
概念
按一定的機率或可信度(1-α)用一個區間來估計總體參數所在的範圍,該範圍通常稱為參數的可信區間或者置信區間(confidenceinterval,CI),預先給定的機率(1-α)稱為可信度或者置信度(confidencelevel),常取95%或99%.
可信區間(CL,CU)是一開區間CL,CU稱為可信限
均數的(1-α)100%可信區間
-t/2,v0t/2,v
1-
/2
/2
均數的95%可信區間
樣本含量不是很大時,
樣本含量較大時,t分布逼近u分布
如抽樣通過檢查110個健康成人的尿紫質算得陽性率為10%,這是樣本率,可用它來估計總體率,說明健康成人的尿紫質陽性率水平,這樣的估計叫“點估計”。但由於存在抽樣誤差,不同樣本(如再檢查110人)可能得到不同的估計值。因此我們常用“區間估計”總體率(或總體均數)大概在那一個範圍內,這個範圍就叫可信區間。區間小的一端叫下限,大的一端叫上限。常用的有95%可信區間與99%可信區間。根據同一資料所作95%可信區間比99%可信區間窄些(上、下限較靠近),但估計錯誤的機率後者為1%,前者為5%,進行總體參數的區間估計時可根據研究目的與標準誤的大小選用95%、或99%。
區別
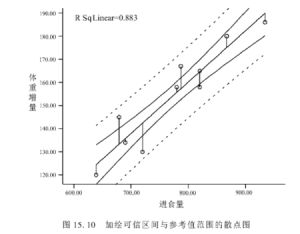 參考範圍的散點圖
參考範圍的散點圖1.從意義來看
95%參考值範圍是指同質總體內包括95%個體值的估計範圍,而總體均數95%可信區間是指按95%可信度估計的總體均數的所在範圍。
2.從計算公式看
若指標服從常態分配,95%參考值範圍的公式是:±1.96s。
總體均數95%可信區間的公式是:。
