
簡介
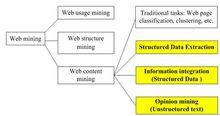 信息抽取
信息抽取網路信息 抽取屬於網路內容挖掘(Web content mining)研究的一部分,主要包括結構化數據抽取(Structured Data Extraction)、信息集成(Information integration)和觀點挖掘(Opinion mining)等。
結構化數據抽取(Structured Data Extraction)的目標是從Web頁面中抽取結構化數據。這些結構化數據往往存儲在後台資料庫中,由網頁按一定格式承載著展示給用戶。例如論壇列表頁面、Blog頁面、搜尋引擎結果頁面等。
信息集成(Information integration)是針對結構化數據而言的。其目標是將從不同網站中抽取出的數據統一化後集成入庫。其關鍵問題是如何從不同網站的數據表中識別出意義相同的數據並統一存儲。
觀點挖掘(Opinion mining)是針對網頁中的純文本而言的。其目標是從網頁中抽取出帶有主觀傾向的信息。
大多數文獻中提到的網路信息抽取往往專指結構化數據抽取。
工具
網路數據抽取工具簡介
傳統的網路數據抽取是針對抽取對象手工編寫一段專門的抽取程式,這個程式稱為包裝器(wrapper)。近年來,越來越多的網路數據抽取工具被開發出來,替代了傳統的手工編寫包裝器的方法。目前的網路數據抽取工具可分為以下幾大類(實際上,一個工具可能會歸屬於其中若干類):
開發包裝器的專用語言(Languages for Wrapper Development):用戶可用這些專用語言方便地編寫包裝器。例如Minerva,TSIMMIS,Web-OQL,FLORID,Jedi等。
以HTML為中間件的工具(HTML-aware Tools):這些工具在抽取時主要依賴HTML文檔的內在結構特徵。在抽取過程之前,這些工具先把文檔轉換成標籤樹;再根據標籤樹自動或半自動地抽取數據。代表工具有Knowlesys,MDR。
基於NLP(Natural language processing)的工具(NLP-based Tools):這些工具通常利用filtering、part-of-speech tagging、lexical semantic tagging等NLP技術建立短語和句子元素之間的關係,推導出抽取規則。這些工具比較適合於抽取那些包含符合文法的頁面。代表工具有 RAPIER,SRV,WHISK。
包裝器的歸納工具(Wrapper Induction Tools):包裝器的歸納工具從一組訓練樣例中歸納出基於分隔設定的抽取規則。這些工具和基於NLP的工具之間最大的差別在於:這些工具不依賴於語言約束,而是依賴於數據的格式化特徵。這個特點決定了這些工具比基於NLP的工具更適合於抽取HTML文檔。代表工具有:WIEN,SoftMealy,STALKER。
基於模型的工具(Modeling-based Tools):這些工具讓用戶通過圖形界面,建立文檔中其感興趣的對象的結構模型,“教”工具學會如何識別文檔中的對象,從而抽取出對象。代表工具有:NoDoSE,DEByE。
基於本體的工具(Ontology-based Tools):這些工具首先需要專家參與,人工建立某領域的知識庫,然後工具基於知識庫去做抽取操作。如果知識庫具有足夠的表達能力,那么抽取操作可以做到完全自動。而且由這些工具生成的包裝器具有比較好的靈活性和適應性。代表工具有:BYU,X-tract。
流程
網路數據抽取技術流程的實現
其具體步驟如下(以最通用的‘Knowlesys採集’步驟為例)
第一步,確立採集目標,即由用戶選擇目標網站。
第二步:提取特徵信息,即根據目標網站的網頁格式,提取出採集目標數據的通性。
第三步:網路信息獲取,即利用工具自動的把頁面數據把存到資料庫。
