簡介
分散式快取能夠處理大量的動態數據,因此比較適合套用在Web 2.0時代中的社交網站等需要由用戶生成內容的場景。從本地快取擴展到分散式快取後,關注重點從CPU、記憶體、快取之間的數據傳輸速度差異也擴展到了業務系統、資料庫、分散式快取之間的數據傳輸速度差異。
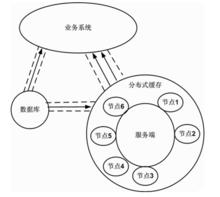 業務系統、資料庫、分散式快取之間的數據流
業務系統、資料庫、分散式快取之間的數據流圖1 業務系統、資料庫、分散式快取之間的數據流
特點
分散式快取由一個服務端實現管理和控制,有多個客戶端節點存儲數據,可以進一步提高數據的讀取速率。那么我們要讀取某個數據的時候,應該選擇哪個節點呢?如果挨個節點找,那效率就太低了。因此需要根據一致性哈希算法確定數據的存儲和讀取節點。以數據D,節點總個數N為基礎,通過一致性哈希算法計算出數據D對應的哈希值(相當於門牌號),根據這個哈希值就可以找到對應的節點了。一致哈希算法的好處在於節點個數發生變化(減少或增加)時無需重新計算哈希值,保證數據儲存或讀取時可以正確、快速地找到對應的節點。
分散式快取能夠高性能地讀取數據、能夠動態地擴展快取節點、能夠自動發現和切換故障節點、能夠自動均衡數據分區,而且能夠為使用者提供圖形化的管理界面,部署和維護都十分方便。
分散式快取已經在分散式領域、雲計算領域得到了廣泛的套用。
