
概述
 囚犯困境
囚犯困境在重複的囚徒困境中,博弈被反覆地進行。因而每個參與者都有機會去“懲罰”另一個參與者前一回合的不合作行為。這時,合作可能會作為均衡的結果出現。欺騙的動機這時可能被受到懲罰的威脅所克服,從而可能導向一個較好的、合作的結果。作為反覆接近無限的數量,納什均衡趨向於帕累托最優。
囚犯困境的主旨為,囚犯們雖然彼此合作,堅不吐實,可為全體帶來最佳利益(無罪開釋),但在資訊不明的情況下,因為出賣同夥可為自己帶來利益(縮短刑期),也因為同夥把自己招出來可為他帶來利益,因此彼此出賣雖違反最佳共同利益,反而是自己最大利益所在。但實際上,執法機構不可能設立如此情境來誘使所有囚犯招供,因為囚犯們必須考慮刑期以外之因素(出賣同夥會受到報復等),而無法完全以執法者所設立之利益(刑期)作考量。
發展理論
 囚犯困境
囚犯困境1950年,由就職於蘭德公司的梅里爾·弗勒德(MerrillFlood)和梅爾文·德雷希爾(MelvinDresher)擬定出相關困境的理論,後來由顧問艾伯特·塔克(AlbertTucker)以囚犯方式闡述,並命名為“囚犯困境”。經典的囚犯困境如下:
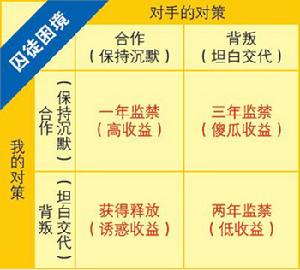
警方逮捕甲、乙兩名嫌疑犯,但沒有足夠證據指控二人入罪。於是警方分開囚禁嫌疑犯,分別和二人見面,並向雙方提供以下相同的選擇:
若一人認罪並作證檢控對方(相關術語稱“背叛”對方),而對方保持沉默,此人將即時獲釋,沉默者將判監10年。若二人都保持沉默(相關術語稱互相“合作”),則二人同樣判監半年。若二人都互相檢舉(互相“背叛”),則二人同樣判監2年。
如同博弈論的其他例證,囚犯困境假定每個參與者(即“囚犯”)都是利己的,即都尋求最大自身利益,而不關心另一參與者的利益。參與者某一策略所得利益,如果在任何情況下都比其他策略要低的話,此策略稱為“嚴格劣勢”,理性的參與者絕不會選擇。另外,沒有任何其他力量干預個人決策,參與者可完全按照自己意願選擇策略。
說法
囚犯到底應該選擇哪一項策略,才能將自己個人的刑期縮至最短?兩名囚犯由於隔絕監禁,並不知道對方選擇;而即使他們能交談,還是未必能夠盡信對方不會反口。就個人的理性選擇而言,檢舉背叛對方所得刑期,總比沉默要來得低。試構想困境中兩名理性囚犯會如何作出選擇:
若對方沉默、背叛會讓我獲釋,所以會選擇背叛。若對方背叛指控我,我也要指控對方才能得到較低的刑期,所以也是會選擇背叛。二人面對的情況一樣,所以二人的理性思考都會得出相同的結論——選擇背叛。背叛是兩種策略之中的支配性策略。因此,這場博弈中唯一可能達到的納什均衡,就是雙方參與者都背叛對方,結果二人同樣服刑2年。
這場博弈的納什均衡,顯然不是顧及團體利益的帕累托最優解決方案。以全體利益而言,如果兩個參與者都合作保持沉默,兩人都只會被判刑半年,總體利益更高,結果也比兩人背叛對方、判刑2年的情況較佳。但根據以上假設,二人均為理性的個人,且只追求自己個人利益。均衡狀況會是兩個囚犯都選擇背叛,結果二人判決均比合作為高,總體利益較合作為低。這就是“困境”所在。例子漂亮地證明了:非零和博弈中,帕累托最優和納什均衡是相衝突的。
現實套用
 無論是人類社會或大自然都可以找到類似囚犯困境的例子,將結果劃成同樣的支付矩陣。社會科學中的經濟學、政治學和社會學,以及自然科學的動物行動學、進化生物學等學科,都可以用囚犯困境分析,模擬生物面對無止境的囚犯困境博弈。囚犯困境可以廣為使用,說明這種博弈的重要性。以下為各界例子:
無論是人類社會或大自然都可以找到類似囚犯困境的例子,將結果劃成同樣的支付矩陣。社會科學中的經濟學、政治學和社會學,以及自然科學的動物行動學、進化生物學等學科,都可以用囚犯困境分析,模擬生物面對無止境的囚犯困境博弈。囚犯困境可以廣為使用,說明這種博弈的重要性。以下為各界例子:政治學例子:軍備競賽
在政治學中,兩國之間的軍備競賽可以用囚犯困境來描述。兩國都可以聲稱有兩種選擇:增加軍備(背叛)、或是達成削減武器協定(合作)。兩國都無法肯定對方會遵守協定,因此兩國最終會傾向增加軍備。似乎自相矛盾的是,雖然增加軍備會是兩國的“理性”行為,但結果卻顯得“非理性”(例如會對經濟造成都有損壞等)。這可視作遏制理論的推論,就是以強大的軍事力量來遏制對方的進攻,以達到和平。
經濟學例子:關稅戰
兩個國家,在關稅上可以有以兩個選擇:提高關稅,以保護自己的商品。(背叛)
與對方達成關稅協定,降低關稅以利各自商品流通。(合作)
當一國因某些因素不遵守關稅協定,獨自提高關稅(背叛),另一國也會作出同樣反應(亦背叛),這就引發了關稅戰,兩國的商品失去了對方的市場,對本身經濟也造成損害(共同背叛的結果)。然後二國又重新達成關稅協定。(重複博弈的結果是將發現共同合作利益最大。)
商業例子:廣告戰
商業活動中亦會出現各種囚犯困境例子。以廣告競爭為例。兩個公司互相競爭,二公司的廣告互相影響,即一公司的廣告較被顧客接受則會奪取對方的部分收入。但若二者同時期發出質量類似的廣告,收入增加很少但成本增加。但若不提高廣告質量,生意又會被對方奪走。此二公司可以有二選擇:互相達成協定,減少廣告的開支。增加廣告開支,設法提升廣告的質量,壓倒對方。若二公司不信任對方,無法合作,背叛成為支配性策略時,二公司將陷入廣告戰,而廣告成本的增加損害了二公司的收益,這就是陷入囚犯困境。在現實中,要二互相競爭的公司達成合作協定是較為困難的,多數都會陷入囚犯困境中。
腳踏車賽例子
腳踏車賽事的比賽策略也是一種博弈,而其結果可用囚犯困境的研究成果解釋。例如每年都舉辦的環法自由車賽中有以下情況:選手們在到終點前的路程常以大隊伍(英文:Peloton)方式前進,他們採取這策略是為了令自己不至於太落後,又出力適中。而最前方的選手在迎風時是最費力的,所以選擇在前方是最差的策略。通常會發生這樣的情況,大家起先都不願意向前(共同背叛),這使得全體速度很慢,而後通常會有二或多位選手騎到前面,然後一段時間內互相交換最前方位置,以分擔風的阻力(共同合作),使得全體的速度有所提升,而這時如果前方的其中一人試圖一直保持前方位置(背叛),其他選手以及大隊伍就會趕上(共同背叛)。而通常的情況是,在最前面次數最多的選手(合作)通常會到最後被落後的選手趕上(背叛),因為後面的選手騎在前面選手的沖流之中,比較不費力。
重複困境
困境。就是說只有二方的囚徒困境,沒有多方的。所謂多方的囚徒困境只是由多個二方囚徒困境混雜在一起而形成的錯覺。羅伯特·阿克塞爾羅德在其著作《合作的進化》中,探索了經典囚徒困境情景的一個擴展,並把它稱作“重複的囚徒困境”(IPD)。在這個博弈中,參與者必須反覆地選擇他們彼此相關的策略,並且記住他們以前的對抗。阿克塞爾羅德邀請全世界的學術同行來設計計算機策略,並在一個重複囚徒困境競賽中互相競爭。參賽的程式的差異廣泛地存在於這些方面:算法的複雜性、最初的對抗、寬恕的能力等等。阿克塞爾羅德發現,當這些對抗被每個選擇不同策略的參與者一再重複了很長時間之後,從利己的角度來判斷,最終“貪婪”策略趨向於減少,而比較“利他”策略更多地被採用。他用這個博弈來說明,通過自然選擇,一種利他行為的機制可能從最初純粹的自私機制進化而來。
最佳確定性策略被認為是“以牙還牙”,這是阿納托爾·拉波波特(AnatolRapoport)開發並運用到錦標賽中的方法。它是所有參賽程式中最簡單的,只包含了四行BASIC語言,並且贏得了比賽。這個策略只不過是在重複博弈的開頭合作,然後,採取你的對手前一回合的策略。更好些的策略是“寬恕地以牙還牙”。當你的對手背叛,在下一回合中你無論如何要以小機率(大約是1%~5%)時而合作一下。這是考慮到偶爾要從循環背叛的受騙中復原。當錯誤傳達被引入博弈時,“寬恕地以牙還牙”是最佳的。這意味著有時你的動作被錯誤地傳達給你的對手:你合作但是你的對手聽說你背叛了。
通過分析高分策略,阿克塞爾羅德指定了策略獲得成功的幾個必要條件。
1、友善。最重要的條件是策略必須“友善”,這就是說,不要在對手背叛之前先背叛。幾乎所有的高分策略都是友善的。因此,完全自私的策略僅僅出於自私的原因,也永遠不會首先打擊其對手。
2、報復。但是,阿克斯洛德主張,成功的策略必須不是一個盲目樂觀者。要始終報復。一個非報復策略的例子是始終合作。這是一個非常糟糕的選擇,因為“下流”策略將殘酷地剝削這樣的傻瓜。
3、寬恕。成功策略的另一個品質是必須要寬恕。雖然它們不報復,但是如果對手不繼續背叛,它們會一再退卻到合作。這停止了報復和反報復的長期進行,最大化了得分點數。
4、不嫉妒。最後一個品質是不嫉妒,就是說不去爭取得到高於對手的分數(對於“友善”的策略來說這也是不可能的,也就是說“友善”的策略永遠無法得到高於對手的分數)。
因此,阿克塞爾羅德得到一種給人以烏托邦印象的結論,認為自私的個人為了其自私的利益會趨向友善、寬恕和不嫉妒。阿克塞爾羅德關於重複囚徒困境的研究的重要結論之一,是友善的傢伙能先完成交易。重新考慮經典的囚徒困境一節中給定的軍備競賽模型:結論是,只是理性策略增進了軍事力量,似乎兩個國家都寧可花費其GDP在槍炮而不是黃油上。有趣的是,企圖說明對抗國家實際上以這種方式(在“重複囚徒困境假定”下的不同時期,軍費支出在“高”和“低”之間反覆)競賽的嘗試,卻經常表明假定的軍備競賽並沒有如預想的那樣出現。(例如希臘人和土耳其人的軍費支出,看來並不像遵循“以牙還牙”的重複囚徒困境式的軍備競賽,卻更可能是被其國內的政策所驅使。)這可能是一次性博弈和重複性博弈中的理性行為不同的例子。
對一次性囚徒困境博弈來說,最佳(點數最大化的)策略是簡單地背叛;正如前面解釋的,無論對手的行動可能是什麼,這都是真實的。但是,在重複的囚徒困境博弈中,最佳策略依賴於可能的對手的策略,和他們怎樣對背叛和合作作出反應。例如,考慮這樣一個人群,那裡每個人每次都背叛,除了一個人是遵循以牙還牙策略。這個人處於一種輕微的不利地位,因為第一回合的損失。在這樣的人群中,對這個人來說最佳策略就是每次都背叛。在一個有一定的百分比的總背叛者而剩下的則是以牙還牙者的人群中,對個人來說的最佳策略依賴於這個百分比和博弈的長度。
一般有兩種方法得到最佳策略:貝葉斯納什均衡:如果對抗策略的統計分布能被確定(例如,50%以牙還牙,50%一直合作),就能從數學上獲得最佳的相對策略。已經有了人群的蒙特卡羅模擬,在這裡低分個人消失了,高分個人一再被生產出來(一種獲得最佳策略的天才算法)。決賽人群中的算法合成通常依賴於初賽人群中的算法合成。儘管以牙還牙始終被認為是最可靠的基本策略,但是在重複囚徒困境的20周年紀念賽中,來英國南安普敦大學的一個小組(由尼古拉斯·詹寧斯(NicholasJennings)領導,包括了拉蒂普·達什(RajdeepDash)、薩瓦帕里·拉姆瓊(SarvapaliRamchurn)、亞歷克斯·羅傑斯(AlexRogers)斯和皮魯克里士南·維特林根(PerukrishnenVytelingum))介紹了一個新的策略,這個策略證明了它比以牙還牙更成功。這個策略依賴於程式之間的合作,為單一程式中獲得了最高的點數。南安普敦大學提交了60個程式參與競賽,這些程式的開頭被設計成通過一組5到10個的動作去彼此識別。一旦這些識別被作出,一個程式將總是合作,其他程式則總是背叛,保證背叛者得到最大的點數。如果程式識別出它在操作一個非南安普敦參與者,這程式將持續地背叛,企圖去最小化競爭程式的得分。結果[5],這個策略以獲得前3位結束了競賽,也得到了大量接近底部的位置。雖然這個策略顯著地證明了比以牙還牙有效,但是這是因為利用了下述事實:在這個特殊的競賽中,多重通道是被允許的。在一方只能控制單一參與者的競賽中,以牙還牙確實是更好的策略。
如果重複囚徒困境將被精確地重複N次,已知N是一個常數,那么會產生另一個有趣的事實。納什均衡就是每次都背叛。這很容易用歸納法證明。你也可以在最後的回合背叛,既然你的對手將沒有機會懲罰你。因此,你們都將在最後的回合背叛。這時,你可以在倒數第二回合中背叛,既然最後一回無論你做什麼,你的對手都將背叛。依此類推。為了合作以保持請求,這時未來必須對兩個參與者來說是不確定的。一個解決方案是讓博弈總次數N變成隨機的。對未來的預期必須是無法確定的長度。
另一個單獨的案例是“永不停止”的囚徒困境。這個博弈被重複很多次,而且你的分數是一個平均數(當然是用計算機計算的)。囚徒困境博弈是某些人類合作和信任理論的基礎。假定囚徒困境能夠模擬需要信任的兩人之間的交流,群體的合作行為可以用有多個參與者的、重複博弈的變體來模擬。這從而引起了許許多多學者經久不衰的興趣。1975年,格羅夫曼(Grofman)和普爾(Pool)估計,致力於這方面研究的學術文章,數量超過2000篇。
學習心理學和博弈論。當博弈參與者能學會估計其他參與者背叛的可能性,他們自身的行為就為他們關於其他人的經驗所影響。簡單的統計顯示,總體上,缺乏經驗的參與者與其他參與者的互動,或者是典型的好,或者是典型的壞。如果他們在這些經驗的基礎上行動,(通過更多的背叛或合作,否則)他們可能在未來的交易中受損。隨著經驗逐漸豐富,他們獲得了對背叛可能性的更真實的印象,變得更成功地參與博弈。不成熟的參與者經歷的早期交易對他們未來參與的影響,可能比這些交易對成熟的參與者的影響要大得多。這個原理部分地解釋了,為什麼年輕人的成長經驗這么具有影響力,以及為什麼他們特別容易被欺負,有時他們本身最後也成為欺凌弱小者。
群體中背叛的可能性,可以被合作的經驗所削弱,因為先前的博弈建立了信任。因此自我犧牲行為可以,例如,加強團體的道德品質。如果團體很小,積極行為更可能以互相肯定的方式——鼓勵這個團體中的個人繼續合作——得到反饋。這與相似的困境有關:鼓勵那些你將援助的人,從可能使他們處於危險的境地的行為中得到滿足。這類方法主要在互惠利他主義、群選擇、血緣選擇和道德哲學的研究中涉及。
相關博弈
封閉袋子交易霍夫施塔特2曾提出,像囚徒困境一類的問題,若以簡單博弈的形式來說明,人們會較容易理解。例如他以“封閉袋子交易”的簡單博弈來說明此論題:兩人面對面互相交換封閉的袋子,共同了解其中一方放錢,另一方放商品。雙方可以誠實的依照承諾,把東西放到袋子裡交換;又或者交空袋子給對方,選擇背叛。在這場博弈中,由於背叛可獲得巨大利益,必然有多人選擇背叛。這意味著理性的商人不會進行這種交易,因而“封閉袋子交易”將由於逆向選擇而失去市場。
是敵是友?
“是敵是友?”是一個競賽表演節目,從2002年到2005年在美國競賽表演廣播網(GameShowNetwork)放映。這是一個用真人進行的囚徒困境博弈例子,不過情景是人造的。這個競賽表演有三對人參與競爭。當每對人被淘汰時,他們做一個囚徒困境博弈,決定如何分他們的獎品。如果他們都合作(“朋友”),他們的獎品就被平分。如果一個合作而另一個背叛(“敵人”),背叛者得到所有的獎品,合作者什麼都得不到。如果都背叛,那么兩人都一無所獲。注意,這個支付矩陣與前述標準的支付矩陣不同,因為發生“都背叛”的情形和“我合作而對手背叛”的情形,其損失是一樣的。和標準囚徒困境的穩定均衡相比,“都背叛”是不穩固的均衡(weakequilibrium)。如果你知道你的對手將成為“敵人”,這時你的選擇無法影響你的獎品。在某種意義上,“是敵是友”擁有一個介於“囚徒困境”和“小雞”之間的支付模型。
這個支付矩陣是:
如果參與者都合作,每人得到+1。
如果都背叛,每人得到0。
如果甲合作而乙背叛,甲得到0而乙得到+2。
是敵是友對於想對囚徒困境作現實分析的人將是有用的。注意到,參與者只能進行一次,所以所有涉及重複進行博弈的觀點都不適用,“以牙還牙”策略也無法發展出來。
在是敵是友中,每個參賽者被允許做一個聲明,使另一半友在雙方秘密決定合作或背叛之前,確信他的友善。可能“打破制度”的方法將是一個參與者告訴他的對手:“我會選擇做敵人。如果你相信我後來會和你分獎品的話,就選擇做朋友。否則,如果你選擇做敵人,我們都回空手而回。”一個更貪婪的版本將是:“我將選擇做敵人。我會給你百分之X,剩下的百分之(100-X)歸我。所以,要或不要,要么我們都得到一些,要么我們都一無所獲。”(在最後通牒博弈中時。)現在,奸計就是去儘量減少那個百分之X,並保持另一個競爭者仍然選擇做朋友。基本上,這個參與者必須知道這個界限,在這裡他的對手從看到他一無所獲中得到的效用,要超過他從肯定能贏得的金錢中得到的效用,如果他順利的話。
在競賽中這個方法從未被試驗過;可能是因為裁判們不會允許,而且即使允許,不平等厭惡也會由於這個規則的使用而導致較低的期望收益。(最後通牒博弈中嘗試了這個方法,結果導致對高而不平等的出價的拒絕——在一些案例中,相當於兩周的工資優先於兩個參與者一無所獲被決絕。)
