
核心思想
inception模組的基本機構如圖一,整個inception結構就是由多個這樣的inception模組串聯起來的。inception結構的主要貢獻有兩個:一是使用1x1的卷積來進行升降維;二是在多個尺寸上同時進行卷積再聚合。
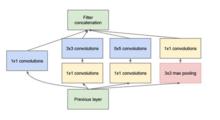 圖一
圖一1x1卷積
作用1:在相同尺寸的感受野中疊加更多的卷積,能提取到更豐富的特徵。這個觀點來自於Network in Network,圖一里三個1x1卷積都起到了該作用。
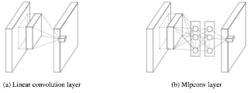 圖二
圖二圖二左側是是傳統的卷積層結構(線性卷積),在一個尺度上只有一次卷積;右圖是Network in Network結構(NIN結構),先進行一次普通的卷積(比如3x3),緊跟再進行一次1x1的卷積,對於某個像素點來說1x1卷積等效於該像素點在所有特徵上進行一次全連線的計算,所以右側圖的1x1卷積畫成了全連線層的形式,需要注意的是NIN結構中無論是第一個3x3卷積還是新增的1x1卷積,後面都緊跟著激活函式(比如relu)。將兩個卷積串聯,就能組合出更多的非線性特徵。舉個例子,假設第1個3x3卷積+激活函式近似於f1(x)=ax2+bx+c,第二個1x1卷積+激活函式近似於f2(x)=mx2+nx+q,那f1(x)和f2(f1(x))比哪個非線性更強,更能模擬非線性的特徵?答案是顯而易見的。NIN的結構和傳統的神經網路中多層的結構有些類似,後者的多層是跨越了不同尺寸的感受野(通過層與層中間加pool層),從而在更高尺度上提取出特徵;NIN結構是在同一個尺度上的多層(中間沒有pool層),從而在相同的感受野範圍能提取更強的非線性。
作用2:使用1x1卷積進行降維,降低了計算複雜度。圖二中間3x3卷積和5x5卷積前的1x1卷積都起到了這個作用。當某個卷積層輸入的特徵數較多,對這個輸入進行卷積運算將產生巨大的計算量;如果對輸入先進行降維,減少特徵數後再做卷積計算量就會顯著減少。圖三是最佳化前後兩種方案的乘法次數比較,同樣是輸入一組有192個特徵、32x32大小,輸出256組特徵的數據,第一張圖直接用3x3卷積實現,需要192x256x3x3x32x32=452984832次乘法;第二張圖先用1x1的卷積降到96個特徵,再用3x3卷積恢復出256組特徵,需要192x96x1x1x32x32+96x256x3x3x32x32=245366784次乘法,使用1x1卷積降維的方法節省了一半的計算量。有人會問,用1x1卷積降到96個特徵後特徵數不就減少了么,會影響最後訓練的效果么?答案是否定的,只要最後輸出的特徵數不變(256組),中間的降維類似於壓縮的效果,並不影響最終訓練的結果。
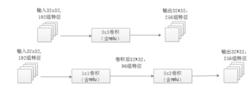 圖三
圖三多個尺寸上進行卷積再聚合
圖二可以看到對輸入做了4個分支,分別用不同尺寸的filter進行卷積或池化,最後再在特徵維度上拼接到一起。這種全新的結構有什麼好處呢?Szegedy從多個角度進行了解釋:
解釋1:在直觀感覺上在多個尺度上同時進行卷積,能提取到不同尺度的特徵。特徵更為豐富也意味著最後分類判斷時更加準確。
解釋2:利用稀疏矩陣分解成密集矩陣計算的原理來加快收斂速度。舉個例子圖四左側是個稀疏矩陣(很多元素都為0,不均勻分布在矩陣中),和一個2x2的矩陣進行卷積,需要對稀疏矩陣中的每一個元素進行計算;如果像右圖那樣把稀疏矩陣分解成2個子密集矩陣,再和2x2矩陣進行卷積,稀疏矩陣中0較多的區域就可以不用計算,計算量就大大降低。這個原理套用到inception上就是要在特徵維度上進行分解!傳統的卷積層的輸入數據只和一種尺度(比如3x3)的卷積核進行卷積,輸出固定維度(比如256個特徵)的數據,所有256個輸出特徵基本上是均勻分布在3x3尺度範圍上,這可以理解成輸出了一個稀疏分布的特徵集;而inception模組在多個尺度上提取特徵(比如1x1,3x3,5x5),輸出的256個特徵就不再是均勻分布,而是相關性強的特徵聚集在一起(比如1x1的的96個特徵聚集在一起,3x3的96個特徵聚集在一起,5x5的64個特徵聚集在一起),這可以理解成多個密集分布的子特徵集。這樣的特徵集中因為相關性較強的特徵聚集在了一起,不相關的非關鍵特徵就被弱化,同樣是輸出256個特徵,inception方法輸出的特徵“冗餘”的信息較少。用這樣的“純”的特徵集層層傳遞最後作為反向計算的輸入,自然收斂的速度更快。
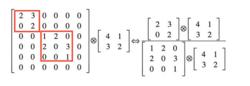 圖四
圖四解釋3:Hebbin赫布原理。Hebbin原理是神經科學上的一個理論,解釋了在學習的過程中腦中的神經元所發生的變化,用一句話概括就是 fire togethter, wire together。赫布認為“兩個神經元或者神經元系統,如果總是同時興奮,就會形成一種‘組合’,其中一個神經元的興奮會促進另一個的興奮”。比如狗看到肉會流口水,反覆刺激後,腦中識別肉的神經元會和掌管唾液分泌的神經元會相互促進,“纏繞”在一起,以後再看到肉就會更快流出口水。用在inception結構中就是要把相關性強的特徵匯聚到一起。這有點類似上面的解釋2,把1x1,3x3,5x5的特徵分開。因為訓練收斂的最終目的就是要提取出獨立的特徵,所以預先把相關性強的特徵匯聚,就能起到加速收斂的作用。
在inception模組中有一個分支使用了max pooling,作者認為pooling也能起到提取特徵的作用,所以也加入模組中。注意這個pooling的stride=1,pooling後沒有減少數據的尺寸。
