
定義
文檔對象模型(Document Object Model,簡稱DOM),是W3C組織推薦的處理可擴展置標語言的標準編程接口。它是一種與平台和語言無關的應用程式接口(API),它可以動態地訪問程式和腳本,更新其內容、結構和www文檔的風格(目前,HTMl和XML文檔是通過說明部分定義的)。文檔可以進一步被處理,處理的結果可以加入到當前的頁面。DOM是一種基於樹的API文檔,它要求在處理過程中整個文檔都表示在存儲器中。另外一種簡單的API是基於事件的SAX,它可以用於處理很大的XML文檔,由於大,所以不適合全部放在存儲器中處理。
模型及擴展
文檔對象模型DOM
DOM即文檔對象模型,是W3C制定的標準接口規範,是一種處理HTML和XML檔案的標準API。DOM提供了對整個文檔的訪問模型,將文檔作為一個樹形結構,樹的每個結點表示了一個HTML標籤或標籤內的文本項。DOM樹結構精確地描述了HTML文檔中標籤間的相互關聯性。將HTML或XML文檔轉化為DOM樹的過程稱為解析(parse)。HTML文檔被解析後,轉化為DOM樹,因此對HTML文檔的處理可以通過對DOM樹的操作實現。DOM模型不僅描述了文檔的結構,還定義了結點對象的行為,利用對象的方法和屬性,可以方便地訪問、修改、添加和刪除DOM樹的結點和內容 。
DOM樹擴展
根據W3C的定義,DOM樹結點的屬性包括標記名(nodeName)、結點類型(node Type,取值為TagTxt)、結點內容(data)、父結點對象集合(parent Node)、子結點對象集合(firstChild,lastChild)、兄弟結點對象集合(previous Sibling,nextSibling)等。DOM樹結點的這些屬性給出了頁面的基本內容和結構信息,但不能反映標籤、屬性以及內容等與主題的相關程度,因而缺乏主題提取所需的語義。對DOM樹擴展的總體思路為:考慮HTML頁面標籤的類別,以及標籤屬性值對頁面主題信息的影響,將這種影響納入對頁面內容要素的計算中,對DOM樹結點進行語義擴展,同時引入結點影響度因子來刻畫該結點在樹中的重要程度。
DOM樹結點語義擴展
為了增加DOM樹結點與頁面主題信息相關程度的語義信息,計算結點內容的重要度,將HTML標籤的類別(Category)、非連結文字數(WordNum)、超連結數(LinkNum)、屬性集(Attibution)和影響度因子(Influence)等屬性添加到結點中,擴展其語義。HTML標籤依據其作用可分為5類:
•描述標題及頁面概要信息的標籤:如〈title〉、〈meta〉等。
•規劃網頁布局的標籤:如〈table〉、〈tr〉、〈td〉、〈p〉、〈div〉等,其作用是描述網頁內容的布局結構。
•描述顯示特點的標籤:如〈b〉、〈I〉、〈strong〉、〈h1〉-〈h6〉等,其作用是強調重點內容,引起人們注意。
•超連結相關的標籤,表示網頁間的內容相關性信息。
•其他標籤,如設定圖像的標籤〈img〉,在文本提取時將忽略這類標籤。
根據HTML標籤在刻畫網頁特徵時的語義功能,將DOM樹結點分為6種類別:標題類(TITLE)、正文類(CONTENT)、視覺類(VISION)、分塊類(BLOCK)、超鏈類(LINK)和其他類(OTHER),不同類的結點對Web信息提取的重要度不同。
•標題類(TITLE):指HTML文檔中標題標籤的專有類別。
•正文類(CONTENT):指包含網頁正文內容的標籤類別,如包含文字的〈td〉標籤。
•視覺類(VISION):指描述頁面顯示特性的標籤類別,如〈b〉、〈strong〉等。
•分塊類(BLOCK):指用於網頁內容分塊的標籤類別,如〈table〉、〈tr〉等。
•超鏈類(LINK):指包含超連結的標籤類別,如〈a〉。
•其他類(OTHER):指不屬於以上5種類別的標籤類型。
 文檔對象模型
文檔對象模型以上6類結點對頁面主題的重要度依次降低。擴展後的DOM樹結點結構如圖所示。
結點影響度因子
Web頁面的有效內容大多存在DOM樹的葉結點中,DOM樹中的其餘結點主要用於表示內容分塊及頁面的外觀特性。在已有的頁面信息提取方法中,對這些結點往往只考慮內容分塊作用,而忽略了視覺結點對頁面內容的影響。實際上,網頁設計者通常會利用顯示標籤以及標籤屬性強調重點內容,不妨稱其為強調標籤和標籤強調屬性,例如〈b〉標籤,或〈font〉標籤的size屬性。此外,不同類別結點對其子孫結點內容塊的影響也是不同的。例如,以標題類結點為祖先結點的內容塊,其重要程度應更高。為了評判DOM樹中結點對內容的影響程度,定義了結點影響度因子。
定義1(DOM樹結點影響度因子)表示結點對內容影響的相對程度,用Influence(node)表示,Influence(node) ∈[0,1]。該值越大,表明影響程度越高。
結點影響度因子的確定要綜合考慮結點類別和標籤強調屬性,其初值按TITLE,CONTENT,VISION,BLOCK,LINK,OTHER類別降序排列。可構造影響度因子初值向量Initvlale。同時結點影響度因子具有傳遞性,即某結點的影響度因子值應向其子結點傳遞。因此,葉結點的影響度因子可由下式計算:Influence(leaf) =∑ki=Influence(Ancestori)其中,Ancestori是葉結點的祖先結點,k為祖先結點數。
接口
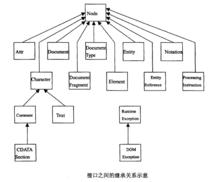 文檔對象模型
文檔對象模型主要的接口有:
•Node接口:它是文檔中節點的基類型。定義了基本的訪問和改變文檔結構的方法。
•Document接口:它代表整個文檔。可創建文檔中的各種節點(元素、注釋、處理指令等),創建的節點中帶有一個OwnerDoculnent屬性表示創建它們的Document對象。
•DocumentFragment接口:它代表文檔樹的子樹,相當一個小型文檔。
•Attr接口:它代表元素節點的屬性。有意思的是它並不認為是該元素節點的子節點,不構成DOM樹的一部分。同時也不是DocumentFragment節點的直接子節點。
•CharacterData接口:它維護了DOMsitrgn字元串並提供讀寫操作的接口。但不直接對應文檔的某種類型節點。
•Text接口:它從CharacterData繼承而來。代表元素或屬性的一段連續的文本內容。它有一個派生的接口CDATAsection,目的是:CDATASeciton節點的內容將不會作任何轉化;使用Node中的nomraliez方法時相鄰的Text節點會合併成一個節點,但使用CDATASeciton可避免合併。
•Comment接口:它也從CharacterData繼承而來。代表注釋中的文本內容。
•NodeList接口:用於管理有序的節點集。
•Entity接口:它代表實體;EntityReference代表實體的引用。
•NamedNodeMap接口:用於管理無序的節點集。
•DOMImplementation接口:它提供與DOM模型的實例無關的接口。CreateDocument可創建一個Document對象;haseFature可判斷DOM實現是否支持某一模組。
•Notation接口:它代表文檔中的符號定義。
•ProcessingInstruction接口:它代表處理指令。
•DOMException接口:異常處理。由於程式中的邏輯錯誤、數據丟失或DOM實現本身不穩定引起的錯誤。在程式處理過程中,由方法返回一個錯誤值。接口之間的繼承關係可參看圖。
特徵
Document Object Model的歷史可以追溯至1990年代後期微軟與Netscape的“瀏覽器大戰” (browser wars),雙方為了在JavaScript與JScript一決生死,於是大規模的賦予瀏覽器強大的功能。微軟在網頁技術上加入了不少專屬事物,計有VBScript、ActiveX、以及微軟自家的DHTML格式等,使不少網頁使用非微軟平台及瀏覽器無法正常顯示。DOM即是當時蘊釀出來的傑作。
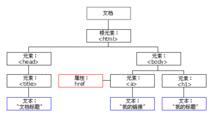 文檔對象模型
文檔對象模型DOM分為HTML DOM和XML DOM兩種。它們分別定義了訪問和操作HTML/XML文檔的標準方法,並將對應的文檔呈現為帶有元素、屬性和文本的樹結構(節點樹),如下圖所示: 1)DOM樹定義了HTML/XML文檔的邏輯結構,給出了一種應用程式訪問和處理XML文檔的方法。
2)在DOM樹中,有一個根節點,所有其他的節點都是根節點的後代。
3) 在套用過程中,基於DOM的HTML/XML分析器將一個HTML/XML文檔轉換成一棵DOM樹,應用程式通過對DOM樹的操作,來實現對HTML/XML文檔數據的操作。
