
定義
 Redis
RedisRedis是一個高性能的key-value資料庫。Redis的出現,很大程度補償了memcached這類key/value存儲的不足,在部分場合可以對關係資料庫起到很好的補充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客戶端,使用很方便。
Redis支持主從同步。數據可以從主伺服器向任意數量的從伺服器上同步,從伺服器可以是關聯其他從伺服器的主伺服器。這使得Redis可執行單層樹複製。存檔可以有意無意的對數據進行寫操作。由於完全實現了發布/訂閱機制,使得從資料庫在任何地方同步樹時,可訂閱一個頻道並接收主伺服器完整的訊息發布記錄。同步對讀取操作的可擴展性和數據冗餘很有幫助。
redis的官網地址,非常好記,是redis.io。(特意查了一下,域名後綴io屬於國家域名,是british Indian Ocean territory,即英屬印度洋領地)
目前,Vmware在資助著redis項目的開發和維護。
作者
Redis的作者,他叫Salvatore Sanfilippo,來自義大利的西西里島,他使用的網名是antirez,現在居住在卡塔尼亞。目前供職於Pivotal公司。
性能
下面是官方的bench-mark數據:
測試完成了50個並發執行100000個請求。
設定和獲取的值是一個256位元組字元串。
Linux box是運行Linux 2.6,這是X3320 Xeon 2.5 ghz。
文本執行使用loopback接口(127.0.0.1)。
結果:讀的速度是110000次/s,寫的速度是81000次/s 。
支持語言
許多語言都包含Redis支持,包括:
|
|
|
|
|
數據模型
Redis的外圍由一個鍵、值映射的字典構成。與其他非關係型資料庫主要不同在於:Redis中值的類型
不僅限於字元串,還支持如下抽象數據類型:
字元串列表
無序不重複的字元串集合
有序不重複的字元串集合
鍵、值都為字元串的哈希表
值的類型決定了值本身支持的操作。Redis支持不同無序、有序的列表,無序、有序的集合間的交集、並集等高級伺服器端原子操作。
數據結構
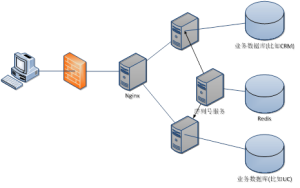 使用Redis實現高並發分散式序列號生成服務
使用Redis實現高並發分散式序列號生成服務string是最簡單的類型,你可以理解成與Memcached一模一樣的類型,一個key對應一個value,其上支持的操作與Memcached的操作類似。但它的功能更豐富。
redis採用結構sdshdr和sds封裝了字元串,字元串相關的操作實現在源檔案sds.h/sds.c中。sdshdr
數據結構定義如下:
typedefchar*sds;
structsdshdr{
longlen;
longfree;
charbuf[];
};
list(雙向鍊表)list是一個鍊表結構,主要功能是push、pop、獲取一個範圍的所有值等等。操作中key理解為鍊表的名字。
對list的定義和實現在源檔案adlist.h/adlist.c,相關的數據結構定義如下:
//list疊代器
typedefstructlistIter{
listNode*next;
intdirection;
}listIter;
//list數據結構
typedefstructlist{
listNode*head;
listNode*tail;
void*(*dup)(void*ptr);
void(*free)(void*ptr);
int(*match)(void*ptr,void*key);
unsignedintlen;
listIteriter;
}list;
dict(hash表)set是集合,和我們數學中的集合概念相似,對集合的操作有添加刪除元素,有對多個集合求交並差等操作。操作中key理解為集合的名字。
在源檔案dict.h/dict.c中實現了hashtable的操作,數據結構的定義如下:
//dict中的元素項
typedefstructdictEntry{
void*key;
void*val;
structdictEntry*next;
}dictEntry;
//dict相關配置函式
typedefstructdictType{
unsignedint(*hashFunction)(constvoid*key);
void*(*keyDup)(void*privdata,constvoid*key);
void*(*valDup)(void*privdata,constvoid*obj);
int(*keyCompare)(void*privdata,constvoid*key1,constvoid*key2);
void(*keyDestructor)(void*privdata,void*key);
void(*valDestructor)(void*privdata,void*obj);
}dictType;
//dict定義
typedefstructdict{
dictEntry**table;
dictType*type;
unsignedlongsize;
unsignedlongsizemask;
unsignedlongused;
void*privdata;
}dict;
//dict疊代器
typedefstructdictIterator{
dict*ht;
intindex;
dictEntry*entry,*nextEntry;
}dictIterator;
dict中table為dictEntry指針的數組,數組中每個成員為hash值相同元素的單向鍊表。set是在dict的基礎上實現的,指定了key的比較函式為dictEncObjKeyCompare,若key相等則不再插入。
zset(排序set)zset是set的一個升級版本,他在set的基礎上增加了一個順序屬性,這一屬性在添加修改元素的時候可以指定,每次指定後,zset會自動重新按新的值調整順序。可以理解了有兩列的mysql表,一列存value,一列存順序。操作中key理解為zset的名字。
typedefstructzskiplistNode{
structzskiplistNode**forward;
structzskiplistNode*backward;
doublescore;
robj*obj;
}zskiplistNode;
typedefstructzskiplist{
structzskiplistNode*header,*tail;
unsignedlonglength;
intlevel;
}zskiplist;
typedefstructzset{
dict*dict;
zskiplist*zsl;
}zset;
zset利用dict維護key->value的映射關係,用zsl(zskiplist)保存value的有序關係。zsl實際是叉數
不穩定的多叉樹,每條鏈上的元素從根節點到葉子節點保持升序排序。
常用命令
就DB來說,Redis成績已經很驚人了,且不說memcachedb和Tokyo Cabinet之流,就說原版的memcached,速度似乎也只能達到這個級別。Redis根本是使用記憶體存儲,持久化的關鍵是這三條指令:SAVE BGSAVE LASTSAVE …
當接收到SAVE指令的時候,Redis就會dump數據到一個檔案裡面。
值得一說的是它的獨家功能:存儲列表和集合,這是它與mc之流相比更有競爭力的地方。
不介紹mc裡面已經有的東東,只列出特殊的:
TYPE key — 用來獲取某key的類型
KEYS pattern — 匹配所有符合模式的key,比如KEYS * 就列出所有的key了,當然,複雜度O(n)
RANDOMKEY - 返回隨機的一個key
RENAME oldkeynewkey— key也可以改名
列表操作
RPUSH key string — 將某個值加入到一個key列表末尾
LPUSH key string — 將某個值加入到一個key列表頭部
LLEN key — 列表長度
LRANGE key start end — 返回列表中某個範圍的值,相當於mysql裡面的分頁查詢那樣
LTRIM key start end — 只保留列表中某個範圍的值
LINDEX key index — 獲取列表中特定索引號的值,要注意是O(n)複雜度
LSET key index value — 設定列表中某個位置的值
LPOP key
RPOP key — 和上面的LPOP一樣,就是類似棧或佇列的那種取頭取尾指令,可以當成訊息佇列來使用了
集合操作
SADD key member — 增加元素
SREM key member — 刪除元素
SCARD key — 返回集合大小
SISMEMBER key member — 判斷某個值是否在集合中
SINTER key1 key2 ... keyN — 獲取多個集合的交集元素
SMEMBERS key — 列出集合的所有元素
還有Multiple DB的命令,可以更換db,數據可以隔離開,默認是存放在DB 0。
存儲
redis使用了兩種檔案格式:全量數據和增量請求。
全量數據格式是把記憶體中的數據寫入磁碟,便於下次讀取檔案進行載入;
增量請求檔案則是把記憶體中的數據序列化為操作請求,用於讀取檔案進行replay得到數據,序列化的操作包括SET、RPUSH、SADD、ZADD。
redis的存儲分為記憶體存儲、磁碟存儲和log檔案三部分,配置檔案中有三個參數對其進行配置。
save seconds updates,save配置,指出在多長時間內,有多少次更新操作,就將數據同步到數據檔案。這個可以多個條件配合,比如默認配置檔案中的設定,就設定了三個條件。
appendonly yes/no,appendonly配置,指出是否在每次更新操作後進行日誌記錄,如果不開啟,可能會在斷電時導致一段時間內的數據丟失。因為redis本身同步數據檔案是按上面的save條件來同步的,所以有的數據會在一段時間內只存在於記憶體中。
appendfsync no/always/everysec,appendfsync配置,no表示等作業系統進行數據快取同步到磁碟,always表示每次更新操作後手動調用fsync()將數據寫到磁碟,everysec表示每秒同步一次。
安裝
 Redis
Redis使用wget工具等下載:
wget
tarxzfredis-1.2.6.tar.gz
cdredis-1.2.6。
編譯生成執行檔
由於makefile檔案已經寫好,我們只需要直接在源碼目錄執行make命令進行編譯即可:
make
make命令執行完成後,會在當前目錄下生成本個執行檔,分別是redis-server、redis-cli、redis-benchmark、redis-stat,它們的作用如下:
redis-server:Redis伺服器的daemon啟動程式
redis-cli:Redis命令行操作工具。當然,你也可以用telnet根據其純文本協定來操作
redis-benchmark:Redis性能測試工具,測試Redis在你的系統及你的配置下的讀寫性能
redis-stat:Redis狀態檢測工具,可以檢測Redis當前狀態參數及延遲狀況。
建立Redis目錄(非必須)
這個過程不是必須的,只是為了將Redis相關的資源統一管理而進行的操作。
執行以下命令建立相關目錄並拷貝相關檔案至目錄中:
sudo-s
mkdir-p/usr/local/redis/bin
mkdir-p/usr/local/redis/etc
mkdir-p/usr/local/redis/var
cpredis-serverredis-cliredis-benchmarkredis-stat/usr/local/redis/bin/
cpredis.conf/usr/local/redis/etc/
配置參數
在我們成功安裝Redis後,我們直接執行redis-server即可運行Redis,此時它是按照默認配置來運行的(默認配置甚至不是後台運行)。我們希望Redis按我們的要求運行,則我們需要修改配置檔案,Redis的配置檔案就是我們上面第二個cp操作的redis.conf檔案,它被我們拷貝到了/usr/local/redis/etc/目錄下。修改它就可以配置我們的server了。如何修改?下面是redis.conf的主要配置參數的意義:
daemonize:是否以後台daemon方式運行
pidfile:pid檔案位置
port:監聽的連線埠號
timeout:請求逾時時間
loglevel:log信息級別
logfile:log檔案位置
databases:開啟資料庫的數量
save**:保存快照的頻率,第一個*表示多長時間,第二個*表示執行多少次寫操作。在一定時間內執行一定數量的寫操作時,自動保存快照。可設定多個條件。
rdbcompression:是否使用壓縮
dbfilename:數據快照檔案名稱(只是檔案名稱,不包括目錄)
dir:數據快照的保存目錄(這個是目錄)
appendonly:是否開啟appendonlylog,開啟的話每次寫操作會記一條log,這會提高數據抗風險能力,但影響效率。
appendfsync:appendonlylog如何同步到磁碟(三個選項,分別是每次寫都強制調用fsync、每秒啟用一次fsync、不調用fsync等待系統自己同步)
下面是一個略做修改後的配置檔案內容:
daemonizeyes
pidfile/usr/local/redis/var/redis.pid
port6379
timeout300
logleveldebug
logfile/usr/local/redis/var/redis.log
databases16
save9001
save30010
save6010000
rdbcompressionyes
dbfilenamedump.rdb
dir/usr/local/redis/var/
appendonlyno
appendfsyncalways
glueoutputbufyes
shareobjectsno
shareobjectspoolsize1024
將上面內容寫為redis.conf並保存到/usr/local/redis/etc/目錄下
然後在命令行執行:
/usr/local/redis/bin/redis-server/usr/local/redis/etc/redis.conf
即可在後台啟動redis服務,這時你通過
telnet127.0.0.16379
即可連線到你的redis服務
Redis常用記憶體最佳化手段與參數
通過我們上面的一些實現上的分析可以看出redis實際上的記憶體管理成本非常高,即占用了過多的記憶體,作者對這點也非常清楚,所以提供了一系列的參數和手段來控制和節省記憶體,我們分別來討論下。首先最重要的一點是不要開啟Redis的VM選項,即虛擬記憶體功能,這個本來是作為Redis存儲超出物理記憶體數據的一種數據在記憶體與磁碟換入換出的一個持久化策略,但是其記憶體管理成本也非常的高,並且我們後續會分析此種持久化策略並不成熟,所以要關閉VM功能,請檢查你的redis.conf檔案中vm-enabled為no。其次最好設定下redis.conf中的maxmemory選項,該選項是告訴Redis當使用了多少物理記憶體後就開始拒絕後續的寫入請求,該參數能很好的保護好你的Redis不會因為使用了過多的物理記憶體而導致swap,最終嚴重影響性能甚至崩潰。另外Redis為不同數據類型分別提供了一組參數來控制記憶體使用,我們在前面詳細分析過RedisHash是value內部為一個HashMap,如果該Map的成員數比較少,則會採用類似一維線性的緊湊格式來存儲該Map,即省去了大量指針的記憶體開銷,這個參數控制對應在redis.conf配置檔案中下面2項:
含義是當value這個Map內部不超過多少個成員時會採用線性緊湊格式存儲,默認是64,即value內部有64個以下的成員就是使用線性緊湊存儲,超過該值自動轉成真正的HashMap。hash-max-zipmap-value含義是當value這個Map內部的每個成員值長度不超過多少位元組就會採用線性緊湊存儲來節省空間。以上2個條件任意一個條件超過設定值都會轉換成真正的HashMap,也就不會再節省記憶體了,那么這個值是不是設定的越大越好呢,答案當然是否定的,HashMap的優勢就是查找和操作的時間複雜度都是O(1)的,而放棄Hash採用一維存儲則是O(n)的時間複雜度,如果成員數量很少,則影響不大,否則會嚴重影響性能,所以要權衡好這個值的設定,總體上還是最根本的時間成本和空間成本上的權衡。
同樣類似的參數
list-max-ziplist-entries512說明:list數據類型多少節點以下會採用去指針的緊湊存儲格式。
list-max-ziplist-value64說明:list數據類型節點值大小小於多少位元組會採用緊湊存儲格式。
set-max-intset-entries512說明:set數據類型內部數據如果全部是數值型,且包含多少節點以下會採用緊湊格式存儲。
最後想說的是Redis內部實現沒有對記憶體分配方面做過多的最佳化,在一定程度上會存在記憶體碎片,不過大多數情況下這個不會成為Redis的性能瓶頸,不過如果在Redis內部存儲的大部分數據是數值型的話,Redis內部採用了一個sharedinteger的方式來省去分配記憶體的開銷,即在系統啟動時先分配一個從1~n那么多個數值對象放在一個池子中,如果存儲的數據恰好是這個數值範圍內的數據,則直接從池子裡取出該對象,並且通過引用計數的方式來共享,這樣在系統存儲了大量數值下,也能一定程度上節省記憶體並且提高性能,這個參數值n的設定需要修改原始碼中的一行宏定義REDIS_SHARED_INTEGERS,該值默認是10000,可以根據自己的需要進行修改,修改後重新編譯就可以了。
另外redis的6種過期策略redis中的默認的過期策略是volatile-lru。
設定方式configsetmaxmemory-policyvolatile-lrumaxmemory-policy六種方式
volatile-lru:只對設定了過期時間的key進行LRU(默認值)
allkeys-lru:是從所有key里刪除不經常使用的key
volatile-random:隨機刪除即將過期
keyallkeys-random:隨機刪除
volatile-ttl:刪除即將過期的
noeviction:永不過期,返回錯誤
maxmemory-samples3是說每次進行淘汰的時候會隨機抽取3個key從裡面淘汰最不經常使用的(默認選項)
版本發布
2012年08月02日,Redis 2.4.16 小更新版本NoSQL。
2012年08月31日 ,Redis 2.4.17 小更新版本NoSQL。
2012年11月7日 Redis 2.6.3 發布,高性能K/V伺服器
2013年4月30日Redis 2.6.13 發布,高性能K/V伺服器
2013年11月25日,Redis 2.8.1發布。
2015年2月,Redis3.0.0發布.
