
拼音
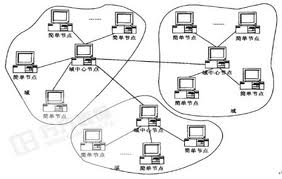
 超級節點分為核心超級節點SN-C、
超級節點分為核心超級節點SN-C、chāojíjiédiǎn
英文
 就變成超級節點,同時,存在的節點也可以影響它的鄰居節點成
就變成超級節點,同時,存在的節點也可以影響它的鄰居節點成SuperNode
簡介
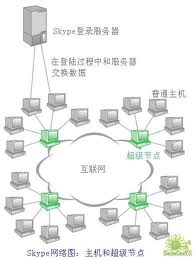 在這個網路裡面有兩種類型的節點,普通主機和超級
在這個網路裡面有兩種類型的節點,普通主機和超級“與人相遇的緣分”在網際網路理論中被稱作“超級節點”Super Node,結識人脈廣擁有許多聯繫他人的連結的人,可以為自己帶來巨大的轉機。有種理論說,如果沿著“朋友的朋友”找下去,通過六個人就可以結識世界上任何一個人,也稱為“六度分隔”Six Degrees of Separation。六人中,其中必須包括人脈廣的人才能做得到。
實際上,網際網路也是以同樣的結構將世界的各個角落有效地連在一起。大家使用的中國電信與中國聯通等網際網路服務就是“超級節點”。正因為中國聯通與中國電信實現了互連,各自的用戶之間才可以互相通信。
名詞解釋
 超級節點,直到得到想要的資
超級節點,直到得到想要的資節點
英文詞條名:node;panelpoint
兩個或兩個以上桿件共同聯結點。
六度分隔理論
英文;SixDegreesofSeparation
在這個世界上,任意兩個人之間建立一種聯繫,最多需要6個人,這就是六度分隔理論。這一理論在20世紀60年代由美國心理學家斯坦利·米爾格朗提出,而美國微軟公司研究人員近期通過計算證實了這一理論。
六度分隔:微軟公司研究人員通過電腦計算證實了六度分隔理論。通過準確計算,任意兩個人之間建立聯繫需要6.6人。也就是說,普通人與歌星麥當娜或英國女王伊莉莎白二世取得聯繫,其實只需要幾個熟人而已。
研究人員假定任何通過微軟網路聯繫對方的兩個人相識。他們選取2006年某月中所有使用微軟網路的用戶地址,計算得出,78%的用戶可與另一用戶通過6.6條信息相連。在這個月中,通過微軟網路傳送的即時信息共有300億條。
“這一結果真讓我震驚,”英國《每日郵報》8月4日援引微軟公司研究人員埃里克·霍維茨的話說,“六度分隔理論產生於20世紀60年代,人們一直更傾向於把它當作一個民間傳說而已。”
微軟公司研究人員還發現,這一結果並不受人口增長或信息技術進步等原因影響。
連鎖實驗:20世紀60年代,美國心理學家米爾格朗設計了一個連鎖信件實驗。米爾格朗把信隨機傳送給住在美國各城市的一部分居民,信中寫有一個波士頓股票經紀人的名字,並要求每名收信人把這封信寄給自己認為是比較接近這名股票經紀人的朋友。這位朋友收到信後,再把信寄給他認為更接近這名股票經紀人的朋友。最終,大部分信件都寄到了這名股票經紀人手中,每封信平均經手6.2次到達。
於是,米爾格朗提出六度分隔理論,認為世界上任意兩個人之間建立聯繫,最多只需要6個人。
其實,早在20世紀20年代,匈牙利作家弗里傑什·考林蒂就提出過類似觀點。他認為,世界上任意兩個人最多通過5個人就能聯繫在一起。
Skype網路“超級節點”故障致使全球性宕機
 伺服器,沒有其他任何集中的伺服器,只是將用戶節點分為普通節點和超級節
伺服器,沒有其他任何集中的伺服器,只是將用戶節點分為普通節點和超級節台北時間12月23日訊息,據國外媒體報導,Skype於當地時間周三發表官方部落格,解釋因網路“超級節點”出現故障導致Skype今日全球服務中斷。
Skype發言人皮特·帕克斯(PeterParkes)表示,Skype網路“超級節點”故障應是此次宕機事件最主要原因。雖然已查明原因,但Skype仍需幾個小時才可修復該問題。
帕克斯在聲明中指出,“Skype的網路並不像傳統的電話或即時通訊網路。它依賴於連線用戶電腦與電話的數百萬獨立網路。”這說明Skype是採用P2P而非用戶-伺服器模式提供網路電話服務。這些連線用戶電腦與電話的網路節點稱為“超級節點”。而大部分“超級節點”在今早出現故障,因此導致Skype全球服務中斷。
分析稱Skype官方說明的理由可以解釋今日出現的宕機事件。據統計,Skype今日的網路連線數從2100萬急劇下降至約100萬。
帕克斯透露,Skype已經找到修複方案,即採用超大型“超級節點”取代出現故障的節點,但這一過程需要幾個小時時間。群組視頻電話服務功能恢復或將需要更長的時間。
過分依賴超級節點的危險
各種社會網路正在變得越來越不平衡,越來越無標度化,這給我們帶來前所未有的高效率,也帶來了前所未有的危險。對超級節點的過分依賴,使得因超級節點的崩潰而造成的損傷也越來越驚人
首先考考您,是這么道題:村裡有一位王嫂,從電視裡看到了海地的一名地震孤兒,想給他送去禮物,但通過電視只了解到孤兒的姓名和所在的地區,王嫂從來沒出過門,也不認識出國的朋友,這份禮物該如何送達呢?於是想到了找村長代轉——在她認識的所有人當中,村長是交際最廣的一個。村長也很幫忙,找人代轉,一級級直到完成任務。憑您的想像力,您認為代轉的中間人大約會有多少個呢?
美國哈佛大學社會心理學家StanleyMilgram在1967年做了一項社會調查,其結論是:地球上任意兩個人之間平均只要通過5個人,就能與地球上任何一個角落的任何一個人發生聯繫,“六度分離”的說法由此確立。2003年8月,《科學》雜誌報導了一項在網際網路上進行的類似實驗,研究方在13個國家隨機確定了18名目標對象,並徵集了166個國家和地區的6萬名志願者,要求他們通過找熟人轉發的方式把郵件發給這些目標對象,其中有384封郵件完成了任務,考察其送達過程,發現郵件平均轉發了6次。
為了驗證“六度分離”推斷的正確性,人們又做了很多實驗,其中一個名為“KevinBacon遊戲”的實驗非常有趣,它的主角是美國電影演員KevinBacon。實驗涉及60萬名世界各地的演員和30萬部電影,最終得出統計結果:絕大多數演員通過不超過4部影片,就與Bacon發生了聯繫。當時設計這個實驗的計算機專家BrettTjaden稱“Bacon是世界電影界的中心”,這當然是戲謔,其實換任何一個演員當這個遊戲的主角,例如王寶強,結果也差不多。Bacon數資料庫支持線上查詢,輸入任何一個演員的英文名,都可以查到他的Bacon數,地址是:http://www.cs.virginia.edu/oracle/。
自上世紀60年代以來,人際關係網、電話網、交通網等網路都是按隨機網路來進行研究的。當前的各種社會網路,已經逐漸脫離隨機網路的形態,而向“小世界”模式迅速轉變——大家在建立自己的社會關係時,都以最快、最高效為原則。隨著網路中人數的增加,人際關係權重的差別就越來越大,隨著時間的推移,呈現出“富者愈富、貧者愈貧”的狀態,這種網路被稱為“無標度網路”。
如今,不僅人際關係網,其它一些網路也越來越向無標度的小世界網路方向發展。特別是網際網路,它的增長性和優先選擇性特別突出,其結構就非常不平衡,現在,1%的部落格吸引著99%的眼球。如果您想找到失去聯繫的前女友,不妨在韓寒這位“超級村長”的部落格蹲點,搶占沙發並把尋人啟事貼上去,言辭一定要悲切得嘔血——讓人覺得不幫忙就跟看《孔子》不哭一樣簡直不是人——這招絕對比在電線桿子上刷一萬張尋人啟事有效得多。
當下,各種社會網路正在變得越來越不平衡,越來越無標度化,這給我們帶來前所未有的高效率,也帶來了前所未有的危險,對超級節點的過分依賴,使得因超級節點的崩潰而造成的損傷也越來越驚人。
無標度網路不怕隨機攻擊,因為影響全局的超級大節點的數量是極少的。以網際網路為例,有關部門往往更愛收拾那些訪問過千萬的“超級村長”的部落格,這種方式就是智慧型攻擊了。無標度網路怕就怕智慧型攻擊,幾個超級大節點一被毀,網路可能就崩潰了。
各位“超級村長”該如何保護自己部落格的安全呢?備份當然是個好辦法,而且備份方式的差異度越大越好,以應對不同的攻擊手段和策略。例如在傳統媒體上備份,也可以把備份放在美國和俄羅斯,畢竟,中美俄三國聯合發文對文化市場進行整頓,在可以預見的未來不可能發生。
P2P 網路結構模型探析
引言
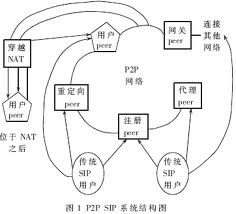
P2P網路是在IP網路基礎之上,通過套用軟體構築起來的一個邏輯覆蓋網(LogicalOverlayNetwork),並不是獨立於現行的IP網路之外的什麼特殊網路。在實際物理網路中安裝有某種P2P軟體的節點可以構成一個邏輯覆蓋網路,而沒有安裝這種P2P軟體的節點則被排除在外。
P2P網路架構,又稱為P2P網路模型,是指P2P網路中節點的邏輯組織結構,即節點互聯的拓撲結構和節點在與相鄰節點保持連線時的行為規範,一般用一個連通的圖來表示。但P2P網路的連線圖與物理網路的拓撲連線圖不同,在覆蓋網中相鄰的節點可能在實際物理網路中位於不同的子網中,中間相隔多個路由器,而在覆蓋網中不相鄰的節點在實際物理網路中卻可能是直接相連的。P2P網路模型主要分為結構化和非結構化兩類,結構化P2P系統是指系統中的數據存放的位置和數據的Key值有關,而非結構化P2P系統中,數據的存放位置與數據是無關的。
非結構化P2P網路模型
非結構化P2P網路模型按節點的集中化程度又分:
(1)集中式P2P網路模型
以Napster為代表的集中式P2P網路架構是最早出現的P2P套用模式,由於仍具有中央伺服器,沒有完全去除伺服器的性質,所以又被稱為非純粹的P2P網路。在Napster系統中,資源的檢索過程類似於傳統的C/S模式,即所有節點向中央伺服器查詢資源,但與傳統的C/S模式不同的是,資源並非存儲在伺服器上,而是存儲在各個節點中。從伺服器的返回結果中,查詢節點根據網路流量和延遲等信息選擇合適的節點建立直接連線,進行數據傳輸,數據傳輸不需要經過中央伺服器。這種網路架構的資源搜尋效率較高,但其主要缺點是中央伺服器是系統的單故障點,如果中央伺服器出現故障,則整個系統就會癱瘓,所有節點都沒法查詢到所需的資源。
(2)純P2P網路模型
純P2P網路架構以Gnutella為代表,Gnutella系統完全取消了伺服器的概念,是第一個真正採用無中心結構的P2P檔案共享系統。
拓撲維護:Gnutella中每個節點維護了一個鄰居節點列表,記錄了與之相關聯的結點的IP位址等信息。相鄰節點之間彼此交換鄰居節點信息來保持拓撲圖的連通性,並替換因節點離線而失效的連線。節點定期向鄰居節點傳送PING訊息,收到PING訊息的節點則回應一個PONG訊息,並附帶了當前所擁有的鄰居信息。收到鄰居列表後節點按照一定規則進行鄰居替換,保證自身擁有一定數量的有效鄰居。當新的節點加入系統時(它需要知道系統中至少一個節點的IP位址),它向系統已有的節點傳送PING訊息來獲得足夠的鄰居節點,從而加入系統。信息搜尋:Gnutella使用洪泛式(flooding)的資源查詢機制。發起資源查詢的節點向所有鄰居節點傳送QUERY訊息,而收到QUERY訊息的節點除了進行本地查詢,即看自己有沒有所查詢資源外,還把查詢進一步轉發給自己的所有鄰居節點。這些節點收到這一訊息後,重複進行同樣的操作,即進行本地查詢和訊息廣播。為避免無窮遞歸,每個搜尋訊息都有一個TTL(Time-to-Live)域,它隨著轉發的進行而遞減,TTL為0時訊息不再被轉發。另外節點對近期接收到的訊息進行快取,以避免重複處理同樣的訊息。搜尋操作結束後,發起搜尋的節點會收到一些查詢結果,記錄了滿足條件的檔案及其存放的節點IP,節點可從中選擇一些節點來下載所需檔案。Gnutella具有較好的擴展性,也不存在單故障點,但其查詢機制效率較低,而且也不能保證搜尋到所需的、確實存在的資源,同時每次查詢都要產生大量的轉發訊息,容易形成訊息泛濫,增加了網路的負擔。
(3)混合式網路模型
KaZaA是混合式P2P模型的典型代表,它在純P2P分散式模型基礎上引入了超級節點的概念,綜合了集中式P2P快速查找和純P2P去中心化的優勢。KaZaA模型將節點按能力不同(計算能力、記憶體大小、連線頻寬、線上時間等)區分為普通節點和超級節點兩類。當一個普通節點啟動KaZaA程式時,它首先與某一超級節點建立TCP連線,然後向這個超級節點傳送它所擁有的檔案的元數據,元數據包括:檔案名稱,檔案大小,檔案內容的哈希值(Hashvalue),以及其它信息(在按關鍵字查詢時將用到這些信息)。檔案內容哈希值是一個檔案的唯一標識,在某檔案的下載任務失敗後,KaZaA客戶端可以根據此檔案內容的哈希值自動搜尋哈希值相同的檔案。
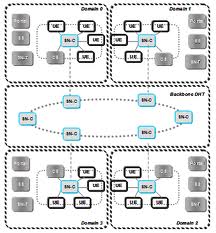
超級節點維護著所有隸屬於它的普通節點的檔案標識和對應的IP位址等信息,有點類似於Napster中的中央伺服器。超級節點與其所屬的若干個普通節點構成一個自治的簇。而整個P2P網路中各個不同的簇之間再通過純P2P的模式將超級節點連線起來,甚至也可以在各個節點之間再次選取性能最優的節點,或者另外引入一個新的性能最優的節點作為索引節點來保存和維護整個網路中可以利用的超級節點信息,並且負責維護整個網路的結構。
普通節點的檔案搜尋先在本地所屬的簇內進行:普通節點向所屬的超級節點傳送查詢關鍵字,超級節點收到查詢請求後,在本地目錄資料庫中查找相關檔案,若成功找到,則返回檔案的元數據,包括檔案所在節點的IP位址。只有查詢結果不充分的時候,才在超級節點之間進行有限的洪泛查詢;超級節點向與其有連線關係的其他超級節點廣播這個查詢訊息。收到這個訊息的超級節點做本地資料庫查詢,如果能找到,則向提交請求的普通節點返回查詢結果,否則,繼續廣播查詢訊息。
KaZaA的這種混合式網路架構,可有效地消除P2P結構中使用洪泛算法帶來的網路擁塞,也提高了資源搜尋效率,並且超級節點的引入也能在一定程度上提高整個網路的負載平衡。結
構化P2P網路模型
結構化(structured)P2P網路模型與非結構化P2P網路模型的根本區別在於每個節點所維護的鄰居是否能夠按照某種全局方式組織起來,以利於快速查找。結構化P2P模式採用純分散式的訊息傳遞機制,及根據關鍵字進行查找的定位服務。目前的主流方法是採用分散式哈希表(DistributedHashTable,DHT)這種資源定位技術:首先將網路中的每一個節點分配虛擬地址(VID),同時用一個關鍵字(KEY)來表示其可提供的共享內容。取一個哈希函式,這個函式可以將KEY轉換成一個哈希值H(KEY)。網路中節點相鄰的定義是哈希值相鄰。發布信息的時候就把(KEY,VID)二元組發布到具有和H(KEY)相近地址的節點上去,其中VID指出了文檔的存儲位置。資源定位的時候,就可以快速根據H(KEY)到相近的節點上獲取二元組(KEY,VID),從而獲得文檔的存儲位置。
不同的DHT算法決定了不同的P2P網路的邏輯拓撲,有的結構化P2P網路具有環形拓撲結構,有的具有網狀拓撲結構,而有的是採用多維向量空間。
Chord:Chord採用了相容哈希函式(consistenthashing),把所有節點和節點的文檔對應到一個由N個整數所形成的標識環(identifiercircle)上。每個節點用一個節點標識(nodeid)來代表節點在標識環中的位置,節點標識是節點IP的哈希值。而每個文檔則用一個文檔標識(objectid)來表示,文檔標識也是通過對求文檔的哈希值來得到。當一個新文檔加入系統時,系統會根據文檔標識來尋找其在標識環中的後繼者(successor)來保存這個新文檔的信息,即保存此文檔的節點的IP位址等信息。一個標識K的後繼者successor(K)均是從K開始,沿標識環順時針方向所找到的第一個節點,即節點標識符大於等於K的第一個節點。
CAN:相對於Chord使用環狀架構,CAN則採用基於虛擬的d維笛卡爾坐標空間實現其數據組織和查找功能,整個坐標空間動態地分配給系統中的所有節點,每個節點都擁有獨立的互不相交的一塊區域。虛擬坐標空間採用下面的方法保存(關鍵字,值)對。當保存(K1,V1)時,使用統一的哈希函式把關鍵字K1映射成坐標空間中的點P。那么這個值將被保存在該點所在區域的節點中。
Pastry:在Pastry中,每一個節點都被分配了一個128位全局唯一的節點標識(nodeId),當給定一條訊息和一個關鍵字時,Pastry節點將會把這條訊息路由到在當前所有的Pastry節點中nodeId和關鍵字最接近的那個節點。Pastry考慮了網路的位置信息,它的目標是使訊息傳遞的距離最短。距離採用類似於IP路由的hop數的標量距離來度量。
參考文獻
[1]龔海剛,P2P流媒體關鍵技術的研究進展.計算機研究與發展.2005
[2]郭水強,Gnutella網路中的異構延遲現象及解決方案.計算機套用研究.2004
