
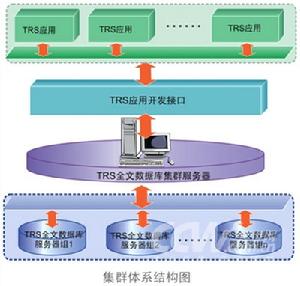
 產品功能完善的非結構化數據管理
產品功能完善的非結構化數據管理基本簡介
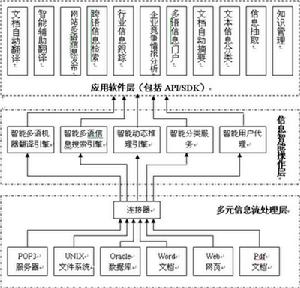 非結構化信息
非結構化信息90%的信息和知識在“結構化”世界之外,IT套用中還存在著一個“非結構化”的世界。對大多數企業來說,ERP等業務系統所管理的結構化數據只占到企業全部信息和知識的10%左右,其他的90%都是資料庫難以存取到的非結構化信息和知識。來自IDC的分析顯示,雖然很多企業投資不菲建立了諸多業務支撐系統,但仍有72%的管理者認為知識沒有在他們的組織得到重複利用,88%的人認為他們沒有接觸到企業最佳實踐的機會。Gartner 也曾預言,對非結構化信息和知識的管理將會帶來一個新IT套用潮流。
非結構化信息處理類似於上世紀70年代以前的結構化信息套用。割裂、無法進行數據互操作的套用是其主流。以人們最常用的文檔軟體來看,DOC文檔是MS WORD的專用格式,WPS、永中、中文2000等OFFICE產品廠商則各有各的“自留地”。這種情況下,由於文檔格式的束縛而使信息四分五裂,信息流無法通暢流轉,信息處理更加困難,信息資源因為“信息流的不通暢”而喪失了其應有的巨大價值。
從非結構化到半結構化,從半結構化到結構化,從結構化到關聯數據體系,從關聯數據體系到數據挖掘,從數據挖掘到故事化呈現,從故事化呈現到決策導向。
互連網上出現的海量信息,大概分為結構化、半結構化和非結構化三種。結構化信息如電子商務信息,信息的性質和量值的出現的位置是固定的;半結構化的信息如專業網站上的細分頻道,其標題和正文的語法相當規範,關鍵字的範圍相當局限;非結構化的信息如BLOG和BBS,所有內容都是不可預知的。
構建產業
 非結構化信息,提供個性化界面
非結構化信息,提供個性化界面 通俗地說,結構化信息是一些可以用表格來描述的信息。除此之外還有大量的文檔、流媒體信息等非結構化信息。但事實上,現實社會中,非結構化信息占據著80%以上的份額。這部分信息目前仍處於低效率的處理階段,它給世界信息產業發展留下了空間,也給中國軟體產業的跨越式發展帶來了契機。
非結構化信息處理仍處於類似於上世紀70年代以前的結構化信息套用。割裂地、無法進行數據互操作的套用是它的主流。以人們最常用的文檔軟體來看,DOC文檔是MS WORD的專用格式,WPS、永中、中文2000等OFFICE產品廠商則各有各的“自留地”。這種情況下,由於文檔格式的束縛而使信息四分五裂,信息流無法通暢流轉,信息處理更加困難。可以想像,有多少信息資源因為“信息流的不通暢”而喪失了其應有的巨大價值。
基於諸如此類的問題和現狀,文檔庫技術的成展成為信息產業下一步發展不可避免的潮流。文檔庫產業也將成為一個比資料庫產業更加重要的核心產業,關係到信息技術的發展進程。文檔庫技術套用意味著文檔信息可以像結構化信息套用操作一樣,文檔信息的構建只要符合一個特定的數學模型,並設計一種可以對所有符合這種數學模型的文檔進行各種操作的標準,文檔套用軟體就可以對所有此類文檔進行相應的操作——就像一個ERP軟體通過SQL操作關係型資料庫時可以不必去考慮你底層用的是DB2還是ORACLE一樣。
一個令人振奮的訊息是,北京書生公司近日宣布推出了其SEP文檔庫技術,並已經形成可以實際套用的文檔模型描述和相應的操作標準——UOML(Unstructured Operation Markup Language,非結構化操作標記語言)。這意味著,中國的企業有可能成為非結構化信息產業發展中核心技術的持有者和標準的制訂者。
可以想像,占整個信息領域20%的結構化信息產業發展帶來了超過千億美元量級的產業,那么,占整個信息領域80%的非結構化信息產業一旦走上正軌,它將帶來怎樣的市場機會。這是很多人不敢想像的數字!
按照書生董事長王東臨教授的介紹,由書生公司發起的UOML聯盟已經啟動,TRS、中文2000、漢王、中科院軟體所、中標、中科啟信、星火燎原等國內的 IT企業已加入其中,理光、Fatwire、Autonomy等單位也均有意向加入聯盟,正在洽談過程中。作為計畫推進的一部分,加入UOML聯盟的企業將首先實現相關操作的互操作問題。如10家聯盟企業有各自的文檔處理軟體,以往這10種軟體所保存的文檔無法被其他軟體操作,而加入聯盟後的這10種軟體可以操作其他任何一個軟體生成的文檔。由於文檔庫及UOML的套用,這些軟體完成這種改造只需要一兩個小時到一個星期的開發工作(視操作功能而定)。“比如其中有一家加入聯盟的企業只是想讓他的軟體可以打開符合UOML標準的文檔,那他只需要花一天去修改他的軟體。”
這既是文檔庫技術給文檔信息處理帶來的巨大優勢,也是推動非結構化信息產業發展的關鍵。
發展契機
進入二十一世紀,面對網路時代信息的爆炸式增長,海量非結構化信息的產生速度和傳播速度已經遠遠超過了人們的處理能力,中文信息處理作為一項基礎性、普適特性的信息技術,面臨著挑戰和再次發展的機遇,它的開發利用關係到中國今後信息產業乃至社會經濟的發展和國家安全,具有巨大的經濟價值和社會價值。
20世紀80年代以來,伴隨著計算機的套用和普及,中文信息處理技術獲得了較快的發展,誕生了方正雷射照排、漢王手寫輸入、科大訊飛語音合成、TRS中文檢索等一大批帶有中文特色的高水平實用化的成果。進入二十一世紀,面對網路時代信息的爆炸式增長,海量非結構化信息的產生速度和傳播速度已經遠遠超過了人們的處理能力,中文信息處理作為一項基礎性、普適特性的信息技術,面臨著挑戰和再次發展的機遇,它的開發利用關係到中國今後信息產業乃至社會經濟的發展和國家安全,具有巨大的經濟價值和社會價值。
第二次契機將以“海量非結構化信息的自動化、智慧型化處理”為特徵
網際網路的迅猛發展,使搜尋引擎正在向精準化、智慧型化、專業化方向發展,中文信息處理在垂直搜尋和企業搜尋領域獲得了更大的用武之地;WEB2.0相關論壇、部落格等的發展,也使網路輿論監測、褒貶分析等新課題出現;此外,無線通訊的發展為中文語音技術的套用提供了條件,以上種種表明,中文信息處理的套用深度和廣度正在增加,呈現海量、自動化和智慧型化的特徵,並逐漸融合包括音頻、視頻在內的多媒體技術特性。
創新是企業的靈魂,但過度依賴高校和科研院所的技術創新成果,而與市場化導向不相協調的話,最終也只會失敗。所以創新研究不一定要等到完全成熟才開始產業化,反而需要及時進行市場探索來明晰改進方向和獲得真實數據。對於中文信息處理產品來說,需要進行套用模式和服務模式的創新,特別是對於目前不完全成熟的先進中文信息處理技術,可以通過人機互動、限定領域、持續改進及服務化模式取得實用甚至超出期望的套用效果。
套用熱點
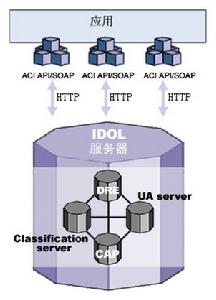 非結構化信息套用
非結構化信息套用2) 文檔管理。文檔的價值,重在重用。無論是記載了既往的經驗、訣竅、心得、數據的工作文檔,還是承載了規範、方法、工具的工作模版,如果能夠供後來者使用,都能帶來效益和效率的提高。文檔管理亦是知識管理的基礎所在。它看似簡單,但如果以高水準的要求看待文檔管理,並不是容易做的水準高、做的持久。
3) 協同。要點在知識與業務過程結合。無論是辦公自動化系統中的文檔,或是行銷系統中的文檔管理,還是產品數據管理中的文檔管理,都是將文檔與業務的運作結合起來,在具體業務的經營管理中,同步進行知識管理。
4) 社區。重在隱性知識向顯性知識的轉化。隨著Web 2.0套用的普及化,部落格、論壇、問題庫、圈子、人脈網路等在大型企業內部的套用,亦逐步增多。由此,企業的社區不僅僅是論壇這一個套用。社區,促進了隱性知識向顯性知識的轉化。
5) E-learning系統。也是企業知識管理的套用重點之一,使得受制於講師、空間、時間的面授培訓,變成用戶來點播使用的基於網路的培訓。對於知識性的培訓來說,這不僅有品質的保障,而且大大降低了成本。
上述這些不同的套用,外加企業內部建設的業務類、管理類系統,帶來了信息量的膨脹,異構的數據。用戶如何從這些系統中獲取所需的信息,所費的時間越來越多。
