
簡介
算法簡介
 Adaboost
AdaboostAdaboost是一種疊代算法,其核心思想是針對同一個訓練集訓練不同的分類器(弱分類器),然後把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。其算法本身是通過改變數據分布來實現的,它根據每次訓練集之中每個樣本的分類是否正確,以及上次的總體分類的準確率,來確定每個樣本的權值。將修改過權值的新數據集送給下層分類器進行訓練,最後將每次訓練得到的分類器最後融合起來,作為最後的決策分類器。使用adaboost分類器可以排除一些不必要的訓練數據特徵,並放在關鍵的訓練數據上面。
算法套用
對adaBoost算法的研究以及套用大多集中於分類問題,同時也出現了一些在回歸問題上的套用。就其套用adaBoost系列主要解決了: 兩類問題、多類單標籤問題、多類多標籤問題、大類單標籤問題、回歸問題。它用全部的訓練樣本進行學習。
算法分析
過程分析
 Adaboost
Adaboost該算法其實是一個簡單的弱分類算法提升過程,這個過程通過不斷的訓練,可以提高對數據的分類能力。整個過程如下所示:
1. 先通過對N個訓練樣本的學習得到第一個弱分類器;
2. 將分錯的樣本和其他的新數據一起構成一個新的N個的訓練樣本,通過對這個樣本的學習得到第二個弱分類器 ;
3. 將1和2都分錯了的樣本加上其他的新樣本構成另一個新的N個的訓練樣本,通過對這個樣本的學習得到第三個弱分類器;
4. 最終經過提升的強分類器。即某個數據被分為哪一類要由各分類器權值決定。
算法優缺點
對於boosting算法,存在兩個問題:
1. 如何調整訓練集,使得在訓練集上訓練的弱分類器得以進行;
2. 如何將訓練得到的各個弱分類器聯合起來形成強分類器。
針對以上兩個問題,adaBoost算法進行了調整:
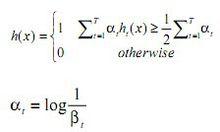 Adaboost
Adaboost1. 使用加權後選取的訓練數據代替隨機選取的訓練樣本,這樣將訓練的焦點集中在比較難分的訓練數據樣本上;
2. 將弱分類器聯合起來,使用加權的投票機制代替平均投票機制。讓分類效果好的弱分類器具有較大的權重,而分類效果差的分類器具有較小的權重。
AdaBoost算法是Freund和Schapire根據線上分配算法提出的,他們詳細分析了AdaBoost算法錯誤率的上界,以及為了使強分類器達到錯誤率,算法所需要的最多疊代次數等相關問題。與Boosting算法不同的是,adaBoost算法不需要預先知道弱學習算法學習正確率的下限即弱分類器的誤差,並且最後得到的強分類器的分類精度依賴於所有弱分類器的分類精度,這樣可以深入挖掘弱分類器算法的能力。 AdaBoost算法中不同的訓練集是通過調整每個樣本對應的權重來實現的。開始時,每個樣本對應的權重是相同的,即其中 n 為樣本個數,在此樣本分布下訓練出一弱分類器。對於分類錯誤的樣本,加大其對應的權重;而對於分類正確的樣本,降低其權重,這樣分錯的樣本就被突顯出來,從而得到一個新的樣本分布。在新的樣本分布下,再次對樣本進行訓練,得到弱分類器。依次類推,經過 T 次循環,得到 T 個弱分類器,把這 T 個弱分類器按一定的權重疊加(boost)起來,得到最終想要的強分類器。 AdaBoost算法的具體步驟如下:
1. 給定訓練樣本集S,其中X和Y分別對應於正例樣本和負例樣本; T為訓練的最大循環次數;
2. 初始化樣本權重為1/n ,即為訓練樣本的初始機率分布;
3. 第一次疊代:
(1) 訓練樣本的機率分布相當下,訓練弱分類器;
(2) 計算弱分類器的錯誤率;
(3) 選取合適閾值,使得誤差最小;
(4) 更新樣本權重;
經T次循環後,得到T個弱分類器,按更新的權重疊加,最終得到的強分類器。
Adaboost算法是經過調整的Boosting算法,其能夠對弱學習得到的弱分類器的錯誤進行適應性調整。上述算法中疊代了T次的主循環,每一次循環根據當前的權重分布對樣本x定一個分布P,然後對這個分布下的樣本使用弱學習算法得到一個弱分類器,對於這個算法定義的弱學習算法,對所有的,都有,而這個錯誤率的上限並不需要事先知道,實際上。每一次疊代,都要對權重進行更新。更新的規則是:減小弱分類器分類效果較好的數據的機率,增大弱分類器分類效果較差的數據的機率。最終的分類器是個弱分類器的加權平均。
