
感知語音學
正文
研究語言感知的學科, 又稱言語的感知 (speech perception)。語音由說話人說出,成為言語波,通過空氣傳到聽話人耳中,經過聽覺機制、神經系統而使對方理解。廣義地說,這一全部過程都是言語的感知過程。聽覺的研究屬於生理方面,神經系統的研究屬於感知方面。語言的感知研究要用間接實驗來進行,和語言學、語音學有密切關係,因此成為一門獨特的學科。言語感知的系統 言語信號的感知是將一連串的語音通過連續的、從聽覺到神經的感知系統來完成。由於實驗手段的限制,有些理論還在假說階段,有許多事實還得通過語音實驗間接取得。對於感知的重要機制、神經系統的功能還在探索中。言語聲波的刺激在耳蝸的聽覺感受器中轉化為聽覺神經的衝動,再傳遞給大腦的中樞神經系統,由這個系統加以整理、分類和解碼。
言語感知的過程 一般可分為 4個階段:①聽覺的,②語音的,③音位系統的,④語法結構的。聽覺階段是對純聲音的感覺階段,所接收的是語音的物理參量。它把言語波轉換成為一組組按時間變化的聲型,起著刺激神經的作用。這些聲型包括頻譜結構、基頻、振幅、時長等,分別被感覺為一種語言的音位、聲調、響度和快慢等,成為語音感知的階
 段。它與聽覺階段緊密相聯。聽音人對這類音的認識,或出於習得的本能,或由於環境的濡染,辨別出各種語音信號,所感知的是一種概念模型。這一階段感知的正確程度,因聽話人的母語習慣而有差別。第3階段由聽音人根據自身熟知的語言音系,或通過學習後的理解,把所聽到的語音歸納、對比而辨別出不同的特徵或音位。第4階段是感知的最高層次,有直接的和間接的兩種感知效果。直接的是從聲音的參量來感知,例如一個詞或句子的特點可由其聲音隨時變的強弱、基頻的變化、音節分配的快慢等而區別出詞義或語義。但是,語音在連續語言中的變化很大,有些音會因受前後音的影響而變質,有的會在說快時失落(吃掉),有時或把整詞整句說得
段。它與聽覺階段緊密相聯。聽音人對這類音的認識,或出於習得的本能,或由於環境的濡染,辨別出各種語音信號,所感知的是一種概念模型。這一階段感知的正確程度,因聽話人的母語習慣而有差別。第3階段由聽音人根據自身熟知的語言音系,或通過學習後的理解,把所聽到的語音歸納、對比而辨別出不同的特徵或音位。第4階段是感知的最高層次,有直接的和間接的兩種感知效果。直接的是從聲音的參量來感知,例如一個詞或句子的特點可由其聲音隨時變的強弱、基頻的變化、音節分配的快慢等而區別出詞義或語義。但是,語音在連續語言中的變化很大,有些音會因受前後音的影響而變質,有的會在說快時失落(吃掉),有時或把整詞整句說得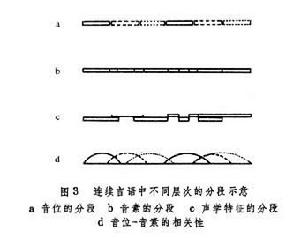 含糊,甚至有些詞或被別的詞或插入的咳嗽等所替代,但聽話人還能根據全句全章總的感知而似乎“聽到了”這些音。這個階段有許多成分依賴於社會因素。實驗證明,聽話人每因自身的母語音系與所聽音系的不同,造成感知上的“偏誤”或者用一種似是而非的所謂“中間語”來判斷、摹仿。
含糊,甚至有些詞或被別的詞或插入的咳嗽等所替代,但聽話人還能根據全句全章總的感知而似乎“聽到了”這些音。這個階段有許多成分依賴於社會因素。實驗證明,聽話人每因自身的母語音系與所聽音系的不同,造成感知上的“偏誤”或者用一種似是而非的所謂“中間語”來判斷、摹仿。 言語感知的實驗方法 語音的聲學特徵和感知特徵往往不相吻合。為了弄清哪些音聽起來與實際聲學參量相符,哪些不符,需要用聽覺測驗來判斷、選擇、分類和對比。對這類實驗通常採用兩種方法:範疇感知和選擇適應。
範疇感知。以元音為例,元音按舌位的高低,例如從 i到a,連續漸變。儘管語音學家可以把它分為4個標準元音【i】、【e】、【ε】、【a】,或作更細的分級,但各等級之間仍有無數的過渡。從前到後各音的舌位也都是如此。所以從音質來講,元音的變化是無限的,而從一個特定語言中具有辨義功能的音位來分,元音又是有限的。從音位的套用可以把無數的元音歸納成若干個音位範疇,因而產生了各範疇之間的音位界線。在不同語言中,由於音系不同,範疇的界線也不同。例如英語的【i:】和【ε】是兩個音位範疇,而西班牙人看來只是一個。漢語中吳方言的塞音有清濁兩個範疇,而在官話方言中就只歸入一個範疇。
選擇適應。把範疇感知的實驗用比較、對比等方法來使聽者作出判斷。這個實驗方法又分兩部分:①辨認,這是用人工合成出來的一系列循序漸變的語音(見言語合成),要求被試者辨認這些音的音位(不是音素),從而找出音位界線;②區分,用合成的3個音素的音作ABX實驗。其中AB兩音有微小差別,第3個X音則與AB中的某一個音相同,讓被試者區分出哪兩個音是相同的,剩下的一個音是獨異的。這類的實驗只有在高質量的合成技術問世以後,才能得到滿意的結果。它可以用合成手段把各音的聲學參量加減、變型或改變其環境來取得直接或間接的測驗結果。(圖1)是通過改變一個音節中的元音第二共振峰 VOT(見聲學語音學)的頻率和趨勢來測試輔音聽辨範疇的示例。
言語感知的運動理論 運動理論在言語感知的研究中,近年已被採用。它的一些假說雖然還有爭議,但它能解釋許多關於語言的理解、學習等方面的問題,同時對言語信息處理工程也有指導作用,因此已廣為人們所注意。運動理論的基本內容是:把聽話人聽懂語言的過程分為幾個階段。人們聽辨語音,首先是耳朵聽到各音段的物理特徵,成為聽覺模型。然後通過一系列的處理過程(生理的、物理的、……)變成可聽懂的音位。還有一種說法是:聽話人所感知的音位
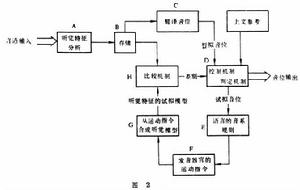 模型,必然是他自己所能說出的音位模型。這一系列的感知過程聯繫到聽音和發音雙方面。這些複雜過程在神經系統中進行得極快,而且有相互校正的功能。這些理論通過大量的實驗(包括輔音、元音和聲調的感知測驗)提供了根據。運動理論由於實驗對象和方法的不同而有多種解釋。這裡介紹一種“分析—合成”的運動理論(圖 2)。語音首先由聽覺機制 A來分析(例如,用區別特徵的理論來分析),然後在記憶中“存儲”,如 B。它隨即把所聽到的特徵送到比較機制H中和初步的音位解碼機制C中備用。後者將聽覺特徵轉換成一連串暫時譯解的音位,再送到控制機制/判定機制 D,並與這個音位前面的文句混合,得到一連串的試擬音位。這一系列的試擬音位再由音系規則E轉換成一套調音(發音)運動指令F。這些都送入一個合成裝置 G,它把指令再轉成一套聽覺特徵模型,來和原來所存的聽覺模型在H中作比較,其差別(或錯誤)由判定機制來確定。如差誤很小,則判定成立,就把初步擬定的音位作為最終決定。如差誤大,則產生一個新的試擬音位,重複一次合成的過程。這個過程可以反覆進行,直到得出最佳的判斷。這套理論模型不只用來表達音位的感知運動,對於更高層次如音節、詞、句等的感知,也同樣可用。(圖3)
模型,必然是他自己所能說出的音位模型。這一系列的感知過程聯繫到聽音和發音雙方面。這些複雜過程在神經系統中進行得極快,而且有相互校正的功能。這些理論通過大量的實驗(包括輔音、元音和聲調的感知測驗)提供了根據。運動理論由於實驗對象和方法的不同而有多種解釋。這裡介紹一種“分析—合成”的運動理論(圖 2)。語音首先由聽覺機制 A來分析(例如,用區別特徵的理論來分析),然後在記憶中“存儲”,如 B。它隨即把所聽到的特徵送到比較機制H中和初步的音位解碼機制C中備用。後者將聽覺特徵轉換成一連串暫時譯解的音位,再送到控制機制/判定機制 D,並與這個音位前面的文句混合,得到一連串的試擬音位。這一系列的試擬音位再由音系規則E轉換成一套調音(發音)運動指令F。這些都送入一個合成裝置 G,它把指令再轉成一套聽覺特徵模型,來和原來所存的聽覺模型在H中作比較,其差別(或錯誤)由判定機制來確定。如差誤很小,則判定成立,就把初步擬定的音位作為最終決定。如差誤大,則產生一個新的試擬音位,重複一次合成的過程。這個過程可以反覆進行,直到得出最佳的判斷。這套理論模型不只用來表達音位的感知運動,對於更高層次如音節、詞、句等的感知,也同樣可用。(圖3) 