Inception結構簡介
自從2012年Krizhevsky等贏了ImageNet競賽後,他們的AlexNet被成功套用在大量的計算機視覺任務,例如物體檢測,分割,人體姿勢估計,視頻分類,物體追蹤和圖像超分辨。
這些成功激發了對於找到更好執行卷積神經網路的的研究。從2014年起,使用更深、更寬的網路大幅提高了網路結構的質量。VGGNet和GoogleNet在2014ILSVRC分類大賽中取得了相似的突出成績。一個有意思的現象是在分類中表現突出的模型在很多領域都有廣泛套用。這意味著深度視覺結構的提升可以用於提升大部分依賴高質量視覺特徵的其它計算機視覺任務。同樣,網路質量的提高引發了新的卷積網路套用,比如此前AlexNet特徵還無法比擬的手工解析度調整。
雖然VGGNet有吸引人的簡單結構,相應的評估網路需要大量計算。另一方面GoogleNet的Inception結構也是設計用於在嚴格的記憶體和計算條件下執行。GoogleNet只使用500萬個參數,是AlexNet的1/12,它使用了6000萬個參數。VGGNet使用了比AlexNet3倍多的參數。
Inception的計算成本也低於VGGNet,這使它能夠套用於大數據場景,或是在有限的記憶體和計算能力的情況下以相對合理的成本處理較大的數據,如移動端。當然我們可以通過計算技巧來最佳化一些特定的操作來解決該問題。但是這些方法加大了複雜性。另外,這些最佳化的方法也可以套用了Inception結構,擴大了效率差。
Inception結構的複雜性使它依然存在修改困難的問題。如果只是簡單的擴大結構規模,計算的優勢會馬上消失。並且不能清楚的描述GoogLeNet結構不同設計的考慮因素。這使它難以在維持效率的同時依據新情況更新。例如,如果需要提高一些Inception風格模型的能力,簡單的加倍過濾器大小會導致4倍增加計算成本和參數。這在很多實際場景中並不現實。這裡,我們提出一些能夠有效提高卷積網路規模的原則和最佳化建議。雖然我們的原則不僅限於Inception風格網路,他們更適應於Inception風格的靈活可兼容性。這通過大量使用Inception模組的降低維度和平行結構實現,減輕了結構變動對周邊組件的影響。使用此種方式時依然要保持謹慎,不斷觀察以維持模型的高質量 。
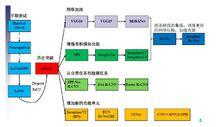 CNN結構演化圖
CNN結構演化圖設計原則
1、避免表征瓶頸,特別是在網路早期。前向傳播網路可以從輸入層到分類器或回歸器的無環圖來體現。這定義了清晰的信息流。從每一個分割輸入和輸出的切入,能夠獲得通過這個切入的信息流量。應該避免使用極端壓縮導致的瓶頸。一般講表征規模應平緩的從輸入向輸出遞減知道最終任務。理論上,信息內容無法僅通過表征的維度來評估,因為它捨棄了一些重要因素相關性結構;維度僅提供了信息內容的粗略估計。
2、更高維度的表征更容易在一個網路內本地化處理。在卷積網路中加大每層的激活能獲得更多的非糾纏特徵,可使網路訓練更快速。
3、可以在更低維度嵌入上進行空間聚合,不會損失或損失太多的體現能力。例如在進行3*3卷積之前,可以在空間聚合之前降低輸入表征,不會有嚴重問題。我們假設它是因為在空間聚合情況下使用輸出,相鄰單元結果的強相關性在降低維度時損失較小。基於此這些信號可便利的被壓縮,並且維度降低能使學習更快。
4、平衡網路的寬度和深度。網路的最佳化表現可以通過平衡每階段的過濾器數量和網路深度實現。同時提高寬度和深度可以提高網路質量,但是只有並行提高時才能對計算常量最佳化提升,因此要在網路的深度和寬度合理平衡分配計算能力 。
Inception V1模型
Inception v1的網路,將1x1,3x3,5x5的conv和3x3的pooling,堆疊在一起,一方面增加了網路的width,另一方面增加了網路對尺度的適應性 。
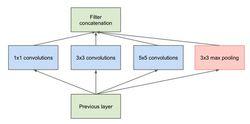 原始版本
原始版本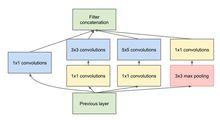 Inception V1模型
Inception V1模型第一張圖是最原始的版本,所有的卷積核都在上一層的所有輸出上來做,5×5的卷積核所需的計算量就太大,造成了特徵圖厚度很大。為了避免這一現象提出的inception具有如下結構,在3x3前,5x5前,max pooling後分別加上了1x1的卷積核起到了降低特徵圖厚度的作用,也就是Inception v1的網路結構。
 GoogLeNet結構圖
GoogLeNet結構圖右圖為GoogLeNet的結構圖:
Inception v2模型
一方面了加入了BN層,減少了Internal Covariate Shift(內部neuron的數據分布發生變化),使每一層的輸出都規範化到一個N(0, 1)的高斯;
另外一方面學習VGG用2個3x3的conv替代inception模組中的5x5,既降低了參數數量,也加速計算;
 VGG的conv
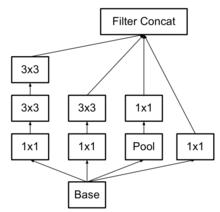
VGG的conv使用3×3的已經很小,那么更小的雖然能使得參數進一步降低,但是不如另一種方式更加有效,就是Asymmetric方式,即使用1×3和3×1兩種來代替3×3的卷積核。這種結構在前幾層效果不太好,但對特徵圖大小為12~20的中間層效果明顯 。
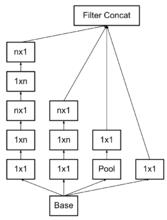 Asymmetric方式
Asymmetric方式Inception v3模型
V3一個最重要的改進是分解(Factorization),將7x7分解成兩個一維的卷積(1x7,7x1),3x3也是一樣(1x3,3x1),這樣的好處,既可以加速計算(多餘的計算能力可以用來加深網路),又可以將1個conv拆成2個conv,使得網路深度進一步增加,增加了網路的非線性,還有值得注意的地方是網路輸入從224x224變為了299x299,更加精細設計了35x35/17x17/8x8的模組 。
Inception v4模型
v4研究了Inception模組結合Residual Connection能不能有改進。發現ResNet的結構可以極大地加速訓練,同時性能也有提升,得到一個Inception-ResNet v2網路,同時還設計了一個更深更最佳化的Inception v4模型,能達到與Inception-ResNet v2相媲美的性能 。
