
物理結構
 cpu
cpuCPU 包括運算邏輯部件、暫存器部件和控制部件等 。
邏輯部件
英文Logiccomponents;運算邏輯部件。可以執行定點或浮點算術運算操作、移位操作以及邏輯操作,也可執行地址運算和轉換。
暫存器
暫存器部件,包括暫存器、專用暫存器和控制暫存器。通用暫存器又可分定點數和浮點數兩類,它們用來保存指令執行過程中臨時存放的暫存器運算元和中間(或最終)的操作結果。通用暫存器是中央處理器的重要部件之一。
控制部件
英文Controlunit;控制部件,主要是負責對指令解碼,並且發出為完成每條指令所要執行的各個操作的控制信號。
其結構有兩種:一種是以微存儲為核心的微程式控制方式;一種是以邏輯硬布線結構為主的控制方式。
微存儲中保持微碼,每一個微碼對應於一個最基本的微操作,又稱微指令;各條指令是由不同序列的微碼組成,這種微碼序列構成微程式。中央處理器在對指令解碼以後,即發出一定時序的控制信號,按給定序列的順序以微周期為節拍執行由這些微碼確定的若干個微操作,即可完成某條指令的執行。簡單指令是由(3~5)個微操作組成,複雜指令則要由幾十個微操作甚至幾百個微操作組成。
主要功能
處理指令
英文Processinginstructions;這是指控制程式中指令的執行順序。程式中的各指令之間是有嚴格順序的,必須嚴格按程式規定的順序執行,才能保證計算機系統工作的正確性。
執行操作
英文Performanaction;一條指令的功能往往是由計算機中的部件執行一系列的操作來實現的。CPU要根據指令的功能,產生相應的操作控制信號,發給相應的部件,從而控制這些部件按指令的要求進行動作。
控制時間
英文Controltime;時間控制就是對各種操作實施時間上的定時。在一條指令的執行過程中,在什麼時間做什麼操作均應受到嚴格的控制。只有這樣,計算機才能有條不紊地工作。
處理數據
即對數據進行算術運算和邏輯運算,或進行其他的信息處理。
其功能主要是解釋計算機指令以及處理計算機軟體中的數據,並執行指令。在微型計算機中又稱微處理器,計算機的所有操作都受CPU控制,CPU的性能指標直接決定了微機系統的性能指標。CPU具有以下4個方面的基本功能:數據通信,資源共享,分散式處理,提供系統可靠性。運作原理可基本分為四個階段:提取(Fetch)、解碼(Decode)、執行(Execute)和寫回(Writeback)。
工作過程
CPU從存儲器或高速緩衝存儲器中取出指令,放入指令暫存器,並對指令解碼。它把指令分解成一系列的微操作,然後發出各種控制命令,執行微操作系列,從而完成一條指令的執行。指令是計算機規定執行操作的類型和運算元的基本命令。指令是由一個位元組或者多個位元組組成,其中包括操作碼欄位、一個或多個有關運算元地址的欄位以及一些表征機器狀態的狀態字以及特徵碼。有的指令中也直接包含運算元本身。
提取
第一階段,提取,從存儲器或高速緩衝存儲器中檢索指令(為數值或一系列數值)。由程式計數器(Program Counter)指定存儲器的位置。(程式計數器保存供識別程式位置的數值。換言之,程式計數器記錄了CPU在程式里的蹤跡。)
解碼
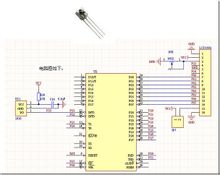 解碼線路
解碼線路CPU根據存儲器提取到的指令來決定其執行行為。在解碼階段,指令被拆解為有意義的片段。根據CPU的指令集架構(ISA)定義將數值解譯為指令。一部分的指令數值為運算碼(Opcode),其指示要進行哪些運算。其它的數值通常供給指令必要的信息,諸如一個加法(Addition)運算的運算目標。
執行
在提取和解碼階段之後,緊接著進入執行階段。該階段中,連線到各種能夠進行所需運算的CPU部件。
例如,要求一個加法運算,算術邏輯單元(ALU,Arithmetic Logic Unit)將會連線到一組輸入和一組輸出。輸入提供了要相加的數值,而輸出將含有總和的結果。ALU內含電路系統,易於輸出端完成簡單的普通運算和邏輯運算(比如加法和位元運算)。如果加法運算產生一個對該CPU處理而言過大的結果,在標誌暫存器里可能會設定運算溢出(Arithmetic Overflow)標誌。
寫回
最終階段,寫回,以一定格式將執行階段的結果簡單的寫回。運算結果經常被寫進CPU內部的暫存器,以供隨後指令快速存取。在其它案例中,運算結果可能寫進速度較慢,但容量較大且較便宜的主記憶體中。某些類型的指令會操作程式計數器,而不直接產生結果。這些一般稱作“跳轉”(Jumps),並在程式中帶來循環行為、條件性執行(透過條件跳轉)和函式。許多指令會改變標誌暫存器的狀態位元。這些標誌可用來影響程式行為,緣由於它們時常顯出各種運算結果。例如,以一個“比較”指令判斷兩個值大小,根據比較結果在標誌暫存器上設定一個數值。這個標誌可藉由隨後跳轉指令來決定程式動向。在執行指令並寫回結果之後,程式計數器值會遞增,反覆整個過程,下一個指令周期正常的提取下一個順序指令。
性能參數
計算機的性能在很大程度上由CPU的性能所決定,而CPU的性能主要體現在其運行程式的速度上。影響運行速度的性能指標包括CPU的工作頻率、Cache容量、指令系統和邏輯結構等參數。
主頻
主頻也叫時鐘頻率,單位是兆赫(MHz)或千兆赫(GHz),用來表示CPU的運算、處理數據的速度。通常,主頻越高,CPU處理數據的速度就越快。
CPU的主頻=外頻×倍頻係數。主頻和實際的運算速度存在一定的關係,但並不是一個簡單的線性關係。所以,CPU的主頻與CPU實際的運算能力是沒有直接關係的,主頻表示在CPU內數字脈衝信號震盪的速度。在Intel的處理器產品中,也可以看到這樣的例子:1GHzItanium晶片能夠表現得差不多跟2.66GHz至強(Xeon)/Opteron一樣快,或是1.5GHzItanium2大約跟4GHzXeon/Opteron一樣快。CPU的運算速度還要看CPU的流水線、匯流排等各方面的性能指標。
外頻
外頻是CPU的基準頻率,單位是MHz。CPU的外頻決定著整塊主機板的運行速度。通俗地說,在台式機中,所說的超頻,都是超CPU的外頻(當然一般情況下,CPU的倍頻都是被鎖住的)相信這點是很好理解的。但對於伺服器CPU來講,超頻是絕對不允許的。前面說到CPU決定著主機板的運行速度,兩者是同步運行的,如果把伺服器CPU超頻了,改變了外頻,會產生異步運行,(台式機很多主機板都支持異步運行)這樣會造成整個伺服器系統的不穩定。
絕大部分電腦系統中外頻與主機板前端匯流排不是同步速度的,而外頻與前端匯流排(FSB)頻率又很容易被混為一談。
匯流排頻率
 AMD 羿龍II X4 955黑盒
AMD 羿龍II X4 955黑盒前端匯流排(FSB)是將CPU連線到北橋晶片的匯流排。前端匯流排(FSB)頻率(即匯流排頻率)是直接影響CPU與記憶體直接數據交換速度。有一條公式可以計算,即數據頻寬=(匯流排頻率×數據位寬)/8,數據傳輸最大頻寬取決於所有同時傳輸的數據的寬度和傳輸頻率。比方,支持64位的至強Nocona,前端匯流排是800MHz,按照公式,它的數據傳輸最大頻寬是6.4GB/秒。
外頻與前端匯流排(FSB)頻率的區別:前端匯流排的速度指的是數據傳輸的速度,外頻是CPU與主機板之間同步運行的速度。也就是說,100MHz外頻特指數字脈衝信號在每秒鐘震盪一億次;而100MHz前端匯流排指的是每秒鐘CPU可接受的數據傳輸量是100MHz×64bit÷8bit/Byte=800MB/s。
倍頻係數
倍頻係數是指CPU主頻與外頻之間的相對比例關係。在相同的外頻下,倍頻越高CPU的頻率也越高。但實際上,在相同外頻的前提下,高倍頻的CPU本身意義並不大。這是因為CPU與系統之間數據傳輸速度是有限的,一味追求高主頻而得到高倍頻的CPU就會出現明顯的“瓶頸”效應-CPU從系統中得到數據的極限速度不能夠滿足CPU運算的速度。一般除了工程樣版的Intel的CPU都是鎖了倍頻的,少量的如Intel酷睿2核心的奔騰雙核E6500K和一些至尊版的CPU不鎖倍頻,而AMD之前都沒有鎖,AMD推出了黑盒版CPU(即不鎖倍頻版本,用戶可以自由調節倍頻,調節倍頻的超頻方式比調節外頻穩定得多)。
快取
快取大小也是CPU的重要指標之一,而且快取的結構和大小對CPU速度的影響非常大,CPU內快取的運行頻率極高,一般是和處理器同頻運作,工作效率遠遠大於系統記憶體 和硬碟。實際工作時,CPU往往需要重複讀取同樣的數據塊,而快取容量的增大,可以大幅度提升CPU內部讀取數據的命中率,而不用再到記憶體或者硬碟上尋找,以此提高系統性能。但是由於CPU晶片面積和成本的因素來考慮,快取都很小。
L1Cache(一級快取)是CPU第一層高速快取,分為數據快取和指令快取。內置的L1高速快取的容量和結構對CPU的性能影響較大,不過高速緩衝存儲器均由靜態RAM組成,結構較複雜,在CPU管芯面積不能太大的情況下,L1級高速快取的容量不可能做得太大。一般伺服器CPU的L1快取的容量通常在32-256KB。
L2Cache(二級快取)是CPU的第二層高速快取,分內部和外部兩種晶片。內部的晶片二級快取運行速度與主頻相同,而外部的二級快取則只有主頻的一半。L2高速快取容量也會影響CPU的性能,原則是越大越好,以前家庭用CPU容量最大的是512KB,筆記本電腦中也可以達到2M,而伺服器和工作站上用CPU的L2高速快取更高,可以達到8M以上。
L3Cache(三級快取),分為兩種,早期的是外置,記憶體延遲,同時提升大數據量計算時處理器的性能。降低記憶體延遲和提升大數據量計算能力對遊戲都很有幫助。而在伺服器領域增加L3快取在性能方面仍然有顯著的提升。比方具有較大L3快取的配置利用物理記憶體會更有效,故它比較慢的磁碟I/O子系統可以處理更多的數據請求。具有較大L3快取的處理器提供更有效的檔案系統快取行為及較短訊息和處理器佇列長度。
其實最早的L3快取被套用在AMD發布的K6-III處理器上,當時的L3快取受限於製造工藝,並沒有被集成進晶片內部,而是集成在主機板上。在只能夠和系統匯流排頻率同步的L3快取同主記憶體其實差不了多少。後來使用L3快取的是英特爾為伺服器市場所推出的Itanium處理器。接著就是P4EE和至強MP。Intel還打算推出一款9MBL3快取的Itanium2處理器,和以後24MBL3快取的雙核心Itanium2處理器。
但基本上L3快取對處理器的性能提高顯得不是很重要,比方配備1MBL3快取的XeonMP處理器卻仍然不是Opteron的對手,由此可見前端匯流排的增加,要比快取增加帶來更有效的性能提升。
製造工藝
CPU製造工藝的微米是指IC內電路與電路之間的距離。製造工藝的趨勢是向密集度愈高的方向發展。密度愈高的IC電路設計,意味著在同樣大小面積的IC中,可以擁有密度更高、功能更複雜的電路設計。主要的180nm、130nm、90nm、65nm、45納米、22nm,intel已經於2010年發布32納米的製造工藝的酷睿i3/酷睿i5/酷睿i7系列並於2012年4月發布了22納米酷睿i3/i5/i7系列。並且已有14nm產品的計畫(據新聞報導14nm將於2013年下半年在筆記本處理器首發。)。而AMD則表示、自己的產品將會直接跳過32nm工藝(2010年第三季度生產少許32nm產品、如Orochi、Llano)於2011年中期初發布28nm的產品(APU)。TrinityAPU已在2012年10月2日正式發布,工藝仍然32nm,28nm工藝代號Kaveri反覆推遲。2013年上市的28nm的Apu僅有平板與筆記本低端處理器,代號Kabini。而且鮮為人知,市場反應平常。據可靠訊息,2014年上半年可能有28nm的台式Apu發布,其gpu將採用GCN架構,與高端A卡同架構。
指令集
CPU依靠指令來自計算和控制系統,每款CPU在設計時就規定了一系列與其硬體電路相配合的指令系統。指令的強弱也是CPU的重要指標,指令集是提高微處理器效率的最有效工具之一。
從現階段的主流體系結構講,指令集可分為複雜指令集和精簡指令集兩部分(指令集共有四個種類),而從具體運用看,如Intel的MMX(Multi Media Extended,此為AMD猜測的全稱,Intel並沒有說明詞源)、SSE、SSE2(Streaming-Single instruction multiple data-Extensions 2)、SSE3、SSE4系列和AMD的3DNow!等都是CPU的擴展指令集,分別增強了CPU的多媒體、圖形圖象和Internet等的處理能力。
通常會把CPU的擴展指令集稱為”CPU的指令集”。SSE3指令集也是規模最小的指令集,此前MMX包含有57條命令,SSE包含有50條命令,SSE2包含有144條命令,SSE3包含有13條命令。
從586CPU開始,CPU的工作電壓分為核心電壓和I/O電壓兩種,通常CPU的核心電壓小於等於I/O電壓。其中核心電壓的大小是根據CPU的生產工藝而定,一般製作工藝越小,核心工作電壓越低;I/O電壓一般都在1.6~5V。低電壓能解決耗電過大和發熱過高的問題。
CISC
CISC指令集,也稱為複雜指令集,英文名是CISC,(Complex Instruction Set Computing的縮寫)。在CISC微處理器中,程式的各條指令是按順序串列執行的,每條指令中的各個操作也是按順序串列執行的。順序執行的優點是控制簡單,但計算機各部分的利用率不高,執行速度慢。其實它是英特爾生產的x86系列(也就是IA-32架構)CPU及其兼容CPU,如AMD、VIA的。即使是新起的X86-64(也說成AMD64)都是屬於CISC的範疇。
要知道什麼是指令集還要從當今的X86架構的CPU說起。X86指令集是Intel為其第一塊16位CPU(i8086)專門開發的,IBM1981年推出的世界第一台PC機中的CPU-i8088(i8086簡化版)使用的也是X86指令,同時電腦中為提高浮點數據處理能力而增加了X87晶片,以後就將X86指令集和X87指令集統稱為X86指令集。
雖然隨著CPU技術的不斷發展,Intel陸續研製出更新型的i80386.i80486直到過去的PII至強、PIII至強、Pentium 3,Pentium 4系列,最後到今天的酷睿2系列、至強(不包括至強Nocona),但為了保證電腦能繼續運行以往開發的各類應用程式以保護和繼承豐富的軟體資源,所以Intel公司所生產的所有CPU仍然繼續使用X86指令集,所以它的CPU仍屬於X86系列。由於Intel X86系列及其兼容CPU(如AMD Athlon MP、)都使用X86指令集,所以就形成了今天龐大的X86系列及兼容CPU陣容。x86CPU主要有intel的伺服器CPU和AMD的伺服器CPU兩類。
RISC
 中央處理器
中央處理器RISC是英文“Reduced Instruction Set Computing ”的縮寫,中文意思是“精簡指令集”。他是由John Cocke(約翰·科克)提出的,John Cocke在IBM公司從事的第一個項目是研究Stretch計算機(世界上第一個“超級計算機”型號),他很快成為大型機專家。1974年,Cocke和他領導的研究小組開始嘗試研發每秒能夠處理300線呼叫的電話交換網路。為了實現這個目標,他不得不尋找一種辦法來提高交換系統已有架構的交換率。1975年,John Cocke研究了IBM370 CISC(Complex Instruction Set Computing,複雜指令集計算)系統,對CISC機進行測試表明,各種指令的使用頻度相當懸殊,最常使用的是一些比較簡單的指令,它們僅占指令總數的20%,但在程式中出現的頻度卻占80%。
複雜的指令系統必然增加微處理器的複雜性,使處理器的研製時間長,成本高。並且複雜指令需要複雜的操作,必然會降低計算機的速度。基於上述原因,20世紀80年代RISC型CPU誕生了,相對於CISC型CPU,RISC型CPU不僅精簡了指令系統,還採用了一種叫做“超標量和超流水線結構”,大大增加了並行處理能力。RISC指令集是高性能CPU的發展方向。它與傳統的CISC(複雜指令集)相對。相比而言,RISC的指令格式統一,種類比較少,定址方式也比複雜指令集少。當然處理速度就提高很多了。在中高檔伺服器中普遍採用這一指令系統的CPU,特別是高檔伺服器全都採用RISC指令系統的CPU。RISC指令系統更加適合高檔伺服器的作業系統Windows 7,Linux也屬於類似Windows OS(UNIX)的作業系統。RISC型CPU與Intel和AMD的CPU在軟體和硬體上都不兼容。
在中高檔伺服器中採用RISC指令的CPU主要有以下幾類:PowerPC處理器、SPARC處理器、PA-RISC處理器、MIPS處理器、Alpha處理器。
IA-64
EPIC(Explicitly Parallel Instruction Computers,精確並行指令計算機)是否是RISC和CISC體系的繼承者的爭論已經有很多,單以EPIC體系來說,它更像Intel的處理器邁向RISC體系的重要步驟。從理論上說,EPIC體系設計的CPU,在相同的主機配置下,處理Windows的套用軟體比基於Unix下的套用軟體要好得多。
Intel採用EPIC技術的伺服器CPU是安騰Itanium(開發代號即Merced)。它是86位處理器,也是IA-64系列中的第一款。微軟也已開發了代號為Win64的作業系統,在軟體上加以支持。在Intel採用了X86指令集之後,它又轉而尋求更先進的86-bit微處理器,Intel這樣做的原因是,它們想擺脫容量巨大的x86架構,從而引入精力充沛而又功能強大的指令集,於是採用EPIC指令集的IA-64(x92)架構便誕生了。IA-64 (x92)在很多方面來說,都比x86有了長足的進步。突破了傳統IA32架構的許多限制,在數據的處理能力,系統的穩定性、安全性、可用性、可觀理性等方面獲得了突破性的提高。
IA-64微處理器最大的缺陷是它們缺乏與x86的兼容,而Intel為了IA-64處理器能夠更好地運行兩個朝代的軟體,它在IA-64處理器上(Itanium、Itanium2 ……)引入了x86-to-IA-64的解碼器,這樣就能夠把x86指令翻譯為IA-64指令。這個解碼器並不是最有效率的解碼器,也不是運行x86代碼的最好途徑(最好的途徑是直接在x86處理器上運行x86代碼),因此Itanium 和Itanium2在運行x86應用程式時候的性能非常糟糕。這也成為X86-64產生的根本原因。
處理技術
在解釋超流水線與超標量前,先了解流水線(Pipeline)。流水線是Intel首次在486晶片中開始使用的。流水線的工作方式就象工業生產上的裝配流水線。在CPU中由5-6個不同功能的電路單元組成一條指令處理流水線,然後將一條X86指令分成5-6步後再由這些電路單元分別執行,這樣就能實現在一個CPU時鐘周期完成一條指令,因此提高CPU的運算速度。經典奔騰每條整數流水線都分為四級流水,即指令預取、解碼、執行、寫回結果,浮點流水又分為八級流水。
 cpu
cpu超標量是通過內置多條流水線來同時執行多個處理器,其實質是以空間換取時間。而超流水線是通過細化流水、提高主頻,使得在一個機器周期內完成一個甚至多個操作,其實質是以時間換取空間。例如Pentium4的流水線就長達20級。將流水線設計的步(級)越長,其完成一條指令的速度越快,因此才能適應工作主頻更高的CPU。但是流水線過長也帶來了一定副作用,很可能會出現主頻較高的CPU實際運算速度較低的現象,Intel的奔騰4就出現了這種情況,雖然它的主頻可以高達1.4G以上,但其運算性能卻遠遠比不上AMD1.2G的速龍甚至奔騰III。
CPU封裝是採用特定的材料將CPU晶片或CPU模組固化在其中以防損壞的保護措施,一般必須在封裝後CPU才能交付用戶使用。CPU的封裝方式取決於CPU安裝形式和器件集成設計,從大的分類來看通常採用Socket插座進行安裝的CPU使用PGA(柵格陣列)方式封裝,而採用Slotx槽安裝的CPU則全部採用SEC(單邊接插盒)的形式封裝。還有PLGA(PlasticLandGridArray)、OLGA(OrganicLandGridArray)等封裝技術。由於市場競爭日益激烈,CPU封裝技術的發展方向以節約成本為主。
多執行緒
同時多執行緒SimultaneousMultithreading,簡稱SMT。SMT可通過複製處理器上的結構狀態,讓同一個處理器上的多個執行緒同步執行並共享處理器的執行資源,可最大限度地實現寬發射、亂序的超標量處理,提高處理器運算部件的利用率,緩和由於數據相關或Cache未命中帶來的訪問記憶體延時。當沒有多個執行緒可用時,SMT處理器幾乎和傳統的寬發射超標量處理器一樣。SMT最具吸引力的是只需小規模改變處理器核心的設計,幾乎不用增加額外的成本就可以顯著地提升效能。多執行緒技術則可以為高速的運算核心準備更多的待處理數據,減少運算核心的閒置時間。這對於桌面低端系統來說無疑十分具有吸引力。Intel從3.06GHzPentium4開始,部分處理器將支持SMT技術。
多核心
多核心,也指單晶片多處理器(ChipMultiprocessors,簡稱CMP)。CMP是由美國史丹福大學提出的,其思想是將大規模並行處理器中的SMP(對稱多處理器)集成到同一晶片內,各個處理器並行執行不同的進程。這種依靠多個CPU同時並行地運行程式是實現超高速計算的一個重要方向,稱為並行處理。與CMP比較,SMT處理器結構的靈活性比較突出。但是,當半導體工藝進入0.18微米以後,線延時已經超過了門延遲,要求微處理器的設計通過劃分許多規模更小、局部性更好的基本單元結構來進行。相比之下,由於CMP結構已經被劃分成多個處理器核來設計,每個核都比較簡單,有利於最佳化設計,因此更有發展前途。IBM的Power4晶片和Sun的MAJC5200晶片都採用了CMP結構。多核處理器可以在處理器內部共享快取,提高快取利用率,同時簡化多處理器系統設計的複雜度。但這並不是說明,核心越多,性能越高,比如說16核的CPU就沒有8核的CPU運算速度快,因為核心太多,而不能合理進行分配,所以導致運算速度減慢。在買電腦時請酌情選擇。2005年下半年,Intel和AMD的新型處理器也將融入CMP結構。新安騰處理器開發代碼為Montecito,採用雙核心設計,擁有最少18MB片內快取,採取90nm工藝製造。它的每個單獨的核心都擁有獨立的L1,L2和L3cache,包含大約10億支電晶體。
SMP
SMP(SymmetricMulti-Processing),對稱多處理結構的簡稱,是指在一個計算機上匯集了一組處理器(多CPU),各CPU之間共享記憶體子系統以及匯流排結構。在這種技術的支持下,一個伺服器系統可以同時運行多個處理器,並共享記憶體和其他的主機資源。像雙至強,也就是所說的二路,這是在對稱處理器系統中最常見的一種(至強MP可以支持到四路,AMDOpteron可以支持1-8路)。也有少數是16路的。但是一般來講,SMP結構的機器可擴展性較差,很難做到100個以上多處理器,常規的一般是8個到16個,不過這對於多數的用戶來說已經夠用了。在高性能伺服器和工作站級主機板架構中最為常見,像UNIX伺服器可支持最多256個CPU的系統。
構建一套SMP系統的必要條件是:支持SMP的硬體包括主機板和CPU;支持SMP的系統平台,再就是支持SMP的套用軟體。為了能夠使得SMP系統發揮高效的性能,作業系統必須支持SMP系統,如WINNT、LINUX、以及UNIX等等32位作業系統。即能夠進行多任務和多執行緒處理。多任務是指作業系統能夠在同一時間讓不同的CPU完成不同的任務;多執行緒是指作業系統能夠使得不同的CPU並行的完成同一個任務。
要組建SMP系統,對所選的CPU有很高的要求,首先、CPU內部必須內置APIC(AdvancedProgrammableInterruptControllers)單元。Intel多處理規範的核心就是高級可程式中斷控制器(AdvancedProgrammableInterruptControllers–APICs)的使用;再次,相同的產品型號,同樣類型的CPU核心,完全相同的運行頻率;最後,儘可能保持相同的產品序列編號,因為兩個生產批次的CPU作為雙處理器運行的時候,有可能會發生一顆CPU負擔過高,而另一顆負擔很少的情況,無法發揮最大性能,更糟糕的是可能導致當機。
NUMA技術
NUMA即非一致訪問分布共享存儲技術,它是由若干通過高速專用網路連線起來的獨立節點構成的系統,各個節點可以是單個的CPU或是SMP系統。在NUMA中,Cache的一致性有多種解決方案,一般採用硬體技術實現對cache的一致性維護,通常需要作業系統針對NUMA訪存不一致的特性(本地記憶體和遠端記憶體訪存延遲和頻寬的不同)進行特殊最佳化以提高效率,或採用特殊軟體編程方法提高效率。NUMA系統的例子。這裡有3個SMP模組用高速專用網路聯起來,組成一個節點,每個節點可以有12個CPU。像Sequent的系統最多可以達到64個CPU甚至256個CPU。顯然,這是在SMP的基礎上,再用NUMA的技術加以擴展,是這兩種技術的結合。
亂序執行
亂序執行(out-of-orderexecution),是指CPU允許將多條指令不按程式規定的順序分開發送給各相應電路單元處理的技術。這樣將根據個電路單元的狀態和各指令能否提前執行的具體情況分析後,將能提前執行的指令立即傳送給相應電路單元執行,在這期間不按規定順序執行指令,然後由重新排列單元將各執行單元結果按指令順序重新排列。採用亂序執行技術的目的是為了使CPU內部電路滿負荷運轉並相應提高了CPU的運行程式的速度。
分枝技術
(branch)指令進行運算時需要等待結果,一般無條件分枝只需要按指令順序執行,而條件分枝必須根據處理後的結果,再決定是否按原先順序進行。
控制器
許多應用程式擁有更為複雜的讀取模式(幾乎是隨機地,特別是當cachehit不可預測的時候),並且沒有有效地利用頻寬。典型的這類應用程式就是業務處理軟體,即使擁有如亂序執行(outoforderexecution)這樣的CPU特性,也會受記憶體延遲的限制。這樣CPU必須得等到運算所需數據被除數裝載完成才能執行指令(無論這些數據來自CPUcache還是主記憶體系統)。當前低段系統的記憶體延遲大約是120-150ns,而CPU速度則達到了4GHz以上,一次單獨的記憶體請求可能會浪費200-300次CPU循環。即使在快取命中率(cachehitrate)達到99.9%的情況下,CPU也可能會花50%的時間來等待記憶體請求的結束-比如因為記憶體延遲的緣故。
在處理器內部整合記憶體控制器,使得北橋晶片將變得不那么重要,改變了處理器訪問主存的方式,有助於提高頻寬、降低記憶體延時和提升處理器性製造工藝:Intel的I5可以達到28納米,在將來的CPU製造工藝可以達到22納米。
在ICT的套用
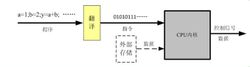 CPU套用
CPU套用在ICT的套用中,可以不考慮CPU的內部結構,把其簡單地看成一個黑盒子,容易理解。其行為模型是,給它輸入指令,經過其內部的運算和處理,就能輸出想要的結果(數據或控制信號)。
產品選購
核數選擇
如果玩遊戲的話,個人認為四核也是必要的。因為按照60%並行計算的話,雙核加速比例約1.6倍,而四核至少能有2.2倍(永遠不可能達到4倍除非你的遊戲不需要顯示卡而且只是和西洋棋一樣) 這樣算下來只要是支持四核的遊戲,四核還是比雙核有優勢的。
防假指南
看編號
這個方法對Intel和AMD的處理器同樣有效,每一顆正品盒裝處理器都有一個唯一的編號,在產品的包裝盒上的條形碼和處理器表面都會標明這個編號,這個編號相當於手機的IMEI碼,如果你購買了處理器後發現這兩個編號是不一樣的,那就可以肯定你買的這個產品是被不法商人掉包過的了。
看包裝
不法商人利用包裝偷龍轉鳳是比較常用的手法,主要是出現在Intel的CPU上,Intel盒裝處理器與散包處理器的區別就在於三年質保,價格方面相差幾十到上百元不等。當然,AMD盒裝也是假貨充斥,尤其以閃龍2500+與E6 3000+為多。由於不法商人的工藝製作水平有限,雖然假包裝已經成為一個小規模的產業,但在包裝盒的印刷製作上還是不可能達到正品包裝盒的標準,因此,我們可以從包裝盒的印刷等方面入手,識別真假。
以AMD的包裝盒為例,沒有拆封過的包裝盒貼有一張標貼,如果沒有這張標貼,那肯定是假貨。而這張標貼也是鑑別包裝盒真偽的一個切入點。從圖中可以看到,正品的標貼通過機器刻上了“十”字形的割痕,在撕開後這張標貼就會損壞而作廢。而假的包裝盒上面也有這張標貼,也同樣有這個“十”字形的割痕,不過請注意,正品的“十”字形割痕中間並沒有連在一起,而且割痕的長短深度都非常均勻,而假貨的標貼往往是制假者自己用刀片割上去的,如果消費者發現這個“十”字形的割痕長短不一,而且中間連在一起,那就可以肯定這是被人動過手腳的了。
另外,由於這個方法的鑑別非常簡單,一些不法商人就通過在包裝盒上貼上新的編號魚目混珠。鑑別真假的編號也要從印刷上來分辨。正規產品的編號條形碼採用的是點陣噴碼,字跡清晰,而且能夠清楚的看到數字是由一個個“點”組成。而假冒的條形碼是用普遍印刷的,字跡較模糊且有粘連感,另外所採用的字型也不盡相同。如果發現這個條形碼的印刷太差,字跡模糊,最好就不要購買了。
看風扇
這個方法主要還是針對Intel處理器,打開CPU的包裝後,可以查看原裝的風扇正中的防偽標籤,真的Intel盒包CPU防偽標籤為立體式防偽,除了底層圖案會有變化外,還會出現立體的“Intel”標誌。而假的盒包CPU,其防偽標識只有底層圖案的變化,沒有“Intel”的標誌,而且散熱片很稀疏比。
發展歷史
計算機的發展主要表現在其核心部件——微處理器的發展上,每當一款新型的微處理器出現時,就會帶動計算機系統的其他部件的相應發展,如計算機體系結構的進一步最佳化,存儲器存取容量的不斷增大、存取速度的不斷提高,外圍設備的不斷改進以及新設備的不斷出現等。
根據微處理器的字長和功能,可將其發展劃分為以下幾個階段。
第1階段
第1階段(1971——1973年)是4位和8位低檔微處理器時代,通常稱為第1代,其典型產品是Intel4004和Intel8008微處理器和分別由它們組成的MCS-4和MCS-8微機。基本特點是採用PMOS工藝,集成度低(4000個電晶體/片),系統結構和指令系統都比較簡單,主要採用機器語言或簡單的彙編語言,指令數目較少(20多條指令),基本指令周期為20~50μs,用於簡單的控制場合。
Intel在1969年為日本計算機製造商Busicom的一項專案,著手開發第一款微處理器,為一系列可程式化計算機研發多款晶片。最終,英特爾在1971年11月15日向全球市場推出4004微處理器,當年Intel 4004處理器每顆售價為200美元。4004 是英特爾第一款微處理器,為日後開發系統智慧型功能以及個人電腦奠定發展基礎,其電晶體數目約為2300顆。
第2階段
第2階段(1974——1977年)是8位中高檔微處理器時代,通常稱為第2代,其典型產品是Intel8080/8085、Motorola公司、Zilog公司的Z80等。它們的特點是採用NMOS工藝,集成度提高約4倍,運算速度提高約10~15倍(基本指令執行時間1~2μs)。指令系統比較完善,具有典型的計算機體系結構和中斷、DMA等控制功能。軟體方面除了彙編語言外,還有BASIC、FORTRAN等高級語言和相應的解釋程式和編譯程式,在後期還出現了作業系統。
1974年,Intel推出8080處理器,並作為Altair個人電腦的運算核心,Altair在《星艦奇航》電視影集中是企業號太空船的目的地。電腦迷當時可用395美元買到一組Altair的套件。它在數個月內賣出數萬套,成為史上第一款下訂單後製造的機種。Intel 8080電晶體數目約為6千顆。
第3階段
第3階段(1978——1984年)是16位微處理器時代,通常稱為第3代,其典型產品是Intel公司的8086/8088,Motorola公司的M68000,Zilog公司的Z8000等微處理器。其特點是採用HMOS工藝,集成度(20000~70000電晶體/片)和運算速度(基本指令執行時間是0.5μs)都比第2代提高了一個數量級。指令系統更加豐富、完善,採用多級中斷、多種定址方式、段式存儲機構、硬體乘除部件,並配置了軟體系統。這一時期著名微機產品有IBM公司的個人計算機。1981年IBM公司推出的個人計算機採用8088CPU。緊接著1982年又推出了擴展型的個人計算機IBM PC/XT,它對記憶體進行了擴充,並增加了一個硬磁碟驅動器。
80286(也被稱為286)是英特爾首款能執行所有舊款處理器專屬軟體的處理器,這種軟體相容性之後成為英特爾全系列微處理器的註冊商標,在6年的銷售期中,估計全球各地共安裝了1500萬部286個人電腦。Intel 80286處理器電晶體數目為13萬4千顆。1984年,IBM公司推出了以80286處理器為核心組成的16位增強型個人計算機IBM PC/AT。由於IBM公司在發展個人計算機時採用 了技術開放的策略,使個人計算機風靡世界。
第4階段
第4階段(1985——1992年)是32位微處理器時代,又稱為第4代。其典型產品是Intel公司的80386/80486,Motorola公司的M69030/68040等。其特點是採用HMOS或CMOS工藝,集成度高達100萬個電晶體/片,具有32位地址線和32位數據匯流排。每秒鐘可完成600萬條指令(Million Instructions Per Second,MIPS)。微型計算機的功能已經達到甚至超過超級小型計算機,完全可以勝任多任務、多用戶的作業。同期,其他一些微處理器生產廠商(如AMD、TEXAS等)也推出了80386/80486系列的晶片。
80386DX的內部和外部數據匯流排是32位,地址匯流排也是32位,可以定址到4GB記憶體,並可以管理64TB的虛擬存儲空間。它的運算模式除了具有實模式和保護模式以外,還增加了一種“虛擬86”的工作方式,可以通過同時模擬多個8086微處理器來提供多任務能力。80386SX是Intel為了擴大市場份額而推出的一種較便宜的普及型CPU,它的內部數據匯流排為32位,外部數據匯流排為16位,它可以接受為80286開發的16位輸入/輸出接口晶片,降低整機成本。80386SX推出後,受到市場的廣泛的歡迎,因為80386SX的性能大大優於80286,而價格只是80386的三分之一。Intel 80386 微處理器內含275,000 個電晶體—比當初的4004多了100倍以上,這款32位元處理器首次支持多工任務設計,能同時執行多個程式。Intel 80386電晶體數目約為27萬5千顆。
1989年,我們大家耳熟能詳的80486晶片由英特爾推出。這款經過四年開發和3億美元資金投入的晶片的偉大之處在於它首次實破了100萬個電晶體的界限,集成了120萬個電晶體,使用1微米的製造工藝。80486的時鐘頻率從25MHz逐步提高到33MHz、40MHz、50MHz。
80486是將80386和數學協微處理器80387以及一個8KB的高速快取集成在一個晶片內。80486中集成的80487的數字運算速度是以前80387的兩倍,內部快取縮短了微處理器與慢速DRAM的等待時間。並且,在80x86系列中首次採用了RISC(精簡指令集)技術,可以在一個時鐘周期內執行一條指令。它還採用了突發匯流排方式,大大提高了與記憶體的數據交換速度。由於這些改進,80486的性能比帶有80387數學協微處理器的80386 DX性能提高了4倍。
第5階段
 處理器晶片
處理器晶片第5階段(1993-2005年)是奔騰(pentium)系列微處理器時代,通常稱為第5代。典型產品是Intel公司的奔騰系列晶片及與之兼容的AMD的K6、K7系列微處理器晶片。內部採用了超標量指令流水線結構,並具有相互獨立的指令和數據高速快取。隨著MMX(Multi Media eXtended)微處理器的出現,使微機的發展在網路化、多媒體化和智慧型化等方面跨上了更高的台階。
1997年推出的Pentium II處理器結合了Intel MMX技術,能以極高的效率處理影片、音效、以及繪圖資料,首次採用Single Edge Contact (S.E.C) 匣型封裝,內建了高速快取記憶體。這款晶片讓電腦使用者擷取、編輯、以及透過網路和親友分享數位相片、編輯與新增文字、音樂或製作家庭電影的轉場效果、使用可視電話以及透過標準電話線與網際網路傳送影片,Intel Pentium II處理器電晶體數目為750萬顆。
1999年推出的Pentium III處理器加入70個新指令,加入網際網路串流SIMD延伸集稱為MMX,能大幅提升先進影像、3D、串流音樂、影片、語音辨識等套用的性能,它能大幅提升網際網路的使用經驗,讓使用者能瀏覽逼真的線上博物館與商店,以及下載高品質影片,Intel首次導入0.25微米技術,Intel Pentium III電晶體數目約為950萬顆。
與此同年,英特爾還發布了Pentium IIIXeon處理器。作為Pentium II Xeon的後繼者,除了在核心架構上採納全新設計以外,也繼承了Pentium III處理器新增的70條指令集,以更好執行多媒體、流媒體套用軟體。除了面對企業級的市場以外,Pentium III Xeon加強了電子商務套用與高階商務計算的能力。在快取速度與系統匯流排結構上,也有很多進步,很大程度提升了性能,並為更好的多處理器協同工作進行了設計。
2000年英特爾發布了Pentium 4處理器。用戶使用基於Pentium 4處理器的個人電腦,可以創建專業品質的影片,透過網際網路傳遞電視品質的影像,實時進行語音、影像通訊,實時3D渲染,快速進行MP3編碼解碼運算,在連線網際網路時運行多個多媒體軟體。
Pentium 4處理器集成了4200萬個電晶體,到了改進版的Pentium 4(Northwood)更是集成了5千5百萬個電晶體;並且開始採用0.18微米進行製造,初始速度就達到了1.5GHz。
Pentium 4還提供的SSE2指令集,這套指令集增加144個全新的指令,在128bit壓縮的數據,在SSE時,僅能以4個單精度浮點值的形式來處理,而在SSE2指令集,該資料能採用多種數據結構來處理:
4個單精度浮點數(SSE)對應2個雙精度浮點數(SSE2);對應16位元組數(SSE2);對應8個字數(word);對應4個雙字數(SSE2);對應2個四字數(SSE2);對應1個128位長的整數(SSE2) 。
2003年英特爾發布了Pentium M(mobile)處理器。以往雖然有移動版本的Pentium II、III,甚至是Pentium 4-M產品,但是這些產品仍然是基於桌上型電腦處理器的設計,再增加一些節能,管理的新特性而已。即便如此,Pentium III-M和Pentium 4-M的能耗遠高於專門為移動運算設計的CPU,例如全美達的處理器。
英特爾Pentium M處理器結合了855晶片組家族與Intel PRO/Wireless2100網路在線上技術,成為英特爾Centrino(迅馳)移動運算技術的最重要組成部分。Pentium M處理器可提供高達1.60GHz的主頻速度,並包含各種效能增強功能,如:最佳化電源的400MHz系統匯流排、微處理作業的融合(Micro-OpsFusion)和專門的堆疊管理器(Dedicated Stack Manager),這些工具可以快速執行指令集並節省電力。
2005年Intel推出的雙核心處理器有Pentium D和Pentium Extreme Edition,同時推出945/955/965/975晶片組來支持新推出的雙核心處理器,採用90nm工藝生產的這兩款新推出的雙核心處理器使用是沒有針腳的LGA 775接口,但處理器底部的貼片電容數目有所增加,排列方式也有所不同。
桌面平台的核心代號Smithfield的處理器,正式命名為Pentium D處理器,除了擺脫阿拉伯數字改用英文字母來表示這次雙核心處理器的世代交替外,D的字母也更容易讓人聯想起Dual-Core雙核心的涵義。
Intel的雙核心構架更像是一個雙CPU平台,Pentium D處理器繼續沿用Prescott架構及90nm生產技術生產。Pentium D核心實際上由於兩個獨立的Prescott核心組成,每個核心擁有獨立的1MB L2快取及執行單元,兩個核心加起來一共擁有2MB,但由於處理器中的兩個核心都擁有獨立的快取,因此必須保證每個二級快取當中的信息完全一致,否則就會出現運算錯誤。
為了解決這一問題,Intel將兩個核心之間的協調工作交給了外部的MCH(北橋)晶片,雖然快取之間的數據傳輸與存儲並不巨大,但由於需要通過外部的MCH晶片進行協調處理,毫無疑問的會對整個的處理速度帶來一定的延遲,從而影響到處理器整體性能的發揮。
由於採用Prescott核心,因此Pentium D也支持EM64T技術、XD bit安全技術。值得一提的是,Pentium D處理器將不支持Hyper-Threading技術。原因很明顯:在多個物理處理器及多個邏輯處理器之間正確分配數據流、平衡運算任務並非易事。比如,如果應用程式需要兩個運算執行緒,很明顯每個執行緒對應一個物理核心,但如果有3個運算執行緒呢?因此為了減少雙核心Pentium D架構複雜性,英特爾決定在針對主流市場的Pentium D中取消對Hyper-Threading技術的支持。
同出自Intel之手,而且Pentium D和Pentium Extreme Edition兩款雙核心處理器名字上的差別也預示著這兩款處理器在規格上也不盡相同。其中它們之間最大的不同就是對於超執行緒(Hyper-Threading)技術的支持。Pentium D不支持超執行緒技術,而Pentium Extreme Edition則沒有這方面的限制。在打開超執行緒技術的情況下,雙核心Pentium Extreme Edition處理器能夠模擬出另外兩個邏輯處理器,可以被系統認成四核心繫統。
Pentium EE系列都採用三位數字的方式來標註,形式是Pentium EE8xx或9xx,例如Pentium EE840等等,數字越大就表示規格越高或支持的特性越多。
Pentium EE 8x0:表示這是Smithfield核心、每核心1MB二級快取、800MHzFSB的產品,其與Pentium D 8x0系列的唯一區別僅僅只是增加了對超執行緒技術的支持,除此之外其它的技術特性和參數都完全相同。
Pentium EE 9x5:表示這是Presler核心、每核心2MB二級快取、1066MHzFSB的產品,其與Pentium D 9x0系列的區別只是增加了對超執行緒技術的支持以及將前端匯流排提高到1066MHzFSB,除此之外其它的技術特性和參數都完全相同。
單核心的Pentium 4、Pentium 4 EE、Celeron D以及雙核心的Pentium D和Pentium EE等CPU採用LGA775封裝。與以前的Socket 478接口CPU不同,LGA 775接口CPU的底部沒有傳統的針腳,而代之以775個觸點,即並非針腳式而是觸點式,通過與對應的LGA 775插槽內的775根觸針接觸來傳輸信號。LGA 775接口不僅能夠有效提升處理器的信號強度、提升處理器頻率,同時也可以提高處理器生產的良品率、降低生產成本。
第6階段
第6階段(2005年至今)是酷睿(core)系列微處理器時代,通常稱為第6代。“酷睿”是一款領先節能的新型微架構,設計的出發點是提供卓然出眾的性能和能效,提高每瓦特性能,也就是所謂的能效比。早期的酷睿是基於筆記本處理器的。 酷睿2:英文名稱為Core 2 Duo,是英特爾在2006年推出的新一代基於Core微架構的產品體系統稱。於2006年7月27日發布。酷睿2是一個跨平台的構架體系,包括伺服器版、桌面版、移動版三大領域。其中,伺服器版的開發代號為Woodcrest,桌面版的開發代號為Conroe,移動版的開發代號為Merom。
酷睿2處理器的Core微架構是Intel的以色列設計團隊在Yonah微架構基礎之上改進而來的新一代英特爾架構。最顯著的變化在於在各個關鍵部分進行強化。為了提高兩個核心的內部數據交換效率採取共享式二級快取設計,2個核心共享高達4MB的二級快取。
繼LGA775接口之後,Intel首先推出了LGA1366平台,定位高端旗艦系列。首顆採用LGA 1366接口的處理器代號為Bloomfield,採用經改良的Nehalem核心,基於45納米製程及原生四核心設計,內建8-12MB三級快取。LGA1366平台再次引入了Intel超執行緒技術,同時QPI匯流排技術取代了由Pentium 4時代沿用至今的前端匯流排設計。最重要的是LGA1366平台是支持三通道記憶體設計的平台,在實際的效能方面有了更大的提升,這也是LGA1366旗艦平台與其他平台定位上的一個主要區別。
作為高端旗艦的代表,早期LGA1366接口的處理器主要包括45nm Bloomfield核心酷睿i7四核處理器。隨著Intel在2010年邁入32nm工藝製程,高端旗艦的代表被酷睿i7-980X處理器取代,全新的32nm工藝解決六核心技術,擁有最強大的性能表現。對於準備組建高端平台的用戶而言,LGA1366依然占據著高端市場,酷睿i7-980X以及酷睿i7-950依舊是不錯的選擇。
Core i5是一款基於Nehalem架構的四核處理器,採用整合記憶體控制器,三級快取模式,L3達到8MB,支持Turbo Boost等技術的新處理器電腦配置。它和Core i7(Bloomfield)的主要區別在於匯流排不採用QPI,採用的是成熟的DMI(Direct Media Interface),並且只支持雙通道的DDR3記憶體。結構上它用的是LGA1156 接口,i5有睿頻技術,可以在一定情況下超頻。LGA1156接口的處理器涵蓋了從入門到高端的不同用戶,32nm工藝製程帶來了更低的功耗和更出色的性能。主流級別的代表有酷睿i5-650/760,中高端的代表有酷睿i7-870/870K等。我們可以明顯的看出Intel在產品命名上的定位區分。但是整體來看中高端LGA1156處理器比低端入門更值得選購,面對AMD的低價策略,Intel酷睿i3系列處理器完全無法在性價比上與之匹敵。而LGA1156中高端產品在性能上表現更加搶眼。
Core i3可看作是Core i5的進一步精簡版(或閹割版),將有32nm工藝版本(研發代號為Clarkdale,基於Westmere架構)這種版本。Core i3最大的特點是整合GPU(圖形處理器),也就是說Core i3將由CPU+GPU兩個核心封裝而成。由於整合的GPU性能有限,用戶想獲得更好的3D性能,可以外加顯示卡。值得注意的是,即使是Clarkdale,顯示核心部分的製作工藝仍會是45nm。i3 i5 區別最大之處是 i3沒有睿頻技術。代表有酷睿i3-530/540。
2010年6月,Intel再次發布革命性的處理器——第二代Core i3/i5/i7。第二代Core i3/i5/i7隸屬於第二代智慧型酷睿家族,全部基於全新的Sandy Bridge微架構,相比第一代產品主要帶來五點重要革新:1、採用全新32nm的Sandy Bridge微架構,更低功耗、更強性能。2、內置高性能GPU(核芯顯示卡),視頻編碼、圖形性能更強。 3、睿頻加速技術2.0,更智慧型、更高效能。4、引入全新環形架構,帶來更高頻寬與更低延遲。5、全新的AVX、AES指令集,加強浮點運算與加密解密運算。
SNB(Sandy Bridge)是英特爾在2011年初發布的新一代處理器微架構,這一構架的最大意義莫過於重新定義了“整合平台”的概念,與處理器“無縫融合”的“核芯顯示卡”終結了“集成顯示卡”的時代。這一創舉得益於全新的32nm製造工藝。由於Sandy Bridge 構架下的處理器採用了比之前的45nm工藝更加先進的32nm製造工藝,理論上實現了CPU功耗的進一步降低,及其電路尺寸和性能的顯著最佳化,這就為將整合圖形核心(核芯顯示卡)與CPU封裝在同一塊基板上創造了有利條件。此外,第二代酷睿還加入了全新的高清視頻處理單元。視頻轉解碼速度的高與低跟處理器是有直接關係的,由於高清視頻處理單元的加入,新一代酷睿處理器的視頻處理時間比老款處理器至少提升了30%。新一代Sandy Bridge處理器採用全新LGA1155接口設計,並且無法與LGA1156接口兼容。Sandy Bridge是將取代Nehalem的一種新的微架構,不過仍將採用32nm工藝製程。比較吸引人的一點是這次Intel不再是將CPU核心與GPU核心用“膠水”粘在一起,而是將兩者真正做到了一個核心裡。
在2012年4月24日下午北京天文館,intel正式發布了Ivy Bridge(IVB)處理器。22nm Ivy Bridge會將執行單元的數量翻一番,達到最多24個,自然會帶來性能上的進一步躍進。Ivy Bridge會加入對DX11的支持的集成顯示卡。另外新加入的XHCI USB 3.0控制器則共享其中四條通道,從而提供最多四個USB 3.0,從而支持原生USB3.0。cpu的製作採用3D電晶體技術,CPU耗電量會減少一半。採用22nm工藝製程的Ivy Bridge架構產品將延續LGA1155平台的壽命,因此對於打算購買LGA1155平台的用戶來說,起碼一年之內不用擔心接口升級的問題了。
2013年6月4日intel 發表四代CPU“Haswell”,第四代CPU腳位(CPU接槽)稱為Intel LGA1150,主機板名稱為Z87、H87、Q87等8系列晶片組,Z87為超頻玩家及高階客群,H87為中低階一般等級,Q87為企業用。Haswell CPU 將會用於筆記型電腦、桌上型CEO套裝電腦以及 DIY零組件CPU,陸續替換現行的第三世代Ivy Bridge。
計算機硬體知識解析
| 在我們的日常生活中,計算機一般指電子計算機中用的個人電腦。計算機是一種能夠按照指令對各種數據和信息進行自動加工和處理的電子設備。它由多個零配件組成,如中央處理器、主機板、記憶體、電源、顯示卡等。接收、處理和提供數據的一種裝置,通常由輸入輸出設備、存儲器、運算和邏輯部件以及控制器組成。在此我們的任務是為這些複雜的硬體做出詳細的功能性能的解析,讓更多的人可以更直接的認識到這些專業的硬體屬性。 |
