![lex[工具]](/img/4/2c4/nBnauM3XzIzM3EzNwUDMwkjM0UTMxMTNwgTMxADMwAzMwIzL1AzLygzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "lex[工具]")
生成工具
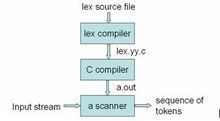 lex
lex 它被設計用來對輸入字元流進行詞法處理。它接受一種高級的、面向問題的說明書,並用它匹配字元串中的字元、生成能夠識別正則表達式的程式。正則表達式通過用戶輸入的代碼說明書給入。Lex識別這些表達式,並且將輸入流分成一些匹配這些表達式的字元串。在這些字元串的分界處,用戶提供的程式片段被執行。Lex代碼檔案將正則表達式和程式片斷關聯。對每一條輸入到由Lex生成程式的表達式,相應的代碼片段被執行。
為了完成任務,除了需要提供匹配的表達式以外,用戶還需要提供其它代碼,甚至是由其他生成器產生的代碼。用戶提供一般程式設計語言的代碼片斷完成程式識別表達式。因此,用戶自由編寫動作時,並不影響其編寫高層的表達式語言來匹配字元串表達式。這就避免迫使用戶使用字元串語言來進行輸入分析時,也必須使用同樣的方法來編寫字元處理程式,而這樣做有時是不合適的。Lex不是完整的語言,但是是一個新語言的生成器,它可以插入到各種不同的被叫做“宿主語言”的程式設計語言中。就像大多數目的語言可以生成在不同計算機硬體上運行的代碼,Lex可以生成不同的宿主語言。宿主語言用於Lex生成輸出代碼,也用於用戶插入程式片斷。這使得Lex適用於不同的環境和不同的使用者。每一個應用程式可以是硬體、適用於該任務的宿主語言、用戶背景和局部接口屬性的直接結合。現在,Lex唯一支持的宿主語言是C,儘管Fortran(形式為Ratfor[2])在過去也被支持。Lex自身存在於UNIX、GCOS和OS/370上;但是Lex生成的代碼可以在任何適當的編譯器上使用。
Lex將用戶輸入的表達式和動作actions(在這篇文章中被稱作原始碼)轉換為宿主語言;生成的程式叫做yylex。yylex識別字元流中的表達式(本文稱作輸入流),並且當每一個表達式被檢測出來後,輸出相應的動作。
讓我們來仔細研究一下這個奇妙的工具吧。先看看Lex檔案的結構。 Lex檔案結構簡單,分為三個部分:
declarations
%%
translationrules
%%
auxiliaryprocedures
分別是聲明,轉換規則和其它函式。
聲明段包括變數的聲明、符號常量的聲明和正則表達式聲明。希望出現在目標C源碼中的代碼,用%{…%}擴在一起。比如:
%{
#include
#include "y.tab.h"
typedefchar * YYSTYPE;
char* yylval;
%}
正則表達式聲明如下
/* regular definitions */
delim[ \t\n]ws +letter [A-Za-z]digit [0-9]id ()*number +(\.+)?(E[+\-]?+}?
這段正則表達式描述識別數(number)、標識符(id)的“規則”。過一會我們再細說正則表達式。
規則段是由正則表達式和相應的動作組成的。
p1p2 …… pn
值得注意的是,lex 依次嘗試每一個規則,儘可能地匹配最長的輸入流。如果有一些內容根本不匹配任何規則,那么 lex 將只是把它拷貝到標準輸出。比如
%%A {printf("you");}AA {printf("love ");}AAAA {printf("I ");}%%
編譯後運行一下,
$ ./sample3AAAAAAAI love you
可以看出lex的確按照最長的規則匹配。
程式段部分放一些掃描器的其它模組,比如一些動作執行時需要的模組。也可以在另一個程式檔案中編寫,最後再連結到一起。 生成C代碼後,需用C的編譯器編譯。連線時需要指定程式庫。gcc的連線參數為 -ll。
正則表達式可以描述有窮狀態自動機(finite automata)接受的語言,也就是定義一個可以接受的串的集.lex中用到的正則表達式的一些規則如下:
轉義字元(也稱操作符):
" \ [ ] ^ - ? . * + | ( ) $ / { } %
這些符號有特殊含義,不能用來匹配自身。如果需要匹配的話,可以通過引號(")或者轉義符號(\)來指示。比如
C"+" C\+\+
都可以匹配C++。
非轉義字元:所有除了轉義字元之外的字元都是非轉義字元。一個非轉義字元可以匹配自身。比如
integer
匹配文本中出現的integer。
通配符:通配符就是.(dot),可以匹配任何一個字元。
字元集:用一對[]指定的字元構成一個字元集。比如[abc]表示一個字元集,可以匹配a、b、c中的任意一個字元。使用 – 可以指定範圍。比如[a-z]表示可以匹配所有小寫字母的字元集。
重複:
* 任意次重複+ 至少一次的重複,相當於xx*? 零次或者一次
選擇和分組:|符號表示選擇,二者則一;括弧表示分組,括弧內的組合被看作是一個原子。比如(ab|cd)匹配ab或者cd。
原始碼
一般的Lex原始碼格式為
{definitions}
%%
{rules}
%%
{user subroutines}
而definitions和user subroutines經常被忽略。第二個%%是可選擇的,但是第一個必須存在以標記rules的開始。因此最簡單的Lex程式是
%%
(沒有definitions和rules),這個程式輸入將不加修改地複製到輸出。
由上面的Lex程式輪廓可知,規則(rules)反映了用戶的控制;它是一個表格,左側是正則表達式(regular expressions)(參見第3節),而右側是動作(actions),當表達式被識別出以後,動作的程式片斷被執行。所以,一個單獨的規則可能是
| integer | printf("found keyword INT"); |
它用於在輸入流中尋找字元串中的integer,找到後輸出“found keyword INT”。在這個例子中,主程式為C語言並且用C庫函式printf列印字元串。用第一個出現的空白符或者制表符作為表達式的結束標記。如果action僅僅是一條簡單的C表達式,那么它可以直接寫在這一行的右側;如果是複合表達式或者包含了很多行,則必須用大括弧括起來。作為一個更有用的例子——用來將一些英式拼寫轉換為美式拼寫——其詞法分析器應該以如下規則開始:
| colour | printf("color"); |
| mechanise | printf("mechanize"); |
| petrol | printf("gas"); |
這些規則是不夠強大的,比如pertroleum應該變為gaseum;一種處理它的方法將在下文中予以介紹。
警告和缺陷
有一些病態的表達式會使由表格轉化的確定的自動機成指數增長;幸運的是,這樣的情況很少見。
REJECT沒有重複掃描輸入;而是記住先前掃描的結果。這意味著如果一條規則需要回退發現的上下文,並且REJECT被執行了,用戶將不能使用unput來改變輸入流中的後續字元。這是對用戶操作後續輸入的唯一限制。
