這裡主要講述了LVS集群的IP負載均衡軟體IPVS在核心中實現的各種連線調度算法。針對請求的服務時間變化很大,給出一個動態反饋負載均衡算法,它結合核心中的加權連線調度算法,根據動態反饋回來的負載信息來調整伺服器的權值,來進一步避免伺服器間的負載不平衡。
簡述
在LVS集群中實現的三種IP負載均衡技術,它們主要解決系統的可伸縮性和透明性問題,如何通過負載調度器將請求高效地分發到不同的伺服器執行,使得由多台獨立計算機組成的集群系統成為一台虛擬伺服器;客戶端應用程式與集群系統互動時,就像與一台高性能的伺服器互動一樣。
下面主要講述在負載調度器上的負載調度策略和算法,如何將請求流調度到各台伺服器,使得各台伺服器儘可能地保持負載均衡。
後面主要由兩個部分組成。
第一部分:描述IP負載均衡軟體ipvs在核心中所實現的各種連線調度算法;
第二部分:給出一個動態反饋負載均衡算法(Dynamic-feedback load balancing),它結合核心中的加權連線調度算法,根據動態反饋回來的負載信息來調整伺服器的權值,來進一步避免伺服器間的負載不平衡。
在下面描述中,稱客戶的socket和伺服器的socket之間的數據通訊為連線,無論它們是使用TCP還是UDP協定。對於UDP數據報文的調度,IPVS調度器也會為之建立調度記錄並設定逾時值(如5分鐘);在設定的時間內,來自同一地址(IP位址和連線埠)的UDP數據包會被調度到同一台伺服器。
核心中的連線調度算法
IPVS在核心中的負載均衡調度是以連線為粒度的。在HTTP協定(非持久)中,每個對象從WEB伺服器上獲取都需要建立一個TCP連線,同一用戶的不同請求會被調度到不同的伺服器上,所以這種細粒度的調度在一定程度上可以避免單個用戶訪問的突發性引起伺服器間的負載不平衡。
在核心中的連線調度算法上,IPVS已實現了以下八種調度算法:
輪叫調度(Round-Robin Scheduling)
加權輪叫調度(Weighted Round-Robin Scheduling)
最小連線調度(Least-Connection Scheduling)
加權最小連線調度(Weighted Least-Connection Scheduling)
基於局部性的最少連結(Locality-Based Least Connections Scheduling)
帶複製的基於局部性最少連結(Locality-Based Least Connections with Replication Scheduling)
目標地址散列調度(Destination Hashing Scheduling)
源地址散列調度(Source Hashing Scheduling)
輪叫調度
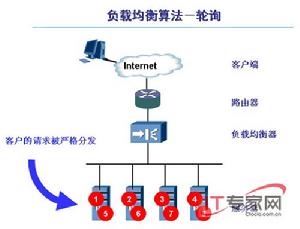 輪叫調度算法
輪叫調度算法輪叫調度(Round Robin Scheduling)算法就是以輪叫的方式依次將請求調度不同的伺服器,即每次調度執行i=(i+1)modn,並選出第i台伺服器。算法的優點是其簡潔性,它無需記錄當前所有連線的狀態,所以它是一種無狀態調度。
在系統實現時,引入了一個額外條件,當伺服器的權值為零時,表示該伺服器不可用而不被調度。這樣做的目的是將伺服器切出服務(如禁止伺服器故障和系統維護),同時與其他加權算法保持一致。所以,算法要作相應的改動,它的算法流程如下:
輪叫調度算法流程
假設有一組伺服器S={S0,S1,…,Sn-1},一個指示變數 i 表示上一次選擇的伺服器,W(Si)表示伺服器Si的權值。變數 i 被初始化為n-1,其中n>0。
j=i;
do{
j=(j+1)modn;
if(W(Sj)>0){
i=j;
returnSi;
}
}while(j!=i);
returnNULL;
輪叫調度算法假設所有伺服器處理性能均相同,不管伺服器的當前連線數和回響速度。該算法相對簡單,不適用於伺服器組中處理性能不一的情況,而且當請求服務時間變化比較大時,輪叫調度算法容易導致伺服器間的負載不平衡。
雖然Round-Robin DNS方法也是以輪叫調度的方式將一個域名解析到多個IP位址,但輪叫DNS方法的調度粒度是基於每個域名伺服器的,域名伺服器對域名解析的快取會妨礙輪叫解析域名生效,這會導致伺服器間負載的嚴重不平衡。這裡,IPVS輪叫調度算法的粒度是基於每個連線的,同一用戶的不同連線都會被調度到不同的伺服器上,所以這種細粒度的輪叫調度要比DNS的輪叫調度優越很多。
加權輪叫調度
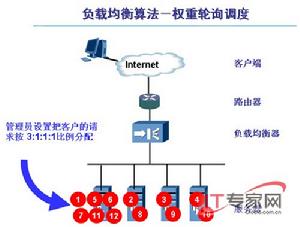 加權輪叫調度
加權輪叫調度加權輪叫調度(Weighted Round-Robin Scheduling)算法可以解決伺服器間性能不一的情況,它用相應的權值表示伺服器的處理性能,伺服器的預設權值為1。假設伺服器A的權值為1,B的權值為2,則表示伺服器B的處理性能是A的兩倍。加權輪叫調度算法是按權值的高低和輪叫方式分配請求到各伺服器。權值高的伺服器先收到的連線,權值高的伺服器比權值低的伺服器處理更多的連線,相同權值的伺服器處理相同數目的連線數。加權輪叫調度算法流程如下:
加權輪叫調度算法流程
假設有一組伺服器S={S0,S1,…,Sn-1},W(Si)表示伺服器Si的權值,一個指示變數i表示上一次選擇的伺服器,指示變數cw表示當前調度的權值,max(S)表示集合S中所有伺服器的最大權值,gcd(S)表示集合S中所有伺服器權值的最大公約數。變數i初始化為-1,cw初始化為零。
while(true){
i=(i+1)modn;
if(i==0){
cw=cw-gcd(S);
if(cw=cw)
returnSi;
}
例如,有三個伺服器A、B和C分別有權值4、3和2,則在一個調度周期內(modsum(W(Si)))調度序列為AABABCABC。加權輪叫調度算法還是比較簡單和高效。當請求的服務時間變化很大,單獨的加權輪叫調度算法依然會導致伺服器間的負載不平衡。
從上面的算法流程中,可以看出當伺服器的權值為零時,該伺服器不被被調度;當所有伺服器的權值為零,即對於任意i有W(Si)=0,則沒有任何伺服器可用,算法返回NULL,所有的新連線都會被丟掉。加權輪叫調度也無需記錄當前所有連線的狀態,所以它也是一種無狀態調度。
最小連線調度
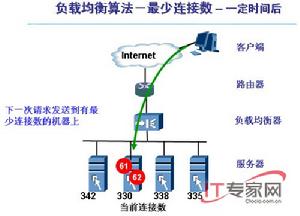 最小連線調度
最小連線調度最小連線調度(Least-Connection Scheduling)算法是把新的連線請求分配到當前連線數最小的伺服器。
最小連線調度是一種動態調度算法,它通過伺服器當前所活躍的連線數來估計伺服器的負載情況。調度器需要記錄各個伺服器已建立連線的數目,當一個請求被調度到某台伺服器,其連線數加1;當連線中止或逾時,其連線數減一。
在系統實現時,也引入當伺服器的權值為零時,表示該伺服器不可用而不被調度,它的算法流程如下:
最小連線調度算法流程
假設有一組伺服器S={S0,S1,...,Sn-1},W(Si)表示伺服器Si的權值,C(Si)表示伺服器Si的當前連線數。
for(m=0;m0){
for(i=m+1;iC(Si)/W(Si)
可以進一步最佳化為
C(Sm)*W(Si)>C(Si)*W(Sm)
同時保證伺服器的權值為零時,伺服器不被調度。所以,算法只要執行以下流程。
for(m=0;m0){
for(i=m+1;iC(Si)*W(Sm))
m=i;
}
returnSm;
}
}
returnNULL;
基於局部性的最少連結調度
基於局部性的最少連結調度(Locality-Based Least Connections Scheduling,以下簡稱為LBLC)算法是針對請求報文的目標IP位址的負載均衡調度,目前主要用於Cache集群系統,因為在Cache集群中客戶請求報文的目標IP位址是變化的。這裡假設任何後端伺服器都可以處理任一請求,算法的設計目標是在伺服器的負載基本平衡情況下,將相同目標IP位址的請求調度到同一台伺服器,來提高各台伺服器的訪問局部性和主存Cache命中率,從而整個集群系統的處理能力。
LBLC調度算法先根據請求的目標IP位址找出該目標IP位址最近使用的伺服器,若該伺服器是可用的且沒有超載,將請求傳送到該伺服器;若伺服器不存在,或者該伺服器超載且有伺服器處於其一半的工作負載,則用“最少連結”的原則選出一個可用的伺服器,將請求傳送到該伺服器。該算法的詳細流程如下:
LBLC調度算法流程
假設有一組伺服器S={S0,S1,...,Sn-1},W(Si)表示伺服器Si的權值,C(Si)表示伺服器Si的當前連線數。ServerNode[dest_ip]是一個關聯變數,表示目標IP位址所對應的伺服器結點,一般來說它是通過Hash表實現的。WLC(S)表示在集合S中的加權最小連線伺服器,即前面的加權最小連線調度。Now為當前系統時間。
if(ServerNode[dest_ip]isNULL)then{
n=WLC(S);
if(nisNULL)thenreturnNULL;
ServerNode[dest_ip].server=n;
}else{
n=ServerNode[dest_ip].server;
if((nisdead)OR
(C(n)>W(n)AND
thereisanodemwithC(m)W(n)AND
thereisanodemwithC(m)1AND
Now-ServerSet[dest_ip].lastmod>T)then{
m=WGC(ServerSet[dest_ip]);
removemfromServerSet[dest_ip];
}
}
ServerSet[dest_ip].lastuse=Now;
if(ServerSet[dest_ip]changed)then
ServerSet[dest_ip].lastmod=Now;
returnn;
此外,對關聯變數ServerSet[dest_ip]也要進行周期性的垃圾回收(GarbageCollection),將過期的目標IP位址到伺服器關聯項進行回收。過期的關聯項是指哪些當前時間(實現時採用系統時鐘節拍數jiffies)減去最近使用時間(lastuse)超過設定過期時間的關聯項,系統預設的設定過期時間為24小時。
目標地址散列調度
目標地址散列調度(Destination Hashing Scheduling)算法也是針對目標IP位址的負載均衡,但它是一種靜態映射算法,通過一個散列(Hash)函式將一個目標IP位址映射到一台伺服器。
目標地址散列調度算法先根據請求的目標IP位址,作為散列鍵(HashKey)從靜態分配的散列表找出對應的伺服器,若該伺服器是可用的且未超載,將請求傳送到該伺服器,否則返回空。該算法的流程如下:
目標地址散列調度算法流程
假設有一組伺服器S={S0,S1,...,Sn-1},W(Si)表示伺服器Si的權值,C(Si)表示伺服器Si的當前連線數。ServerNode[]是一個有256個桶(Bucket)的Hash表,一般來說伺服器的數目會運小於256,當然表的大小也是可以調整的。算法的初始化是將所有伺服器順序、循環地放置到ServerNode表中。若伺服器的連線數目大於2倍的權值,則表示伺服器已超載。
n=ServerNode[hashkey(dest_ip)];
if((nisdead)OR
(W(n)==0)OR
(C(n)>2*W(n)))then
returnNULL;
returnn;
在實現時,採用素數乘法Hash函式,通過乘以素數使得散列鍵值儘可能地達到較均勻的分布。所採用的素數乘法Hash函式如下:
素數乘法Hash函式
staticinlineunsignedhashkey(unsignedintdest_ip)
{
return(dest_ip*2654435761UL)&HASH_TAB_MASK;
}
其中,2654435761UL是2到2^32(4294967296)間接近於黃金分割的素數,(sqrt(5)-1)/2=0.618033989
2654435761/4294967296=0.618033987
源地址散列調度
源地址散列調度(Source Hashing Scheduling)算法正好與目標地址散列調度算法相反,它根據請求的源IP位址,作為散列鍵(HashKey)從靜態分配的散列表找出對應的伺服器,若該伺服器是可用的且未超載,將請求傳送到該伺服器,否則返回空。它採用的散列函式與目標地址散列調度算法的相同。它的算法流程與目標地址散列調度算法的基本相似,除了將請求的目標IP位址換成請求的源IP位址,所以這裡不一一敘述。
在實際套用中,源地址散列調度和目標地址散列調度可以結合使用在防火牆集群中,它們可以保證整個系統的唯一出入口。
動態反饋負載均衡算法
動態反饋負載均衡算法考慮伺服器的實時負載和回響情況,不斷調整伺服器間處理請求的比例,來避免有些伺服器超載時依然收到大量請求,從而提高整個系統的吞吐率。下圖顯示了該算法的工作環境,在負載調度器上運行Monitor Daemon進程,Monitor Daemon來監視和收集各個伺服器的負載信息。Monitor Daemon可根據多個負載信息算出一個綜合負載值。Monitor Daemon將各個伺服器的綜合負載值和當前權值算出一組新的權值,若新權值和當前權值的差值大於設定的閥值,Monitor Daemon將該伺服器的權值設定到核心中的IPVS調度中,而在核心中連線調度一般採用加權輪叫調度算法或者加權最小連線調度算法。
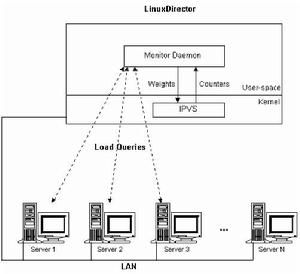 動態反饋負載均衡算法的工作環境
動態反饋負載均衡算法的工作環境連線調度
當客戶通過TCP連線訪問網路訪問時,服務所需的時間和所要消耗的計算資源是千差萬別的,它依賴於很多因素。例如,它依賴於請求的服務類型、當前網路頻寬的情況、以及當前伺服器資源利用的情況。一些負載比較重的請求需要進行計算密集的查詢、資料庫訪問、很長回響數據流;而負載比較輕的請求往往只需要讀一個HTML頁面或者進行很簡單的計算。
請求處理時間的千差萬別可能會導致伺服器利用的傾斜(Skew),即伺服器間的負載不平衡。例如,有一個WEB頁面有A、B、C和D檔案,其中D是大圖像檔案,瀏覽器需要建立四個連線來取這些檔案。當多個用戶通過瀏覽器同時訪問該頁面時,最極端的情況是所有D檔案的請求被發到同一台伺服器。所以說,有可能存在這樣情況,有些伺服器已經超負荷運行,而其他伺服器基本是閒置著。同時,有些伺服器已經忙不過來,有很長的請求佇列,還不斷地收到新的請求。反過來說,這會導致客戶長時間的等待,覺得系統的服務質量差。
簡單連線調度
簡單連線調度可能會使得伺服器傾斜的發生。在上面的例子中,若採用輪叫調度算法,且集群中正好有四台伺服器,必有一台伺服器總是收到D檔案的請求。這種調度策略會導致整個系統資源的低利用率,因為有些資源被用盡導致客戶的長時間等待,而其他資源空閒著。
實際TCP/IP流量的特徵
網路流量是呈波浪型發生的,在一段較長時間的小流量後,會有一段大流量的訪問,然後是小流量,這樣跟波浪一樣周期性地發生。揭示在WAN和LAN上網路流量存在自相似的特徵,在WEB訪問流也存在自相似性。這就需要一個動態反饋機制,利用伺服器組的狀態來應對訪問流的自相似性。
動態反饋負載均衡機制
TCP/IP流量的特徵通俗地說是有許多短事務和一些長事務組成,而長事務的工作量在整個工作量占有較高的比例。所以,要設計一種負載均衡算法,來避免長事務的請求總被分配到一些機器上,而是儘可能將帶有毛刺(Burst)的分布分割成相對較均勻的分布。
提出基於動態反饋負載均衡機制,來控制新連線的分配,從而控制各個伺服器的負載。例如,在IPVS調度器的核心中使用加權輪叫調度(Weighted Round-Robin Scheduling)算法來調度新的請求連線;在負載調度器的用戶空間中運行Monitor Daemon。Monitor Daemon定時地監視和收集各個伺服器的負載信息,根據多個負載信息算出一個綜合負載值。Monitor Daemon將各個伺服器的綜合負載值和當前權值算出一組新的權值。當綜合負載值表示伺服器比較忙時,新算出的權值會比其當前權值要小,這樣新分配到該伺服器的請求數就會少一些。當綜合負載值表示伺服器處於低利用率時,新算出的權值會比其當前權值要大,來增加新分配到該伺服器的請求數。若新權值和當前權值的差值大於設定的閥值,Monitor Daemon將該伺服器的權值設定到核心中的IPVS調度中。過了一定的時間間隔(如2秒鐘),Monitor Daemon再查詢各個伺服器的情況,並相應調整伺服器的權值;這樣周期性地進行。可以說,這是一個負反饋機制,使得伺服器保持較好的利用率。
在加權輪叫調度算法中,當伺服器的權值為零,已建立的連線會繼續得到該伺服器的服務,而新的連線不會分配到該伺服器。系統管理員可以將一台伺服器的權值設定為零,使得該伺服器安靜下來,當已有的連線都結束後,他可以將該伺服器切出,對其進行維護。維護工作對系統都是不可少的,比如硬體升級和軟體更新等,零權值使得伺服器安靜的功能很主要。所以,在動態反饋負載均衡機制中我們要保證該功能,當伺服器的權值為零時,我們不對伺服器的權值進行調整。
綜合負載
在計算綜合負載時,主要使用兩大類負載信息:輸入指標和伺服器指標。輸入指標是在調度器上收集到的,而伺服器指標是在伺服器上的各種負載信息。用綜合負載來反映伺服器當前的比較確切負載情況,對於不同的套用,會有不同的負載情況,這裡引入各個負載信息的係數,來表示各個負載信息在綜合負載中輕重。系統管理員根據不同套用的需求,調整各個負載信息的係數。另外,系統管理員設定收集負載信息的時間間隔。
輸入指標主要是在單位時間內伺服器收到新連線數與平均連線數的比例,它是在調度器上收集到的,所以這個指標是對伺服器負載情況的一個估計值。在調度器上有各個伺服器收到連線數的計數器,對於伺服器Si,可以得到分別在時間T1和T2時的計數器值Ci1和Ci2,計算出在時間間隔T2-T1內伺服器Si收到新連線數Ni=Ci2-Ci1。這樣,得到一組伺服器在時間間隔T2-T1內伺服器Si收到新連線數{Ni},伺服器Si的輸入指標INPUTi為其新連線數與n台伺服器收到平均連線數的比值,其公式為
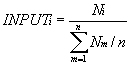 LVS負載調度
LVS負載調度伺服器指標主要記錄伺服器各種負載信息,如伺服器當前CPU負載LOADi、伺服器當前磁碟使用情況Di、當前記憶體利用情況Mi和當前進程數目Pi。有兩種方法可以獲得這些信息;一是在所有的伺服器上運行著SNMP(Simple Network Management Protocol)服務進程,而在調度器上的Monitor Daemon通過SNMP向各個伺服器查詢獲得這些信息;二是在伺服器上實現和運行收集信息的Agent,由Agent定時地向Monitor Daemon報告負載信息。若伺服器在設定的時間間隔內沒有回響,Monitor Daemon認為伺服器是不可達的,將伺服器在調度器中的權值設定為零,不會有新的連線再被分配到該伺服器;若在下一次伺服器有回響,再對伺服器的權值進行調整。再對這些數據進行處理,使其落在[0,∞)的區間內,1表示負載正好,大於1表示伺服器超載,小於1表示伺服器處於低負載狀態。獲得調整後的數據有DISKi、MEMORYi和PROCESSi。
另一個重要的伺服器指標是伺服器所提供服務的回響時間,它能比較好地反映伺服器上請求等待佇列的長度和請求的處理時間。調度器上的Monitor Daemon作為客戶訪問伺服器所提供的服務,測得其回響時間。例如,測試從WEB伺服器取一個HTML頁面的回響延時,Monitor Daemon只要傳送一個“GET/”請求到每個伺服器,然後記錄回響時間。若伺服器在設定的時間間隔內沒有回響,MonitorDaemon認為伺服器是不可達的,將伺服器在調度器中的權值設定為零。同樣,我們對回響時間進行如上調整,得到RESPONSEi。
這裡,引入一組可以動態調整的係數Ri來表示各個負載參數的重要程度,其中ΣRi=1。綜合負載可以通過以下公式計算出:
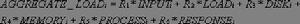 LVS負載調度
LVS負載調度例如,在WEB伺服器集群中,採用以下係數{0.1,0.3,0.1,0.1,0.1,0.3},認為伺服器的CPU負載和請求回響時間較其他參數重要一些。若當前的係數Ri不能很好地反映套用的負載,系統管理員可以對係數不斷地修正,直到找到貼近當前套用的一組係數。
另外,關於查詢時間間隔的設定,雖然很短的間隔可以更確切地反映各個伺服器的負載,但是很頻繁地查詢(如1秒鐘幾次)會給調度器和伺服器帶來一定的負載,如頻繁執行的MonitorDaemon在調度器會有一定的開銷,同樣頻繁地查詢伺服器指標會伺服器帶來一定的開銷。所以,這裡要有個折衷(tradeoff),一般建議將時間間隔設定在5到20秒之間。
權值計算
當伺服器投入集群系統中使用時,系統管理員對伺服器都設定一個初始權值DEFAULT_WEIGHTi,在核心的IPVS調度中也先使用這個權值。然後,隨著伺服器負載的變化,對權值進行調整。為了避免權值變成一個很大的值,我們對權值的範圍作一個限制[DEFAULT_WEIGHTi,SCALE*DEFAULT_WEIGHTi],SCALE是可以調整的,它的預設值為10。
Monitor Daemon周期性地運行,若DEFAULT_WEIGHTi不為零,則查詢該伺服器的各負載參數,並計算出綜合負載值AGGREGATE_LOADi。引入以下權值計算公式,根據伺服器的綜合負載值調整其權值。
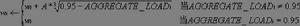 LVS負載調度
LVS負載調度在公式中,0.95是想要達到的系統利用率,A是一個可調整的係數(預設值為5)。當綜合負載值為0.95時,伺服器權值不變;當綜合負載值大於0.95時,權值變小;當綜合負載值小於0.95時,權值變大。若新權值大於SCALE*DEFAULT_WEIGHTi,我們將新權值設為SCALE*DEFAULT_WEIGHTi。若新權值與當前權值的差異超過設定的閥值,則將新權值設定到核心中的IPVS調度參數中,否則避免打斷IPVS調度的開銷。可以看出這是一個負反饋公式,會使得權值調整到一個穩定點,如系統達到理想利用率時,權值是不變的。
在實際使用中,若發現所有伺服器的權值都小於他們的DEFAULT_WEIGHT,則說明整個伺服器集群處於超載狀態,這時需要加入新的伺服器結點到集群中來處理部分負載;反之,若所有伺服器的權值都接近於SCALE*DEFAULT_WEIGHT,則說明當前系統的負載都比較輕。
一個實現例子
在RedHat集群管理工具Piranha中實現了一個簡單的動態反饋負載均衡算法。在綜合負載上,它只考慮伺服器的CPU負載(LoadAverage),使用以下公式進行權值調整:
 LVS負載調度
LVS負載調度伺服器權值調整區間為[DEFAULT_WEIGHTi,10*DEFAULT_WEIGHTi],A為DEFAULT_WEIGHTi/2,而權值調整的閥值為DEFAULT_WEIGHTi/4。1是所想要達到的系統利用率。Piranha每隔20秒查詢各台伺服器的CPU負載,進行權值計算和調整。
總結
主要講述了IP虛擬伺服器在核心中實現的八種連線調度算法:
輪叫調度(Round-Robin Scheduling)
加權輪叫調度(Weighted Round-Robin Scheduling)
最小連線調度(Least-Connection Scheduling)
加權最小連線調度(Weighted Least-Connection Scheduling)
基於局部性的最少連結(Locality-Based Least Connections Scheduling)
帶複製的基於局部性最少連結(Locality-Based Least Connections with Replication Scheduling)
目標地址散列調度(Destination Hashing Scheduling)
源地址散列調度(Source Hashing Scheduling)
因為請求的服務時間差異較大,核心中的連線調度算法容易使得伺服器運行出現傾斜。為此,給出了一個動態反饋負載均衡算法,結合核心中的加權連線調度算法,根據動態反饋回來的負載信息來調整伺服器的權值,來調整伺服器間處理請求數的比例,從而避免伺服器間的負載不平衡。動態反饋負載算法可以較好地避免伺服器的傾斜,提高系統的資源使用效率,從而提高系統的吞吐率。
