
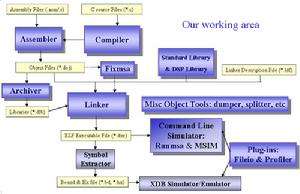
 編譯器
編譯器基本概述
原始碼(sourcecode)→預處理器(preprocessor)→編譯器(compiler)→彙編程式(assembler)→目標代碼(objectcode)→連線器(Linker)→可執行程式(executables)
編譯語言與解釋語言對比:
許多人將高級程式語言分為兩類:編譯型語言和解釋型語言。然而,實際上,這些語言中的大多數既可用編譯型實現也可用解釋型實現,分類實際上反映的是那種語言常見的實現方式。(但是,某些解釋型語言,很難用編譯型實現。比如那些允許線上代碼更改的解釋型語言。)
編譯器是一種特殊的程式,它可以把以特定程式語言寫成的程式變為機器可以運行的機器碼。把一個程式寫好,這時利用的環境是文本編輯器。這時我程式把程式稱為源程式。在此以後程式設計師可以運行相應的編譯器,通過指定需要編譯的檔案的名稱就可以把相應的源檔案(通過一個複雜的過程)轉化為機器碼了。
工作原理
 編譯器
編譯器典型的編譯器輸出是由包含入口點的名字和地址以及外部調用(到不在這個目標檔案中的函式調用)的機器代碼所組成的目標檔案。一組目標檔案,不必是同一編譯器產生,但使用的編譯器必需採用同樣的輸出格式,可以連結在一起並生成可以由用戶直接執行的可執行程式。
種類概述
 編譯器
編譯器預處理器:預處理器(preprocessor)作用是通過代入預定義等程式段將源程式補充完整。
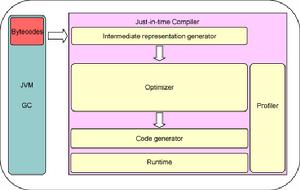
編譯器前端:編譯器前端(frontend),前端主要負責解析(parse)輸入的源程式,由詞法分析器和語法分析器協同工作。詞法分析器負責把源程式中的‘單詞’(Token)找出來,語法分析器把這些分散的單詞按預先定義好的語法組裝成有意義的表達式,語句 ,函式等等。 例如“a = b + c;”前端詞法分析器看到的是“a = b; + c;”,語法分析器按定義的語法,先把他們組裝成表達式“b + c”,再組裝成“a = b + c”的語句。 前端還負責語義(semantic checking)的檢查,例如檢測參與運算的變數是否是同一類型的,簡單的錯誤處理。最終的結果常常是一個抽象的語法樹(abstract syntax tree,或 AST),這樣後端可以在此基礎上進一步最佳化,處理。
編譯器後端:編譯器後端(backend)編譯器後端主要負責分析,最佳化中間代碼(Intermediate representation)以及生成機器代碼(Code Generation)。
編譯器分析,最佳化,變型都可以分成兩大類: 函式內(intraprocedural)還是函式之間(interprocedural)進行。很明顯,函式間的分析,最佳化更準確,但需要更長的時間來完成。對於函式內的最佳化,有可以根據最佳化施加的範圍分為,全局的(global)和局部的(local)。其中全局的最佳化是指該最佳化需要使用到全局的數據流和控制流信息。而局部的最佳化是指指導最佳化的信息來自基本快。
代碼分析
 編譯器
編譯器常見的編譯分析有函式調用樹(call tree),控制流程圖(Control flow graph),以及在此基礎上的 變數定義-使用,使用-定義鏈(define-use/use-define or u-d/d-u chain),變數別名分析(alias analysis),指針分析(pointer analysis),數據依賴分析(data dependence analysis)等。
程式分析結果是編譯器最佳化(compiler optimization)和程式變形(compiler transformation)的前提條件。常見的最佳化和變新有:函式內嵌(inlining),無用代碼刪除(Dead code elimination),標準化循環結構(loop normalization),循環體展開(loop unrolling),循環體合併,分裂(loop fusion,loop fission),數組填充(array padding),等等。 最佳化和變形的目的是減少代碼的長度,提高記憶體(memory),快取(cache)的使用率,減少讀寫磁碟,訪問網路數據的頻率。更高級的最佳化甚至可以把序列化的代碼(serial code)變成並行運算,多執行緒的代碼(parallelized,multi-threaded code)。
機器代碼的生成是最佳化變型後的中間代碼轉換成機器指令的過程。現代編譯器主要採用生成彙編代碼(assembly code)的策略,而不直接生成二進制的目標代碼(binary object code)。即使在代碼生成階段,高級編譯器仍然要做很多分析,最佳化,變形的工作。例如如何分配暫存器(register allocatioin),如何選擇合適的機器指令(instruction selection),如何合併幾句代碼成一句等等。
歷史回溯
 編譯器
編譯器有限狀態自動機(Finite Automaton)和正則表達式(Regular Expression)同上下文無關文法緊密相關,它們與Chomsky的3型文法相對應。對它們的研究與Chomsky的研究幾乎同時開始,並且引出了表示程式設計語言的單詞的符號方式。
人們接著又深化了生成有效目標代碼的方法,這就是最初的編譯器,它們被一直使用至今。人們通常將其稱為最佳化技術(Optimization Technique),但因其從未真正地得到過被最佳化了的目標代碼而僅僅改進了它的有效性,因此實際上應稱作代碼改進技術(Code Improvement Technique)。
當分析問題變得好懂起來時,人們就在開發程式上花費了很大的功夫來研究這一部分的編譯器自動構造。這些程式最初被稱為編譯器的編譯器(Compiler-compiler),但更確切地應稱為分析程式生成器(Parser Generator),這是因為它們僅僅能夠自動處理編譯的一部分。這些程式中最著名的是Yacc(Yet Another Compiler-compiler),它是由Steve Johnson在1975年為Unix系統編寫的。類似的,有限狀態自動機的研究也發展了一種稱為掃描程式生成器(Scanner Generator)的工具,Lex(與Yacc同時,由Mike Lesk為Unix系統開發)是這其中的佼佼者。
在70年代後期和80年代早期,大量的項目都貫注於編譯器其它部分的生成自動化,這其中就包括了代碼生成。這些嘗試並未取得多少成功,這大概是因為操作太複雜而人們又對其不甚了解。
編譯器設計發展包括:首先,編譯器包括了更加複雜算法的應用程式它用於推斷或簡化程式中的信息;這又與更為複雜的程式設計語言的發展結合在一起。其中典型的有用於函式語言編譯的Hindley-Milner類型檢查的統一算法。其次,編譯器已越來越成為基於視窗的互動開發環境(Interactive Development Environment,IDE)的一部分,它包括了編輯器、連線程式、調試程式以及項目管理程式。這樣的IDE標準並沒有多少,但是對標準的視窗環境進行開發已成為方向。另一方面,儘管近年來在編譯原理領域進行了大量的研究,但是基本的編譯器設計原理在近20年中都沒有多大的改變,它現在正迅速地成為計算機科學課程中的中心環節。
在90年代,作為GNU項目或其它開放原始碼項目的一部分,許多免費編譯器和編譯器開發工具被開發出來。這些工具可用來編譯所有的電腦程式語言。它們中的一些項目被認為是高質量的,而且對現代編譯理論感性趣的人可以很容易的得到它們的免費原始碼。
大約在1999年,SGI公布了他們的一個工業化的並行化最佳化編譯器Pro64的原始碼,後被全世界多個編譯器研究小組用來做研究平台,並命名為Open64。Open64的設計結構好,分析最佳化全面,是編譯器高級研究的理想平台。
工作方法
 編譯器
編譯器然後進行語義分析,就是把各個由語法分析分析出的語法單元的意義搞清楚。
最後生成的是目標檔案,也稱為obj檔案。
再經過連結器的連結就可以生成最後的可執行代碼了。
有些時候需要把多個檔案產生的目標檔案進行連結,產生最後的代碼。這一過程稱為交叉連結。
