,即使很大的搜尋引擎也只能獲取網路上可得到資源的一小部分。由勞倫斯河蓋爾斯共同做的一項研究指出,沒有一個搜尋引擎抓取的內容達到網路的16%(勞倫斯河蓋爾斯,2001)。網路爬蟲通常僅僅下載網頁內容的一部分,但是大家都還是強烈要求下載的部分包括最多的相關頁面,而不僅僅是一個隨機的簡單的站點。
這就要求一個公共標準來區分網頁的重要程度,一個頁面的重要程度與他自身的質量有關,與按照連結數、訪問數得出的受歡迎程度有關,甚至與他本身的網址(後來出現的把搜尋放在一個頂級域名或者一個固定頁面上的垂直搜尋)有關。設計一個好的搜尋策略還有額外的困難,它必須在不完全信息下工作,因為整個頁面的集合在抓取時是未知的。
Cho等人(Choetal,1998)做了第一份抓取策略的研究。他們的數據是史丹福大學網站中的18萬個頁面,使用不同的策略分別模仿抓取。排序的方法使用了廣度優先,後鏈計數,和部分pagerank算法。計算顯示,如果你想要優先下載pagerank高的頁面,那么,部分PageRank策略是比較好的,其次是廣度優先和後鏈計數。並且,這樣的結果僅僅是針對一個站點的。
Najork和Wiener(NajorkandWiener,2001)採用實際的爬蟲,對3.28億個網頁,採用廣度優先研究。他們發現廣度優先會較早的抓到PageRank高的頁面(但是他們沒有採用其他策略進行研究)。作者給出的解釋是:“最重要的頁面會有很多的主機連線到他們,並且那些連結會較早的發現,而不用考慮從哪一個主機開始。”
Abiteboul(Abiteboul等人,2003),設計了一種基於OPIC(線上頁面重要指數)的抓取戰略。在OPIC中,每一個頁面都有一個相等的初始權值,並把這些權值平均分給它所指向的頁面。這種算法與Pagerank相似,但是他的速度很快,並且可以一次完成。OPIC的程式首先抓取獲取權值最大的頁面,實驗在10萬個冪指分布的模擬頁面中進行。並且,實驗沒有和其它策略進行比較,也沒有在真正的WEB頁面測試。
Boldi等人(Boldietal.,2004)的模擬檢索實驗進行在從.it網路上取下的4000萬個頁面和從webbase得到的1億個頁面上,測試廣度優先和深度優先,隨機序列和有序序列。比較的基礎是真實頁面pageRank值和計算出來的pageRank值的接近程度。令人驚奇的是,一些計算pageRank很快的頁面(特別明顯的是廣度優先策略和有序序列)僅僅可以達到很小的接近程度。
Baeza-Yates等人(Baeza-Yatesetal.,2005)在從.gr域名和.cl域名子網站上獲取的300萬個頁面上模擬實驗,比較若干個抓取策略。結果顯示OPIC策略和站點佇列長度,都比廣度優先要好;並且如果可行的話,使用之前的爬行抓取結果來指導這次抓取,總是十分有效的。
Daneshpajouh等人(Daneshpajouhetal.,2008)設計了一個用於尋找好種子的社區。它們從來自不同社區的高PageRank頁面開始檢索的方法,疊代次數明顯小於使用隨機種子的檢索。使用這種方式,可以從以前抓取頁面之中找到好的種子,使用這些種子是十分有效的。
1.1.1限定訪問連結
一個爬蟲可能僅僅想找到html頁面的種子而避免其他的檔案類型。為了僅僅得到html的資源,一個爬蟲可以首先做一個httphead的請求,以在使用request方法獲取所有的資源之前,決定這個網路檔案的類型。為了避免要傳送過多的head請求,爬蟲可以交替的檢查url並且僅僅對以html,htm和反斜槓結尾的檔案傳送資源請求。這種策略會導致很多的html資源在無意中錯過,一種相似的策略是將網路資源的擴展名同已知是html檔案類型的一組擴展名(如.html,.htm,.asp,.php,.aspx,反斜槓)進行比較。
一些爬蟲也會限制對任何含有“?”的資源(這些是動態生成的)進行獲取請求,以避免蜘蛛爬行在某一個站點中陷入下載無窮無盡的URL的困境。
1.1.2路徑檢索
一些爬蟲會儘可能多的嘗試下載一個特定站點的資源。Cothey(Cothey,2004)引入了一種路徑檢索的爬蟲,它會嘗試抓取需要檢索資源的所有URL。例如,給定一個種子地址:它將會嘗試檢索/hamster/menkey/,/hamster/和/。Cothey發現路徑檢索對發現獨立資源,或者一些通常爬蟲檢索不到的的連線是非常有效的。
一些路徑檢索的爬蟲也被稱為收割機軟體,因為他們通常用於收割或者收集所有的內容,可能是從特定的頁面或者主機收集相冊的照片。
1.1.3聚焦抓取
爬蟲所抓取頁面的重要程度也可以表述成它與給定查詢之間相似程度的函式。網路爬蟲嘗試下載相似頁面,可以稱為聚焦檢索或者主題檢索。關於主題檢索和聚焦檢索的概念,最早是由Menczer(Menczer1997;MenczerandBelew,1998)和Chakrabarti等人首先提出來的(Chakrabartietal.,1999)。
聚焦檢索的主要問題是網頁爬蟲的使用環境,我們希望在實際下載頁面之前,就可以知道給定頁面和查詢之間的相似度。一個可能的方法就是在連結之中設定錨點,這就是在早期時候,Pinkerton(Pinkerton,1994)曾經在一個爬蟲中採用的策略。Diligenti等人(Diligenti等人,2000)建議使用已經抓取頁面的內容去推測查詢和未訪問頁的相似度。一個聚焦查詢的表現的好壞主要依賴於查詢主題內容的豐富程度,通常還會依賴頁面查詢引擎提供的查詢起點。
1.1.4抓取深層的網頁
很多的頁面隱藏的很深或隱藏在在看不到的網路之中。這些頁面通常只有在向資料庫提交查詢的時候才可以訪問到,如果沒有連結指向他們的話,一般的爬蟲是不能訪問到這些頁面的。谷歌站點地圖協定和modoai(Nelson等人,2005)嘗試允許發現這些深層次的資源。
深層頁面抓取器增加了抓取網頁的連結數。一些爬蟲僅僅抓取形如<ahref=”url”連結。某些情況下,例如Googlebot,WEB抓取的是所有超文本所包含的內容,標籤和文本。
1.1.5WEB3.0檢索
Web3.0為下一代搜尋技術定義了更先進的技術和新的準則,可以概括為語義網路和網站模板解析的概念。第三代檢索技術將建立在人機巧妙的聯繫的基礎上。
1.2重新訪問策略
網路具有動態性很強的特性。抓取網路上的一小部分內容可能會花費真的很長的時間,通常用周或者月來衡量。當爬蟲完成它的抓取的任務以後,很多操作是可能會發生的,這些操作包括新建,更新和刪除。
從搜尋引擎的角度來看,不檢測這些事件是有成本的,成本就是我們僅僅擁有一份過時的資源。最常使用的成本函式,是新鮮度和過時性(2000年,Cho和Garcia-Molina)
新鮮度:這是一個衡量抓取內容是不是準確的二元值。在時間t內,倉庫中頁面p的新鮮度是這樣定義的:
過時性:這是一個衡量本地已抓取的內容過時程度的指標。在時間t時,倉庫中頁面p的時效性的定義如下:
在頁面抓取中,新鮮度和過時性的發展
Coffman等人(EdwardG.Coffman,1998)是從事爬蟲對象定義的,他們提出了一個相當於新鮮度的概念,但是使用了不同的措詞:他們建議爬蟲必須最小化過時頁面部分。他們指出網路爬行的問題就相當於多個佇列,一個投票系統;這裡,爬蟲是伺服器,不同的站點是佇列。頁面修改是到達的顧客,頁面切換的時間是頁面進入一個單一站點的間隔。在這個模型下,每一個顧客在投票系統的平均時間,相當於爬蟲的平均過時性。
爬蟲的目標是儘可能高的提高頁面的新鮮度,同時降低頁面的過時性。這一目標並不是完全一樣的,第一種情況,爬蟲關心的是有多少頁面時過時的;在第二種情況,爬蟲關心的頁面過時了多少。
兩種最簡單的重新訪問策略是由Cho和Garcia-Molina研究的(Cho和Garcia-Molina,2003):
統一策略:使用相同的頻率,重新訪問收藏中的所有的連結,而不考慮他們更新頻率。
正比策略:對變化越多的網頁,重新訪問的頻率也越高。網頁訪問的頻率和網頁變化的頻率直接相關。
(兩種情況下,爬蟲的重新抓取都可以採用隨機方式,或者固定的順序)
Cho和Garcia-Molina證明了一個出人意料的結果。以平均新鮮度方式衡量,統一策略在模擬頁面和真實的網路抓取中都比正比策略出色。對於這種結果的解釋是:當一個頁面變化太快的時候,爬蟲將會將會在不斷的嘗試重新抓取而浪費很多時間,但是卻還是不能保證頁面的新鮮度。
為了提高頁面的新鮮度,我們應該宣判變化太快的頁面死罪(Cho和Garcia-Molina,2003a)。最佳的重新訪問策略既不是統一策略,也不是正比策略;保持平均頁面新鮮度高的最佳方法策略包括忽略那些變化太快的頁面,而保持頁面平均過時性低的方法則是對每一頁按照頁面變化率單調變化的策略訪問。兩種情況下,最佳的策略較正比策略,都更接近統一策略。正如Coffman等人(EdwardG.Coffman,1998)所注意到的:“為了最小化頁面過時的時間,對任一個頁面的訪問都應該儘可能的均勻間隔地訪問。”對於重新訪問的詳盡的策略在大體上是不可以達到的,但是他們可以從數學上得到,因為他們依賴於頁面的變化。(Cho和Garcia-Molina,2003a)指出指數變化是描述頁面變化的好方法,同時(Ipeirotis等人,2005)指出了怎么使用統計工具去發現適合這些變化的參數。注意在這裡的重新訪問策略認為每一個頁面都是相同的(網路上所有的頁面價值都是一樣的)這不是現實的情況,所以,為了獲取更好的抓取策略,更多有關網頁質量的信息應該考慮進去。
1.3平衡禮貌策略
爬蟲相比於人,可以有更快的檢索速度和更深的層次,所以,他們可能使一個站點癱瘓。不需要說一個單獨的爬蟲一秒鐘要執行多條請求,下載大的檔案。一個伺服器也會很難回響多執行緒爬蟲的請求。
就像Koster(Koster,1995)所注意的那樣,爬蟲的使用對很多工作都是很有用的,但是對一般的社區,也需要付出代價。使用爬蟲的代價包括:
網路資源:在很長一段時間,爬蟲使用相當的頻寬高度並行地工作。
伺服器超載:尤其是對給定伺服器的訪問過高時。
質量糟糕的爬蟲,可能是伺服器或者路由器癱瘓,或者會嘗試下載自己無法處理的頁面。
個人爬蟲,如果過多的人使用,可能是網路或者伺服器阻塞。
對這些問題的一個部分解決方法是漫遊器排除協定(Robotsexclusionprotocol),也被稱為robots.txt議定書(Koster,1996),這份協定對於管理員指明網路伺服器的那一部分不能到達是一個標準。這個標準沒有包括重新訪問一台伺服器的間隔的建議,雖然訪問間隔是避免伺服器超載的最有效的辦法。最近的商業搜尋軟體,如AskJeeves,MSN和Yahoo可以在robots.txt中使用一個額外的“Crawl-delay”參數來指明請求之間的延遲。
對連線間隔時間的第一個建議由Koster1993年給出,時間是60秒。按照這個速度,如果一個站點有超過10萬的頁面,即使我們擁有零延遲和無窮頻寬的完美連線,它也會需要兩個月的時間來下載整個站點,並且,這個伺服器中的資源,只有一小部分可以使用。這似乎是不可以接受的。
Cho(Cho和Garcia-Molina,2003)使用10秒作為訪問的間隔時間,WIRE爬蟲(Baeza-YatesandCastillo,2002)使用15秒作為默認間隔。MercatorWeb(Heydon和Najork,1999)爬蟲使用了一種自適應的平衡策略:如果從某一伺服器下載一個文檔需要t秒鐘,爬蟲就等待10t秒的時間,然後開始下一個頁面。Dill等人(Dilletal.,2002)使用1秒。
對於那些使用爬蟲用於研究目的的,一個更詳細的成本-效益分析是必要的,當決定去哪一個站點抓取,使用多快的速度抓取的時候,倫理的因素也需要考慮進來。
訪問記錄顯示已知爬蟲的訪問間隔從20秒鐘到3-4分鐘不等。需要注意的是即使很禮貌,採取了所有的安全措施來避免伺服器超載,還是會引來一些網路伺服器管理員的抱怨的。Brin和Page注意到:運行一個針對超過50萬伺服器的爬蟲,會產生很多的郵件和電話。這是因為有無數的人在上網,而這些人不知道爬蟲是什麼,因為這是他們第一次見到。(Brin和Page,1998)
1.4並行策略
一個並行爬蟲是並行運行多個進程的爬蟲。它的目標是最大化下載的速度,同時儘量減少並行的開銷和下載重複的頁面。為了避免下載一個頁面兩次,爬蟲系統需要策略來處理爬蟲運行時新發現的URL,因為同一個URL地址,可能被不同的爬蟲進程抓到。
2.網路爬蟲體系結構
網頁爬蟲的高層體系結構
一個爬蟲不能像上面所說的,僅僅只有一個好的抓取策略,還需要有一個高度最佳化的結構。
Shkapenyuk和Suel(Shkapenyuk和Suel,2002)指出:設計一個短時間內,一秒下載幾個頁面的頗慢的爬蟲是一件很容易的事情,而要設計一個使用幾周可以下載百萬級頁面的高性能的爬蟲,將會在系統設計,I/O和網路效率,健壯性和易用性方面遇到眾多挑戰。
網路爬蟲是搜尋引擎的核心,他們算法和結構上的細節被當作商業機密。當爬蟲的設計發布時,總會有一些為了阻止別人複製工作而缺失的細節。人們也開始關注主要用於阻止主要搜尋引擎發布他們的排序算法的“搜尋引擎垃圾郵件”。
2.1URL一般化
爬蟲通常會執行幾種類型的URL規範化來避免重複抓取某些資源。URL一般化也被稱為URL標準化,指的是修正URL並且使其前後一致的過程。這裡有幾種一般化方法,包括轉化URL為小寫的,去除逗號(如‘.’‘..’等),對非空的路徑,在末尾加反斜槓。
3.爬蟲身份識別
網路爬蟲通過使用http請求的用戶代理欄位來向網路伺服器表明他們的身份。網路管理員則通過檢查網路伺服器的日誌,使用用戶代理欄位來辨認哪一個爬蟲曾經訪問過以及它訪問的頻率。用戶代理欄位可能會包含一個可以讓管理員獲取爬蟲更多信息的URL。郵件抓取器和其他懷有惡意的網路爬蟲通常不會留任何的用戶代理欄位內容,或者他們也會將他們的身份偽裝成瀏覽器或者其他的知名爬蟲。
對於網路爬蟲,留下用戶標誌信息是十分重要的;這樣,網路管理員在需要的時候就可以聯繫爬蟲的主人。有時,爬蟲可能會陷入爬蟲陷阱或者是一個伺服器超負荷,這時,爬蟲主人需要使爬蟲停止。對那些有興趣了解特定爬蟲訪問時間網路管理員來講,用戶標識信息是十分重要的。
4.用戶爬蟲的例子
以下是一系列已經發布的一般用途的網路爬蟲(除了主題檢索的爬蟲)的體系結構,包括了對不同組件命名和突出特點的簡短的描述。
RBSE(Eichmann,1994)是第一個發布的爬蟲。它有兩個基礎程式。第一個是“spider”,抓取佇列中的內容到一個關係資料庫中,第二個程式是“mite”,是一個修改後的www的ASCII瀏覽器,負責從網路上下載頁面。
WebCrawler(Pinkerton,1994)是第一個公開可用的用來建立全文索引的一個子程式,他使用庫www來下載頁面;另外一個程式使用廣度優先來解析獲取URL並對其排序;它還包括一個根據選定文本和查詢相似程度爬行的實時爬蟲。
WorldWideWebWorm(McBryan,1994)是一個用來為檔案建立包括標題和URL簡單索引的爬蟲。索引可以通過grep式的Unix命令來搜尋。
GoogleCrawler(BrinandPage,1998)用了一些細節來描述,但是這些細節僅僅是關於使用C++和Python編寫的、一個早期版本的體系結構。因為文本解析就是全文檢索和URL抽取的過程,所以爬蟲集成了索引處理。這裡擁有一個URL伺服器,用來給幾個爬蟲程式傳送要抓取的URL列表。在文本解析的時候,新發現的URL傳送給URL伺服器並檢測這個URL是不是已經存在,如果不存在的話,該URL就加入到URL伺服器中。
CobWeb(daSilvaetal.,1999)使用了一個中央“調度者”和一系列的“分散式的蒐集者”。蒐集者解析下載的頁面並把找到的URL傳送給調度者,然後調度者反過來分配給蒐集者。調度者使用深度優先策略,並且使用平衡禮貌策略來避免伺服器超載。爬蟲是使用Perl語言編寫的。
Mercator(HeydonandNajork,1999;NajorkandHeydon,2001)是一個分散式的,模組化的使用java編寫的網路爬蟲。它的模組化源自於使用可互換的的“協定模組”和“處理模組”。協定模組負責怎樣獲取網頁(例如使用HTTP),處理模組負責怎樣處理頁面。標準處理模組僅僅包括了解析頁面和抽取URL,其他處理模組可以用來檢索文本頁面,或者蒐集網路數據。
WebFountain(Edwardsetal.,2001)是一個與Mercator類似的分散式的模組化的爬蟲,但是使用C++編寫的。它的特點是一個管理員機器控制一系列的螞蟻機器。經過多次下載頁面後,頁面的變化率可以推測出來,這時,一個非線性的方法必須用於求解方程以獲得一個最大的新鮮度的訪問策略。作者推薦在早期檢索階段使用這個爬蟲,然後用統一策略檢索,就是所有的頁面都使用相同的頻率訪問。
PolyBot[ShkapenyukandSuel,2002]是一個使用C++和Python編寫的分散式網路爬蟲。它由一個爬蟲管理者,一個或多個下載者,一個或多個DNS解析者組成。抽取到的URL被添加到硬碟的一個佇列裡面,然後使用批處理的模式處理這些URL。平衡禮貌方面考慮到了第二、三級網域,因為第三級網域通常也會保存在同一個網路伺服器上。
WebRACE(Zeinalipour-YaztiandDikaiakos,2002)是一個使用java實現的,擁有檢索模組和快取模組的爬蟲,它是一個很通用的稱作eRACE的系統的一部分。系統從用戶得到下載頁面的請求,爬蟲的行為有點像一個聰明的代理伺服器。系統還監視訂閱網頁的請求,當網頁發生改變的時候,它必須使爬蟲下載更新這個頁面並且通知訂閱者。WebRACE最大的特色是,當大多數的爬蟲都從一組URL開始的時候,WebRACE可以連續地的接收抓取開始的URL地址。
Ubicrawer(Boldietal.,2004)是一個使用java編寫的分散式爬蟲。它沒有中央程式。它有一組完全相同的代理組成,分配功能通過主機前後一致的散列計算進行。這裡沒有重複的頁面,除非爬蟲崩潰了(然後,另外一個代理就會接替崩潰的代理重新開始抓取)。爬蟲設計為高伸縮性和允許失敗的。
FASTCrawler(RisvikandMichelsen,2002)是一個分散式的爬蟲,在FastSearch&Transfer中使用,關於其體系結構的一個大致的描述可以在[citationneeded]找到。
Labrador,一個工作在開源項目TerrierSearchEngine上的非開源的爬蟲。
TeezirCrawler是一個非開源的可伸縮的網頁抓取器,在Teezir上使用。該程式被設計為一個完整的可以處理各種類型網頁的爬蟲,包括各種JavaScript和HTML文檔。爬蟲既支持主題檢索也支持非主題檢索。
Spinn3r,一個通過部落格構建反饋信息的爬蟲。Spinn3r是基於java的,它的大部分的體系結構都是開源的。
HotCrawler,一個使用c語言和php編寫的爬蟲。
ViRELMicroformatsCrawler,搜尋公眾信息作為嵌入到網頁的一小部分。
除了上面列出的幾個特定的爬蟲結構以外,還有Cho(ChoandGarcia-Molina,2002)和Chakrabarti(Chakrabarti,2003)發布的一般的爬蟲體系結構。
4.1開源爬蟲
DataparkSearch是一個在GNUGPL許可下發布的爬蟲搜尋引擎。
GNUWget是一個在GPL許可下,使用C語言編寫的命令行式的爬蟲。它主要用於網路伺服器和FTP伺服器的鏡像。
Heritrix是一個網際網路檔案館級的爬蟲,設計的目標為對大型網路的大部分內容的定期存檔快照,是使用java編寫的。
Ht://Dig在它和索引引擎中包括了一個網頁爬蟲。
HTTrack用網路爬蟲創建網路站點鏡像,以便離線觀看。它使用C語言編寫,在GPL許可下發行。
ICDLCrawler是一個用C++編寫,跨平台的網路爬蟲。它僅僅使用空閒的CPU資源,在ICDL標準上抓取整個站點。
JSpider是一個在GPL許可下發行的,高度可配置的,可定製的網路爬蟲引擎。
LLarbin由SebastienAilleret開發;
Webtools4larbin由AndreasBeder開發;
Methabot是一個使用C語言編寫的高速最佳化的,使用命令行方式運行的,在2-clauseBSD許可下發布的網頁檢索器。它的主要的特性是高可配置性,模組化;它檢索的目標可以是本地檔案系統,HTTP或者FTP。
Nutch是一個使用java編寫,在Apache許可下發行的爬蟲。它可以用來連線Lucene的全文檢索套件;
Pavuk是一個在GPL許可下發行的,使用命令行的WEB站點鏡像工具,可以選擇使用X11的圖形界面。與wget和httprack相比,他有一系列先進的特性,如以正則表達式為基礎的檔案過濾規則和檔案創建規則。
WebVac是斯坦福WebBase項目使用的一個爬蟲。
WebSPHINX(MillerandBharat,1998)是一個由java類庫構成的,基於文本的搜尋引擎。它使用多執行緒進行網頁檢索,html解析,擁有一個圖形用戶界面用來設定開始的種子URL和抽取下載的數據;
WIRE-網路信息檢索環境(Baeza-Yates和Castillo,2002)是一個使用C++編寫,在GPL許可下發行的爬蟲,內置了幾種頁面下載安排的策略,還有一個生成報告和統計資料的模組,所以,它主要用於網路特徵的描述;
LWP:RobotUA(Langheinrich,2004)是一個在Perl5許可下發行的,可以優異的完成並行任務的Perl類庫構成的機器人。
WebCrawler是一個為.net準備的開放原始碼的網路檢索器(C#編寫)。
SherlockHolmes收集和檢索本地和網路上的文本類數據(文本檔案,網頁),該項目由捷克入口網站中樞(CzechwebportalCentrum)贊助並且主用商用於這裡;它同時也使用在。
YaCy是一個基於P2P網路的免費的分散式搜尋引擎(在GPL許可下發行);
Ruya是一個在廣度優先方面表現優秀,基於等級抓取的開放原始碼的網路爬蟲。在英語和日語頁面的抓取表現良好,它在GPL許可下發行,並且完全使用Python編寫。按照robots.txt有一個延時的單網域延時爬蟲。
UniversalInformationCrawler快速發展的網路爬蟲,用於檢索存儲和分析數據;
AgentKernel,當一個爬蟲抓取時,用來進行安排,並發和存儲的java框架。
是一個使用C#編寫,需要SQLServer2005支持的,在GPL許可下發行的多功能的開源的機器人。它可以用來下載,檢索,存儲包括電子郵件地址,檔案,超連結,圖片和網頁在內的各種數據。
Dine是一個多執行緒的java的http客戶端。它可以在LGPL許可下進行二次開發。
網路爬蟲的組成
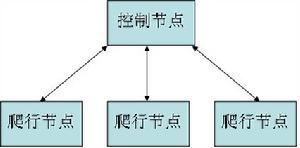
在網路爬蟲的系統框架中,主過程由控制器,解析器,資源庫三部分組成。控制器的主要工作是負責給多執行緒中的各個爬蟲執行緒分配工作任務。解析器的主要工作是下載網頁,進行頁面的處理,主要是將一些JS腳本標籤、CSS代碼內容、空格字元、HTML標籤等內容處理掉,爬蟲的基本工作是由解析器完成。資源庫是用來存放下載到的網頁資源,一般都採用大型的資料庫存儲,如Oracle資料庫,並對其建立索引。
控制器
控制器是網路爬蟲的中央控制器,它主要是負責根據系統傳過來的URL連結,分配一執行緒,然後啟動執行緒調用爬蟲爬取網頁的過程。
解析器
解析器是負責網路爬蟲的主要部分,其負責的工作主要有:下載網頁的功能,對網頁的文本進行處理,如過濾功能,抽取特殊HTML標籤的功能,分析數據功能。
資源庫
主要是用來存儲網頁中下載下來的數據記錄的容器,並提供生成索引的目標源。中大型的資料庫產品有:Oracle、SqlServer等。
