
概述
任何單個應用程式都不能完全使該處理器達到滿負荷。當一個執行緒遇到較長等待時間事件時,同步多執行緒還允許另一執行緒中的指令使用所有執行單元。例如,當一個執行緒發生高速快取不命中,另一個執行緒可以繼續執行。同步多執行緒是 POWER5™ 和 POWER6™ 處理器的功能,可與共享處理器配合使用。
SMT 對於商業事務處理負載的性能最佳化可達30%。在更加注重系統的整體吞吐量而非單獨執行緒的吞吐量時,SMT 是一個很好地選擇。
但是並非所有的套用都能通過SMT 取得性能最佳化。那些性能受到執行單元限制的套用,或者那些耗盡所有處理器的記憶體頻寬的套用,其性能都不會通過在同一個處理器上執行兩個執行緒而得到提高。
儘管SMT 可以使系統識別到雙倍於物理CPU數量的邏輯CPU(lcpu),但是這並不意味著系統擁有了兩倍的CPU能力。
SMT技術允許核心在同一時間運行兩個不同的進程,以此來壓縮多任務處理時所需要的總時間。這么做有兩個好處,其一是提高處理器的計算性能,減少用戶得到結果所需的時間;其二就是更好的能效表現,利用更短的時間來完成任務,這就意味著在剩下的時間裡節約更多的電能消耗。當然這么做有一個總前提——保證SMT不會重複HT所犯的錯誤,而提供這個擔保的則是在酷睿微架構中表現非常出色的分支預測設計。
同步
事件
1、 Event
用事件(Event)來同步執行緒是最具彈性的了。一個事件有兩種狀態:激髮狀態和未激髮狀態。也稱有信號狀態和無信號狀態。事件又分兩種類型:手動重置事件和自動重置事件。手動重置事件被設定為激髮狀態後,會喚醒所有等待的執行緒,而且一直保持為激髮狀態,直到程式重新把它設定為未激髮狀態。自動重置事件被設定為激髮狀態後,會喚醒“一個”等待中的執行緒,然後自動恢復為未激髮狀態。所以用自動重置事件來同步兩個執行緒比較理想。MFC中對應的類為CEvent。CEvent的構造函式默認創建一個自動重置的事件,而且處於未激髮狀態。共有三個函式來改變事件的狀態:SetEvent,ResetEvent和PulseEvent。用事件來同步執行緒是一種比較理想的做法,但在實際的使用過程中要注意的是,對自動重置事件調用SetEvent和PulseEvent有可能會引起死鎖,必須小心。
多執行緒同步-event
在所有的核心對象中,事件核心對象是個最基本的。它包含一個使用計數(與所有核心對象一樣),一個BOOL值(用於指明該事件是個自動重置的事件還是一個人工重置的事件),還有一個BOOL值(用於指明該事件處於已通知狀態還是未通知狀態)。事件能夠通知一個執行緒的操作已經完成。有兩種類型的事件對象。一種是人工重置事件,另一種是自動重置事件。他們不同的地方在於:當人工重置的事件得到通知時,等待該事件的所有執行緒均變為可調度執行緒。當一個自動重置的事件得到通知時,等待該事件的執行緒中只有一個執行緒變為可調度執行緒。
當一個執行緒執行初始化操作,然後通知另一個執行緒執行剩餘的操作時,事件使用得最頻繁。在這種情況下,事件初始化為未通知狀態,然後,當該執行緒完成它的初始化操作後,它就將事件設定為已通知狀態,而一直在等待該事件的另一個執行緒在事件已經被通知後,就變成可調度執行緒。
當這個進程啟動時,它創建一個人工重置的未通知狀態的事件,並且將句柄保存在一個全局變數中。這使得該進程中的其他執行緒能夠非常容易地訪問同一個事件對象。程式一開始創建了三個執行緒,這些執行緒在初始化後就被掛起,等待事件。這些執行緒要等待檔案的內容讀入記憶體,然後每個執行緒都會訪問這段檔案內容。一個執行緒進行單詞計數,另一個執行緒運行拼寫檢查,第三個執行緒運行語法檢查。這3個執行緒函式的代碼的開始部分都相同,每個函式都調用WaitForSingleObject.,這將使執行緒暫停運行,直到檔案的內容由主執行緒讀入記憶體為止。一旦主執行緒將數據準備好,它就調用SetEvent,給事件發出通知信號。這時,系統就使所有這3個輔助執行緒進入可調度狀態,它們都獲得了C P U時間,並且可以訪問記憶體塊。這3個執行緒都必須以唯讀方式訪問記憶體,否則會出現記憶體錯誤。這就是所有3個執行緒能夠同時運行的唯一原因。如果計算機上配有三個以上CPU,理論上這個3個執行緒能夠真正地同時運行,從而可以在很短的時間內完成大量的操作
如果你使用自動重置的事件而不是人工重置的事件,那么應用程式的行為特性就有很大的差別。當主執行緒調用S e t E v e n t之後,系統只允許一個輔助執行緒變成可調度狀態。同樣,也無法保證系統將使哪個執行緒變為可調度狀態。其餘兩個輔助執行緒將繼續等待。已經變為可調度狀態的執行緒擁有對記憶體塊的獨占訪問權。
讓我們重新編寫執行緒的函式,使得每個函式在返回前調用S e t E v e n t函式(就像Wi n M a i n函式所做的那樣)。
當主執行緒將檔案內容讀入記憶體後,它就調用SetEvent函式,這樣作業系統就會使這三個在等待的執行緒中的一個成為可調度執行緒。我們不知道系統將首先選擇哪個執行緒作為可調度執行緒。當該執行緒完成操作時,它也將調用S e t E v e n t函式,使下一個被調度。這樣,三個執行緒會以先後順序執行,至於什麼順序,那是作業系統決定的。所以,就算每個輔助執行緒均以讀/寫方式訪問記憶體塊,也不會產生任何問題,這些執行緒將不再被要求將數據視為唯讀數據。
這個例子清楚地展示出使用人工重置事件與自動重置事件之間的差別。
P u l s e E v e n t函式使得事件變為已通知狀態,然後立即又變為未通知狀態,這就像在調用S e t E v e n t後又立即調用R e s e t E v e n t函式一樣。如果在人工重置的事件上調用P u l s e E v e n t函式,那么在發出該事件時,等待該事件的任何一個執行緒或所有執行緒將變為可調度執行緒。如果在自動重置事件上調用P u l s e E v e n t函式,那么只有一個等待該事件的執行緒變為可調度執行緒。如果在發出事件時沒有任何執行緒在等待該事件,那么將不起任何作用 。
臨界區
2、 Critical Section
使用臨界區域的第一個忠告就是不要長時間鎖住一份資源。這裡的長時間是相對的,視不同程式而定。對一些控制軟體來說,可能是數毫秒,但是對另外一些程式來說,可以長達數分鐘。但進入臨界區後必須儘快地離開,釋放資源。如果不釋放的話,會如何?答案是不會怎樣。如果是主執行緒(GUI執行緒)要進入一個沒有被釋放的臨界區,呵呵,程式就會掛了!臨界區域的一個缺點就是:Critical Section不是一個核心對象,無法獲知進入臨界區的執行緒是生是死,如果進入臨界區的執行緒掛了,沒有釋放臨界資源,系統無法獲知,而且沒有辦法釋放該臨界資源。這個缺點在互斥器(Mutex)中得到了彌補。Critical Section在MFC中的相應實現類是CcriticalSection。CcriticalSection::Lock()進入臨界區,CcriticalSection::UnLock()離開臨界區。
互斥器
3、 Mutex
互斥器的功能和臨界區域很相似。區別是:Mutex所花費的時間比Critical Section多的多,但是Mutex是核心對象(Event、Semaphore也是),可以跨進程使用,而且等待一個被鎖住的Mutex可以設定TIMEOUT,不會像Critical Section那樣無法得知臨界區域的情況,而一直死等。MFC中的對應類為CMutex。Win32函式有:創建互斥體CreateMutex() ,打開互斥體OpenMutex(),釋放互斥體ReleaseMutex()。Mutex的擁有權並非屬於那個產生它的執行緒,而是最後那個對此Mutex進行等待操作(WaitForSingleObject等等)並且尚未進行ReleaseMutex()操作的執行緒。執行緒擁有Mutex就好像進入Critical Section一樣,一次只能有一個執行緒擁有該Mutex。如果一個擁有Mutex的執行緒在返回之前沒有調用ReleaseMutex(),那么這個Mutex就被捨棄了,但是當其他執行緒等待(WaitForSingleObject等)這個Mutex時,仍能返回,並得到一個WAIT_ABANDONED_0返回值。能夠知道一個Mutex被捨棄是Mutex特有的。
信號量
4、 Semaphore
信號量是最具歷史的同步機制。信號量是解決producer/consumer問題的關鍵要素。對應的MFC類是Csemaphore。Win32函式CreateSemaphore()用來產生信號量。ReleaseSemaphore()用來解除鎖定。Semaphore的現值代表的意義是可用的資源數,如果Semaphore的現值為1,表示還有一個鎖定動作可以成功。如果現值為5,就表示還有五個鎖定動作可以成功。當調用Wait…等函式要求鎖定,如果Semaphore現值不為0,Wait…馬上返回,資源數減1。當調用ReleaseSemaphore()資源數加1,當然不會超過初始設定的資源總數。
技術問題
1、 何時使用多執行緒?
2、 執行緒如何同步?
3、 執行緒之間如何通訊?
4、 進程之間如何通訊?
先來回答第一個問題,執行緒實際主要套用於四個主要領域,當然各個領域之間不是絕對孤立的,他們有可能是重疊的,但是每個程式應該都可以歸於某個領域:
1、 offloading time-consuming task。由輔助執行緒來執行耗時計算,而使GUI有更好的反應。我想這應該是我們考慮使用執行緒最多的一種情況吧。
2、 Scalability。伺服器軟體最常考慮的問題,在程式中產生多個執行緒,每個執行緒做一份小的工作,使每個CPU都忙碌,使CPU(一般是多個)有最佳的使用率,達到負載的均衡,這比較複雜,我想以後再討論這個問題。
3、 Fair-share resource allocation。當你向一個負荷沉重的伺服器發出請求,多少時間才能獲得服務。一個伺服器不能同時為太多的請求服務,必須有一個請求的最大個數,而且有時候對某些請求要優先處理,這是執行緒優先權乾的活了。
4、 Simulations。執行緒用於仿真測試。
執行緒通訊
執行緒常常要將數據傳遞給另外一個執行緒。Worker執行緒可能需要告訴別人說它的工作完成了,GUI執行緒則可能需要交給Worker執行緒一件新的工作。
通過PostThreadMessage(),可以將訊息傳遞給目標執行緒,當然目標執行緒必須有訊息佇列。以訊息當作通訊方式,比起標準技術如使用全局變數等,有很大的好處。如果對象是同一進程中的執行緒,可以傳送自定義訊息,傳遞數據給目標執行緒,如果是執行緒在不同的進程中,就涉及進程之間的通訊了。下面將會講到。
進程之間的通訊:
當執行緒分屬於不同進程,也就是分駐在不同的地址空間時,它們之間的通訊需要跨越地址空間的邊界,便得採取一些與同一進程中不同執行緒間通訊不同的方法。
1、 Windows專門定義了一個訊息:WM_COPYDATA,用來線上程之間搬移數據,――不管兩個執行緒是否同屬於一個進程。同時接受這個訊息的執行緒必須有一個視窗,即必須是UI執行緒。WM_COPYDATA必須由SendMessage()來傳送,不能由PostMessage()等來傳送,這是由待傳送數據緩衝區的生命期決定的,出於安全的需要。
2、 WM_COPYDATA效率上面不是太高,如果要求高效率,可以考慮使用共享記憶體(Shared Memory)。使用共享記憶體要做的是:設定一塊記憶體共享區域;使用共享記憶體;同步處理共享記憶體。
第一步:設定一塊記憶體共享區域。首先,CreateFileMapping()產生一個file-mapping核心對象,並指定共享區域的大小。MapViewOfFile()獲得一個指針指向可用的記憶體。如果是C/S模式,由Server端來產生file-mapping,那么Client端使用OpenFileMapping(),然後調用MapViewOfFile()。
第二步:使用共享記憶體。共享記憶體指針的使用是一件比較麻煩的事,我們需要藉助_based屬性,允許指針被定義為從某一點開始起算的32位偏移值。
第三步:清理。UnmapViewOfFile()交出由MapViewOfFile()獲得的指針,CloseHandle()交出file-mapping核心對象的handle。
第四步:同步處理。可以藉助Mutex來進行同步處理。
3、 IPC
1)Anonymous Pipes。Anonymous Pipes只被使用於點對點通訊。當一個進程產生另一個進程時,這是最有用的一種通訊方式。
2)Named Pipes。Named Pipes可以是單向,也可以是雙向,並且可以跨越網路,步局限於單機。
3)Mailslots。Mailslots為廣播式通訊。Server進程可以產生Mailslots,任何Client進程可以寫數據進去,但是只有Server進程可以取數據。
4)OLE Automation。OLE Automation和UDP都是更高階的機制,允許通訊發生於不同進程間,甚至不同機器間。
5)DDE。DDE動態數據交換,使用於16位Windows,這一方式應儘量避免使用。
工作方式
圖中首先顯示了單執行緒方式,其中所有物理資源都通過單個執行緒。POWER™ 系統支持單執行緒和同步多執行緒。
隨後,圖中顯示了粗粒度多執行緒方式,其中每次只有一個執行緒運行。當執行緒遇到長等待時間事件(如高速快取不命中)時,硬體切換到第二個執行緒以使用處理資源,而不是讓伺服器保持空閒狀態。此設計允許其他任務使用原本將空閒的處理器周期,從而提高了總系統吞吐量。為了節約資源,兩個執行緒共享許多系統資源,如結構暫存器。因此,將程式控制從一個執行緒切換到另一個執行緒需要數個周期。
最後,圖中顯示了同步多執行緒方式,其中處理器同時從多個硬體執行緒檢索指令。處理器將多個硬體執行緒中的指令調度為同時執行。藉助同步多執行緒,系統將根據環境進行動態調節,從而允許在可能的情況下執行每個硬體執行緒中的指令;當一個硬體執行緒遇到長等待時間事件時,它還允許另一個硬體執行緒中的指令使用所有執行單元。
同步多執行緒主要在以下上下文中有用:
在單個速度不如所執行的總數重要的商用環境中。同步多執行緒將通過大型或經常變化的(如Web 伺服器)增加工作負載的吞吐量。
SMT
內容提要Power5 晶片是IBM Power 晶片家族中的新一代高端CPU 產品,它與Power4 在二進制上兼容,但在性能和功能上比Power4 有很大的增強。本文將介紹Power5 所支持的同步多執行緒技術Simultaneous MultiThreading 。
套用
在單個速度不如所執行的總數重要的商用環境中。同步多執行緒將通過大型或經常變化的工作集(如資料庫伺服器和 Web 伺服器)增加工作負載的吞吐量。 具有高 CPI 計數的工作負載。這些工作負載往往很少使用處理器和記憶體資源。高 CPI 計數通常由大型工作機的高速快取不命中率較高而導致。較大的商用工作負載在某些程度上取決於兩個硬體執行緒是否共享指令或數據,或取決於兩個硬體執行緒是否完全不同。共享指令或數據的工作負載可能從同步多執行緒中獲得較大的好處,這些指令或數據可包括在作業系統中或單個應用程式中廣泛運行的指令或數據。
說明
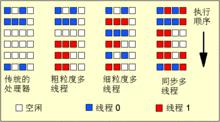 同步多執行緒示意圖
同步多執行緒示意圖傳統的CPU 在某一時間只能處理一個指令序列,通常我們把它稱為一個執行緒。線上程處理的過程中CPU 的處理單元需要不斷調入指令與數據進行處理。隨著CPU 技術的發展,CPU 的主頻與性能不斷提高,需要調入指令和數據的速度不斷提高。但不幸的是記憶體技術的發展並沒有跟上CPU 發展的速度,記憶體通常無法提供足夠的指令和數據給CPU 進行處理。
為了解決這個問題,業界通常採用多級快取的方式。CPU 處理單元中的暫存器是最快的,通常一個CPU 中有一、兩百個暫存器,它可以在一個時鐘周期內提供指令和數據。其次是一級快取,他的大小通常為幾十KB ,它需要幾個時鐘周期的訪問時間。再下面是二級快取,他的大小通常為幾MB ,它需要十幾個時鐘周期的訪問時間。然後是記憶體,從記憶體中取得數據需要幾十個個時鐘周期。而最慢的是硬碟,通常需要幾千甚至幾萬個時鐘周期的訪問時間。
當CPU 需要處理下一條指令時,他通常按照暫存器、一級快取、二級快取、記憶體、硬碟這一順序去查找。但如果在記憶體中仍然找不到需要的指令或數據時。系統會進行Context Switch ,終止此執行緒在CPU 上的運行,使其處於等待狀態,而讓其他的執行緒運行,當此執行緒需要的數據被調入記憶體後,此執行緒處於就緒狀態,可以被調度到CPU 上運行。執行緒間的Context Switch 需要幾十個時鐘周期。
由此可見當CPU 需要從記憶體中取數據時,處理單元需要空轉幾十個時鐘周期,有關統計顯示當前CPU 處理單元的平均利用率不足25% 。為了提高CPU 處理單元的利用率,設計者採用了執行緒級的並行技術,即在CPU 的核心中執行一個以上的指令序列。對於作業系統來說,一個物理的處理器相當於兩個邏輯的處理器,當前有三種不同的方式,實現多執行緒技術。
粗粒度的多執行緒,在任一時刻只有一個執行緒執行,當執行緒遇到一個長延遲事件時,如二級快取不命中,則系統調度另一個執行緒執行,而不是讓系統資源空轉等待此執行緒。這一機制可以提高整個系統的利用率。這兩個執行緒共享許多系統資源,如CPU 的暫存器和快取等,因此這兩個執行緒的切換比Context Switch 要快得多,只需要幾個時鐘周期。IBM 在使用PowerPC RS64 IV 處理器的pSeries 680 和pSeries 660-6M1 上使用過這種粗粒度的多執行緒技術。
另一種與粗粒度的多執行緒技術相對的是細粒度多執行緒技術,採用這種多執行緒的系統循環的執行兩個執行緒的指令,這就需要在處理器的設計上增加許多冗餘的部件。如果一個執行緒遇到個長延遲事件時,對應這一執行緒執行的時鐘周期仍然沒有被利用。
第三種多執行緒技術是同步多執行緒技術(SMT) ,與其他的多執行緒技術一樣,同步多執行緒能夠從多個執行緒中取出指令來運行,它能夠同時執行不同執行緒的指令。通過同步多執行緒技術,系統能夠動態調整系統環境,如有可能同時執行不同執行緒的指令。當一個執行緒遇到長延遲事件時,允許另一個執行緒使用所用的處理單元。
Power5 處理器的設計採用兩路的同步多執行緒設計,雖然更多路的同步多執行緒也是可能的,但模擬現實,其所增加的系統的複雜性是不經濟的。另外一個需要注意的問題是,同步多執行緒技術可能會由於快取爭用而降低整個系統的性能。
微軟技術
基於NetBurst架構的超執行緒:OOOE + SMT
基於Itanium架構的超執行緒:IOE + CMT
基於Atom架構的超執行緒:IOE + SMT
基於Nehalem架構的超執行緒:OOOE + SMT
同步多執行緒
SMT(Simultaneous Multi-Threading,同步多執行緒)實乃是一個專有名詞,是一種類技術的名稱,不僅僅Nehalem有採用,Pentium 4也有採用,還有很多其他商用處理器也有採用。正確的情況應該是,Nehalem的HT技術和Pentium 4的HT技術一樣,都是屬於SMT技術。
實際上,超執行緒技術在Intel的很多處理器裡面都有使用,除了Pentium 4(NetBurst架構)、Core i7(Nehalem架構)之外,Itanium 2(Mondecito)和Atom(Silverthorne)處理器裡面都有,然而它們攜帶的HT技術卻不屬於SMT!
在整理Intel的多種HT超執行緒技術之前,我們先來回顧一下MultiThreading多執行緒技術的分類,MultiThreading多執行緒就是在一個單個的處理核心內同時運行多個工作執行緒的技術,和CMP(Chip MultiProcessing,晶片多處理)不同,後者是通過集成多個處理核心的方式來讓系統的處理能力提升——也就是現在常見的多核技術。主流的處理器都使用了CMP技術。
 多執行緒架構異同
多執行緒架構異同然而CMP技術大規模增加了相應的電路,從而增加了成本,MT(MultiThreading)技術卻不是這樣,它只需要增加規模很少的部分線路(通常,約2%)就可以提升處理器的總體處理器能力,從而可以很簡單地提升相關套用的性能。
MultiThreading(或作Multi-Threading)來源於可以追溯到上個世紀90年代開始的一個叫做ILP(Instruction Level Parallelism,指令級並行化)的思想,這個思想產生了一個叫做Throughput Computing(吞吐量計算)的名詞,用來提升如線上交易這樣的並行計算的性能。Throughput Computing的兩種主要方式就是MultiProcessing和MultiThreading。
一開始,為了開發ILP,在過去的幾十年中利用了超標量(Superscalar,同時具備多個執行器)、亂序執行(Out-Of-Order Execute,允許無數據關聯性的指令同時運行)、動態分支預測、VLIW(Very Long Instruction Word,超長指令集) 等技術(前三種可在經典的Pentium Pro架構上看到,最後一個就是Itanium的特色技術)。然而,超標量使設計的複雜性急劇增加,同時,指令之間的數據和控制相關,可以開發的ILP 也有限,以及一些其它因素,使得經典的超標量結構處理器難以進一步提高處理器性能。
而且從套用的角度看,如線上事務處理OLTP、決策支持系統DSS、Web服務等這樣的套用的特點是具有豐富的執行緒級並行性(Thread Level Parallelism)而缺乏ILP,因此也就促使了MultiProcessing和MultiThreading的出現。
MultiThreading多執行緒技術的思想有些類似於早期的分時共享計算系統,執行多個執行緒的處理器在遇到某個執行緒由於Cache Miss或者分支預測失敗而停頓的時候,可以切換到另一個執行緒來執行。主流的MultiThreading具有著三種形式,差別在於執行緒間共享的資源以及執行緒切換的機制:
其中CMT和FMT都是在單個執行單元下的技術,不同的執行緒在指令級別上並不是真正的“並行”,而SMT則具有多個執行單元,同一時間內可以同時執行多個指令,因此前兩者有時先歸類為TMT(Temporal MultiThreading,時間多執行緒),以和SMT相區分。
首先介紹CMT——Coarse-Grained MultiThreading是因為:它是最簡單的多執行緒技術,當單一執行執行緒遇到長時間的延遲,如Cache Missed時,就進行執行緒切換,直到原執行緒等待的操作完成,才切換回去。Coarse-Grained MultiThreading有時也叫Block MultiThreading堵塞多執行緒或者Cooperative MultiThreading協作多執行緒。
由於CMT很簡單,因此很多處理器都有實現,除了下面列出之外,很多嵌入式微控制器都有實現:
1999年的IBM RS64 III「Pulsar」(單核心/雙執行緒)
2005年Fujitsu SPARC64 VI「Olympus-C」(雙核心/4執行緒)
2006年Intel Itanium 2「Montecito」(雙核心/4執行緒)
2007年Intel Itanium 2「Montvale」(雙核心/4執行緒)
Intel的Itanium 2赫然在目
交錯多執行緒
FMT——Fine-Grained MultiThreading隨時可以在每個時鐘周期內切換多個執行緒,以追求最大的輸出能力——當然,隨時可以切換也是有代價的,它拉長了每個執行執行緒的平均執行時間。Fine-Grained MultiThreading有時也叫Interleaved MultiThreading交錯多執行緒或者Pre-emptive MultiThreading搶先多執行緒。
和CMT比起來,FMT要複雜一些,因此相應的處理器就沒有那么多,例:
2005年Sun UltraSPARC T1「Niagara」(8核心/32執行緒)
2007年Sun UltraSPARC T2「Niagara 2」(8核心/64執行緒)
 最典型的:Intel Pentium 4或者Core i7
最典型的:Intel Pentium 4或者Core i7其實UltraSPARC T2同時還使用了其他的MT技術,才實現了比T1多了一倍的多執行緒能力,仔細看看上圖,T2還使用了什麼MT技術(注意第一段的CMT是Chip MultiThreading的意思而不是Coarse-Grained MultiThreading的意思)?
雖然CPU上使用FMT技術的並不 早在NV G40以及ATI R520開始,GPU內部就開始套用了FMT細粒度多執行緒技術,為了隱含Cache Miss的存儲器高延遲,GPU內部的執行單元不停的在工作執行緒之間切換,提升總的處理能力。不過,G40的FMT實現了具體多少個執行緒筆者倒不是很清楚,根據資料看應該在100左右。
前面說過,SMT其實和其他兩種多執行緒技術都不同——那兩種技術被稱之為TMT時間多執行緒。SMT——Simultaneous MultiThreading具有多個執行單元,可以同時運行多條指令,因此才叫做“同步多執行緒”!SMT起先源自充分挖掘超標量架構處理器的潛力——超標量的意思就是可以同時執行多個不同的指令。因此SMT具有最大的靈活性和資源利用率,然而實現也最複雜(當然比起多核結構來說就是小意思了)。
2002年Intel Pentium 4 Xeon「Prestonia」(單核心/雙執行緒)
2007年Sun UltraSPARC T2「Niagara 2」(8核心/64執行緒)
2008年Intel Core i7「Nehalem」(4核心/8執行緒)
這裡又看到了UltraSPARC T2,這是因為它同時採用了FMT和SMT技術:因為UltraSPARC T2具有兩個執行單元,每一個執行緒組使用一個,執行緒組內則按照T1那樣執行4個執行緒。現代的GPU也採用了類似的混合設計:
不同的流處理器可以同時執行不同的執行緒,當然同一個流處理器也可以在不同的執行緒之間切換。
超執行緒技術
介紹了所有的MT多執行緒技術種類之後,我們可以來看Intel的HyperThreading超執行緒技術了,前面說過,Intel具有超執行緒技術的CPU有:Pentium 4(NetBurst架構)、Core i7(Nehalem架構)、Itanium 2(Mondecito)、Atom(Silverthorne)。我們已經知道具有超執行緒技術的Pentium 4/Pentium 4 Xeon(不是所有的P4都有超執行緒技術)採用的是SMT架構,Core i7的則是其改進版本。我們再來看看Itanium 2:Itanium 2 Montecito採用了雙核心設計,每核心兩個執行緒;Itanium 2 Montecito的超執行緒技術採用了CMT架構; 可見,Itanium 2的超執行緒技術和Pentium 4的SMT不同,它實際上是CMT粗粒度多執行緒技術。這是因為Itanium 2是In-Order架構的,SMT的原始構想就是充分壓榨OOOE(Out-Of-Order Execution)的能力,因此In-Order架構的Itanium 2就沒有採用SMT的方式。因為要創建多個執行緒的代價太大。
那是否In-Order架構的處理器就不能實現SMT了呢?並不是,Intel的Atom就是一個典型的例子: 除了Atom之外,IBM的怪物Power6(起始頻率4.7GHz)也採用了基於In-Order架構的SMT技術(Power5的SMT是基於Out-Of-Order):IBM Power6處理器,雙核,每核兩個執行緒;Power6:In-Order + SMT,Power5則是Out-Of-Order + SMT。
超執行緒
在NetBurst微架構後期,Intel為了維持性能上的優勢,將Prescott核心的Pentium 4流水線拉長到31級;細化後的流水線可以被分成若干個環節,然後執行不同的任務進程,Intel將其稱為“Hyper-Threading Technology(超執行緒技術,簡稱HT)”。但過長的流水線需要進行大量的分支預測工作,而且一旦預測失準,就要把當前的工作全部推倒重新來過。這就造成了Pentium 4 HT處理器空有高頻率,發熱量也大得驚人,性能卻提高有限,最終還被扣上了“高頻低能”的大帽子。
從原則上來講HT技術絕對是一項非常有意義的創新和嘗試,如果我們假設當初HT遇到的不是流水線冗長Prescott Pentium 4,而是更加精簡高效的Core 2Duo,結果會怎樣?
當然,只有14級流水線的Core 2 Duo最終還是與HT擦肩而過(當初的理由是過短的流水線沒必要引入超執行緒技
術);但這並不代表Intel放棄了這方面的努力,Nehalem就在嘗試做這樣的事情。所不同的是,這次的主角有了一個新名字——Simultaneous Multi-Threading( 同步多執行緒,簡稱SMT)。
