編碼方法
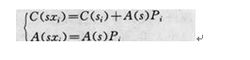 圖1
圖1若有一個a、b、c、d四種符號的單符號信源,待編序列為S=abda,已知:
符號a b c d
符號機率Pi 0.100 0.010 0.001 0.001
(以二進位小數表示)
累積機率∑pi 0.000 0.100 0.110 0.111
 圖2
圖2按照一定精度的數值作為序列的算術編碼,實質上是分割單位區間的過程。實現它,必須完成兩個遞推過程:一個代表碼字C(·),另一個代表區間寬度為A(·)。若記SXi表示S的增長(即S後增加一個符號Xi)序列。則有圖1 。
若記λ為空序列,有A(λ)=1,C(λ)=0,則有如圖2 。
並依次求得:C(abd)= 010111, A(abd)= 0.00001
C(abda)= 0.010111 ,A(abda)= 0.000001 該編碼過程可以用圖3所示的單位區間劃分的過程來描述。
圖3解碼為逆遞推過程,可以通過對編碼後的數值進行比較來實現。即判斷C(S)落入哪一個區間,最後得出一個相應的符號序列S'=Ma=S。
實際的編解碼過程比較複雜,但原理相同,算術編碼的理論性能也可使平均符號代碼長度接近符號熵,而且對二元信源的編碼實現比較簡單,故受重視。中國將它套用於報紙傳真的壓縮設備中,獲得了良好的效果。
工作原理
在給定符號集和符號機率的情況下,算術編碼可以給出接近最優的編碼結果。使用算術編碼的壓縮算法通常先要對輸入符號的機率進行估計,然後再編碼。這個估計越準,編碼結果就越接近最優的結果。
例: 對一個簡單的信號源進行觀察,得到的統計模型如下:
60% 的機會出現符號 中性
20% 的機會出現符號 陽性
10% 的機會出現符號 陰性
10% 的機會出現符號 數據結束符. (出現這個符號的意思是該信號源'內部中止',在進行數據壓縮時這樣的情況是很常見的。當第一次也是唯一的一次看到這個符號時,解碼器就知道整個信號流都被解碼完成了。)
算術編碼可以處理的例子不止是這種只有四種符號的情況,更複雜的情況也可以處理,包括高階的情況。所謂高階的情況是指當前符號出現的機率受之前出現符號的影響,這時候之前出現的符號,也被稱為上下文。比如在英文文檔編碼的時候,例如,在字母Q或者q出現之後,字母u出現的機率就大大提高了。這種模型還可以進行自適應的變化,即在某種上下文下出現的機率分布的估計隨著每次這種上下文出現時的符號而自適應更新,從而更加符合實際的機率分布。不管編碼器使用怎樣的模型,解碼器也必須使用同樣的模型。
編碼過程的每一步,除了最後一步,都是相同的。編碼器通常需要考慮下面三種數據:
下一個要編碼的符號
當前的區間(在編第一個符號之前,這個區間是[0,1), 但是之後每次編碼區間都會變化)
編碼器將當前的區間分成若干子區間,每個子區間的長度與當前上下文下可能出現的對應符號的機率成正比。當前要編碼的符號對應的子區間成為在下一步編碼中的初始區間。
例: 對於前面提出的4符號模型:
中性對應的區間是 [0, 0.6)
陽性對應的區間是 [0.6, 0.8)
陰性對應的區間是 [0.8, 0.9)
數據結束符對應的區間是 [0.9, 1)
當所有的符號都編碼完畢,最終得到的結果區間即唯一的確定了已編碼的符號序列。任何人使用該區間和使用的模型參數即可以解碼重建得到該符號序列。
實際上我們並不需要傳輸最後的結果區間,實際上,我們只需要傳輸該區間中的一個小數即可。在實用中,只要傳輸足夠的該小數足夠的位數(不論幾進制),以保證以這些位數開頭的所有小數都位於結果區間就可以了。
例: 下面對使用前面提到的4符號模型進行編碼的一段信息進行解碼。編碼的結果是0.538(為了容易理解,這裡使用十進制而不是二進制;我們也假設我們得到的結果的位數恰好夠我們解碼。下面會討論這兩個問題)。
像編碼器所作的那樣我們從區間[0,1)開始,使用相同的模型,我們將它分成編碼器所必需的四個子區間。分數0.538落在NEUTRAL坐在的子區間[0,0.6);這向我們提示編碼器所讀的第一個符號必然是NEUTRAL,這樣我們就可以將它作為訊息的第一個符號記下來。
然後我們將區間[0,0.6)分成子區間:
中性 的區間是 [0, 0.36) -- [0, 0.6) 的 60%
陽性 的區間是 [0.36, 0.48) -- [0, 0.6) 的 20%
陰性 的區間是 [0.48, 0.54) -- [0, 0.6) 的 10%
數據結束符 的區間是 [0.54, 0.6). -- [0, 0.6) 的 10%
我們的分數 .538 在 [0.48, 0.54) 區間;所以訊息的第二個符號一定是NEGATIVE。
我們再一次將當前區間劃分成子區間:
中性 的區間是 [0.48, 0.516)
陽性 的區間是 [0.516, 0.528)
陰性 的區間是 [0.528, 0.534)
數據結束符 的區間是 [0.534, 0.540).
我們的分數 .538 落在符號 END-OF-DATA 的區間;所以,這一定是下一個符號。由於它也是內部的結束符號,這也就意味著編碼已經結束。(如果數據流沒有內部結束,我們需要從其它的途徑知道數據流在何處結束--否則我們將永遠將解碼進行下去,錯誤地將不屬於實際編碼生成的數據讀進來。)
同樣的訊息能夠使用同樣短的分數來編碼實現如 .534、.535、.536、.537或者是.539,這表明使用十進制而不是二進制會帶來效率的降低。這是正確的是因為三位十進制數據能夠表達的信息內容大約是9.966位;我們也能夠將同樣的信息使用二進制分數表示為.10001010(等同於0.5390625),它僅需8位。這稍稍大於信息內容本身或者訊息的信息熵,大概是機率為0.6%的 7.361位信息熵。(注意最後一個0必須在二進制分數中表示,否則訊息將會變得不確定起來。)
編碼過程
算術編碼是用符號的機率和它的編碼間隔兩倆個基本參數來描述的(見下文教程)。算術編碼可以是靜態的或是自適應的。在靜態算術編碼中,信源符號的機率是固定的。在自適應算術編碼中,信源符號的機率根據編碼時符號出現的頻繁程度動態地進行修改。
在編碼期間估算信源符號機率的過程叫建模。需要開發動態算術編碼的原因,是因為事先知道精確的信源符號機率是很難的,而且是不切實際的。動態建模是確定編碼器壓縮效率的關鍵。
概述
算術編碼 是一種無損數據壓縮方法,也是一種熵編碼的方法。和其它熵編碼方法不同的地方在於,其他的熵編碼方法通常是把輸入的訊息分割為符號,然後對每個符號進行編碼,而算術編碼是直接把整個輸入的訊息編碼為一個數,一個滿足(0.0 ≤ n < 1.0)的小數n。
笨笨數據壓縮教程例如
算術編碼對某條信息的輸出為 1010001111,那么它表示小數 0.1010001111,也即十進制數 0.64。
暫時使用十進制表示算法中出現的小數,這絲毫不會影響算法的可行性。
考慮某條信息中可能出現的字元僅有 a b c 三種,要壓縮保存的信息為 bccb。
採用的是自適應模型,開始時暫時認為三者的出現機率相等,也就是都為 1/3,將 0 - 1 區間按照機率的比例分配給三個字元,即 a 從 0.0000 到 0.3333,b 從 0.3333 到 0.6667,c 從 0.6667 到 1.0000。用圖形表示就是:
+-- 1.0000
|
Pc = 1/3 |
|
+-- 0.6667
|
Pb = 1/3 |
|
+-- 0.3333
|
Pa = 1/3 |
|
+-- 0.0000
現在拿到第一個字元 b,把目光投向 b 對應的區間 0.3333 - 0.6667。這時由於多了字元 b,三個字元的機率分布變成:Pa = 1/4,Pb = 2/4,Pc = 1/4。好,按照新的機率分布比例劃分 0.3333 - 0.6667 這一區間,劃分的結果可以用圖形表示為:
+-- 0.6667
Pc = 1/4 |
+-- 0.5834
|
|
Pb = 2/4 |
|
|
+-- 0.4167
Pa = 1/4 |
+-- 0.3333
接著拿到字元 c,現在要關註上一步中得到的 c 的區間 0.5834 - 0.6667。新添了 c 以後,三個字元的機率分布變成 Pa = 1/5,Pb = 2/5,Pc = 2/5。用這個機率分布劃分區間 0.5834 - 0.6667:
+-- 0.6667
|
Pc = 2/5 |
|
+-- 0.6334
|
Pb = 2/5 |
|
+-- 0.6001
Pa = 1/5 |
+-- 0.5834
現在輸入下一個字元 c,三個字元的機率分布為:Pa = 1/6,Pb = 2/6,Pc = 3/6。來劃分 c 的區間 0.6334 - 0.6667:
+-- 0.6667
|
|
Pc = 3/6 |
|
|
+-- 0.6501
|
Pb = 2/6 |
|
+-- 0.6390
Pa = 1/6 |
+-- 0.6334
輸入最後一個字元 b,因為是最後一個字元,不用再做進一步的劃分了,上一步中得到的 b 的區間為 0.6390 - 0.6501,好,在這個區間內隨便選擇一個容易變成二進制的數,例如 0.64,將它變成二進制 0.1010001111,去掉前面沒有太多意義的 0 和小數點,我們可以輸出 1010001111,這就是信息被壓縮後的結果,就完成了一次最簡單的算術壓縮過程。
相關介紹
精度和再歸一化
上面對算術編碼的解釋進行了一些簡化。尤其是,這種寫法看起來好像算術編碼首先使用無限精度精度的數值計算總體上表示最後節點的分數,然後在編碼結束的時候將這個分數轉換成最終的形式。許多算術編碼器使用優先精度的數值計算,而不是儘量去模擬無限精度,因為它們知道解碼器能夠匹配、並且將所計算的分數在那個精度四捨五入到對應值。一個例子能夠說明一個模型要將間隔[0,1]分成三份並且使用8位的精度來實現。注意既然精度已經知道,我們能用的二進制數值的範圍也已經知道。
一個稱為再歸一化的過程使有限精度不再是能夠編碼的字元數目的限制。當範圍減小到範圍內的所有數值共享特定的數字時,那些數字就送到輸出數據中。儘管計算機能夠處理許多位數的精度,編碼所用位數少於它們的精度,這樣現存的數據進行左移,在右面添加新的數據位以儘量擴展能用的數據範圍。注意這樣的結果出現在前面三個例子中的兩個裡面。
美國專利
許多算術編碼所用的不同方法受美國專利的保護。其中一些專利對於實現一些國際標準中定義的算術編碼算法是很關鍵的。在這種情況下,這些專利通常按照一種合理和非歧視(RAND)授權協定使用(至少是作為標準委員會的一種策略)。在一些著名的案例中(包括一些涉及 IBM的專利)這些授權是免費的,而在另外一些案例中,則收取一定的授權費用。RAND條款的授權協定不一定能夠滿足所有打算使用這項技術的用戶,因為對於一個打算生產擁有所有權軟體的公司來說這項費用是“合理的”,而對於自由軟體和開源軟體項目來說它是不合理的。
在算術編碼領域做了很多開創性工作並擁有很多專利的一個著名公司是IBM。一些分析人士感到那種認為沒有一種實用並且有效的算術編碼能夠在不觸犯IBM和其它公司擁有的專利條件下實現只是數據壓縮界中的一種持續的urban legend(尤其是當看到有效的算術編碼已經使用了很長時間最初的專利開始到期)。然而,由於專利法沒有提供“明確界線”測試所以一種威懾心理總讓人擔憂法庭將會找到觸犯專利的特殊套用,並且隨著對於專利範圍的詳細審查將會發現一個不好的裁決將帶來很大的損失,這些技術的專利保護然而對它們的套用產生了一種阻止的效果。至少一種重要的壓縮軟體bzip2,出於對於專利狀況的擔心,故意停止了算術編碼的使用而轉向Huffman編碼。
關於算術編碼的美國專利列在下面。
Patent 4,122,440 — (IBM) 提交日期 March 4, 1977, 批准日期 Oct 24, 1978 (現在已經到期)
Patent 4,286,256 — (IBM) 批准日期 Aug 25, 1981 (大概已經到期)
Patent 4,467,317 — (IBM) 批准日期 Aug 21, 1984 (大概已經到期)
Patent 4,652,856 — (IBM) 批准日期 Feb 4, 1986 (大概已經到期)
Patent 4,891,643 — (IBM) 提交時間 1986/09/15, 批准日期 1990/01/02
Patent 4,905,297 — (IBM) 批准日期 Feb 27, 1990
Patent 4,933,883 — (IBM) 批准日期 Jun 12, 1990
Patent 4,935,882 — (IBM) 批准日期 Jun 19, 1990
Patent 4,989,000 — (?) 提交時間 1989/06/19, 批准日期 1991/01/29
Patent 5,099,440
Patent 5,272,478 — (Ricoh)
注意:這個列表沒有囊括所有的專利。關於更多的專利信息請參見後面的連結。
算術編碼的專利可能在其它國家司法領域存在,參見軟體專利中關於軟體在世界各地專利性的討論。
參考
數據壓縮
區間編碼
哈夫曼編碼
熵編碼
