
類型
 數據分析
數據分析在統計學領域,有些人將數據分析劃分為描述性統計分析、探索性數據分析以及驗證性數據分析;其中,探索性數據分析側重於在數據之中發現新的特徵,而驗證性數據分析則側重於已有假設的證實或證偽 。
探索性數據分析是指為了形成值得假設的檢驗而對數據進行分析的一種方法,是對傳統統計學假設檢驗手段的補充。該方法由美國著名統計學家約翰·圖基(John Tukey)命名。
定性數據分析又稱為“定性資料分析”、“定性研究”或者“質性研究資料分析”,是指對諸如詞語、照片、觀察結果之類的非數值型數據(或者說資料)的分析。
分析工具
Excel作為常用的分析工具,可以實現基本的分析工作,在商業智慧型領域Cognos、Style Intelligence、Microstrategy、Brio、BO和Oracle以及國內產品如:大數據魔鏡、finebi、Yonghong Z-Suite BI套件等。
案例
沃爾瑪經典行銷案例:啤酒與尿布
“啤酒與尿布”的故事產生於20世紀90年代的美國沃爾瑪超市中,沃爾瑪的超市管理人員分析銷售數據時發現了一個令人難於理解的現象:在某些特定的情況下,“啤酒”與“尿布”兩件看上去毫無關係的商品會經常出現在同一個購物籃中,這種獨特的銷售現象引起了管理人員的注意,經過後續調查發現,這種現象出現在年輕的父親身上。
在美國有嬰兒的家庭中,一般是母親在家中照看嬰兒,年輕的父親前去超市購買尿布。父親在購買尿布的同時,往往會順便為自己購買啤酒,這樣就會出現啤酒與尿布這兩件看上去不相干的商品經常會出現在同一個購物籃的現象。如果這個年輕的父親在賣場只能買到兩件商品之一,則他很有可能會放棄購物而到另一家商店, 直到可以一次同時買到啤酒與尿布為止。沃爾瑪發現了這一獨特的現象,開始在賣場嘗試將啤酒與尿布擺放在相同的區域,讓年輕的父親可以同時找到這兩件商品,並很快地完成購物;而沃爾瑪超市也可以讓這些客戶一次購買兩件商品、而不是一件,從而獲得了很好的商品銷售收入,這就是“啤酒與尿布” 故事的由來。
當然“啤酒與尿布”的故事必須具有技術方面的支持。1993年美國學者Agrawal提出通過分析購物籃中的商品集合,從而找出商品之間關聯關係的關聯算法,並根據商品之間的關係,找出客戶的購買行為。艾格拉沃從數學及計算機算法角度提 出了商品關聯關係的計算方法——Aprior算法。沃爾瑪從上個世紀 90 年代嘗試將 Aprior 算 法引入到 POS機數據分析中,並獲得了成功,於是產生了“啤酒與尿布”的故事。
Suncorp-Metway使用數據分析實現智慧行銷
Suncorp-Metway是澳大利亞一家提供普通保險、銀行業、壽險和理財服務的多元化金融服務集團, 旗下擁有5個業務部門,管理著14類商品,由公司及共享服務部門提供支持,其在澳大利亞和紐西蘭的運營業務與900多萬名客戶有合作關係。
該公司過去十年間的合併與收購,使客戶群增長了200%,這極大增加了客戶群數據管理的複雜性,如果解決不好,必將對公司利潤產生負面影響.為此,IBM公司為其提供了一套解決方案,組件包括:IBM Cognos 8 BI、IBMInitiate Master Data Service諛IBM Unica。
採用該方案後,Suncorp-Metway公司至少在以下三項業務方面取得顯著成效:
1、顯著增加了市場份額,但沒有增加行銷開支;
2、每年大約能夠節省1000萬美元的集成與相關成本;
3、避免向同一戶家庭重複郵寄相同信函並且消除冗餘系統,從而同時降低直接郵寄與運營成本。
由此可見,Suncorp-Metway公司通過該方案將此前多個孤立來源的數據集成起來,實現智慧行銷,對控制成本,增加利潤起到非常積極的作用。
數據分析幫助辛辛那提動物園提高客戶滿意度
辛辛那提動植物園成立於1873年,是世界上著名的動植物園之一,以其物種保護和保存以及高成活率繁殖飼養計畫享有極高聲譽。它占地面積71英畝,園內有500種動物和3000多種植物,是國內遊客人數最多的動植物園之一,曾榮獲Zagat十佳動物園,並被《父母》(Parent)雜誌評為最受兒童喜歡的動物園,每年接待遊客130多萬人。
辛辛那提動植物園是一個非營利性組織,是俄亥州同時也是美國國內享受公共補貼最低的動植物園,除去政府補貼,2600萬美元年度預算中,自籌資金部分達到三分之二以上。為此,需要不斷地尋求增加收入。而要做到這一點,最好辦法是為工作人員和遊客提供更好的服務,提高遊覽率。從而實現動植物園與客戶和納稅人的雙贏。
藉助於該方案強大的收集和處理能力、互聯能力、分析能力以及隨之帶來的洞察力,在部署後,企業實現了以下各方面的受益:
幫助動植物園了解每個客戶瀏覽、使用和消費模式,根據時間和地理分布情況採取相應的措施改善遊客體驗,同時實現營業收入最大化。
根據消費和遊覽行為對動植物園遊客進行細分,針對每一類細分遊客開展行銷和促銷活動,顯著提高忠誠度和客戶保有量。.
識別消費支出低的遊客,針對他們傳送具有戰略性的直寄廣告,同時通過具有創意性的行銷和激勵計畫獎勵忠誠客戶。
360度全方位了解客戶行為,最佳化行銷決策,實施解決方案後頭一年節省40,000多美元行銷成本,同時強化了可測量的結果。
採用地理分析顯示大量未實現預期結果的促銷和折扣計畫,重新部署資源支持產出率更高的業務活動,動植物園每年節省100,000多美元。
通過強化行銷提高整體遊覽率,2011年至少新增50,000人次“遊覽”。
提供洞察結果強化運營管理。例如,即將關門前冰激淋銷售出現高潮,動植物園決定延長冰激淋攤位營業時間,直到關門為止。這一措施夏季每天可增加2,000美元收入。
與上年相比,餐飲銷售增加30.7%,零售銷售增加5.9%。
動植物園高層管理團隊可以制定更好的決策,不需要 IT 介入或提供支持。
將分析引入會議室,利用直觀工具幫助業務人員掌握數據。
方法
具體方法
數據分析有極廣泛的套用範圍。典型的數據分析可能包含以下三個步:
1、探索性數據分析:當數據剛取得時,可能雜亂無章,看不出規律,通過作圖、造表、用各種形式的方程擬合,計算某些特徵量等手段探索規律性的可能形式,即往什麼方向和用何種方式去尋找和揭示隱含在數據中的規律性。
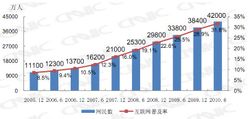 CNNIC數據:中國網民規模
CNNIC數據:中國網民規模2、模型選定分析,在探索性分析的基礎上提出一類或幾類可能的模型,然後通過進一步的分析從中挑選一定的模型。
3、推斷分析:通常使用數理統計方法對所定模型或估計的可靠程度和精確程度作出推斷。
分析方法
1、列表法
將實驗數據按一定規律用列表方式表達出來是記錄和處理實驗數據最常用的方法。表格的設計要求對應關係清楚、簡單明了、有利於發現相關量之間的物理關係;此外還要求在標題欄中註明物理量名稱、符號、數量級和單位等;根據需要還可以列出除原始數據以外的計算欄目和統計欄目等。最後還要求寫明表格名稱、主要測量儀器的型號、量程和準確度等級、有關環境條件參數如溫度、濕度等。
2、作圖法
作圖法可以最醒目地表達物理量間的變化關係。從圖線上還可以簡便求出實驗需要的某些結果(如直線的斜率和截距值等),讀出沒有進行觀測的對應點(內插法)或在一定條件下從圖線的延伸部分讀到測量範圍以外的對應點(外推法)。此外,還可以把某些複雜的函式關係,通過一定的變換用直線圖表示出來。例如半導體熱敏電阻的電阻與溫度關係為,取對數後得到,若用半對數坐標紙,以lgR為縱軸,以1/T為橫軸畫圖,則為一條直線。
3、數據分析主要包含:
1. 簡單數學運算(Simple Math)
2. 統計(Statistics)
3. 快速傅立葉變換(FFT)
4. 平滑和濾波(Smoothing and Filtering)
5.基線和峰值分析(Baseline and Peak Analysis)
數據來源
1、搜尋引擎蜘蛛抓取數據;
2、網站IP、PV等基本數據;
3、網站的HTTP回響時間數據;
4、網站流量來源數據。
步驟
數據分析過程的主要活動由識別信息需求、收集數據、分析數據、評價並改進數據分析的有效性組成。
識別需求
識別信息需求是確保數據分析過程有效性的首要條件,可以為收集數據、分析數據提供清晰的目標。識別信息需求是管理者的職責管理者應根據決策和過程控制的需求,提出對信息的需求。就過程控制而言,管理者應識別需求要利用那些信息支持評審過程輸入、過程輸出、資源配置的合理性、過程活動的最佳化方案和過程異常變異的發現。
收集數據
有目的的收集數據,是確保數據分析過程有效的基礎。組織需要對收集數
據的內容、渠道、方法進行策劃。策劃時應考慮:
①將識別的需求轉化為具體的要求,如評價供方時,需要收集的數據可能包括其過程能力、測量系統不確定度等相關數據;
②明確由誰在何時何處,通過何種渠道和方法收集數據;
③記錄表應便於使用; ④採取有效措施,防止數據丟失和虛假數據對系統的干擾。
分析數據
分析數據是將收集的數據通過加工、整理和分析、使其轉化為信息,通常用方法有:
老七種工具,即排列圖、因果圖、分層法、調查表、散步圖、直方圖、控制圖;
新七種工具,即關聯圖、系統圖、矩陣圖、KJ法、計畫評審技術、PDPC法、矩陣數據圖;
過程改進
數據分析是質量管理體系的基礎。組織的管理者應在適當時,通過對以下問題的分析,評估其有效性:
①提供決策的信息是否充分、可信,是否存在因信息不足、失準、滯後而導致決策失誤的問題;
②信息對持續改進質量管理體系、過程、產品所發揮的作用是否與期望值一致,是否在產品實現過程中有效運用數據分析;
③收集數據的目的是否明確,收集的數據是否真實和充分,信息渠道是否暢通;
④數據分析方法是否合理,是否將風險控制在可接受的範圍;
⑤數據分析所需資源是否得到保障。
意義
在產品的整個壽命周期,包括從市場調研到售後服務和最終處置的各個過程都需要適當運用數據分析過程,以提升有效性。例如J.克卜勒通過分析行星角位置的觀測數據,找出了行星運動規律。又如,一個企業的領導人要通過市場調查,分析所得數據以判定市場動向,從而制定合適的生產及銷售計畫。因此數據分析有極廣泛的套用範圍。
網路行銷
對網路行銷的意義
在中國,儘管網路行銷的概念很火,但網路行銷的效率低於一些已開發國家也是事實。無論是門戶廣告、搜尋引擎廣告,還是廣告聯盟,從行業平均轉化率上看,都要低於國外較為成熟國家的水平。據估計,國內的Bounce rate(蹦失率,即用戶只瀏覽第一頁即離開的比例)介於90%~99%之間,而歐美的Bounce rate則是70%左右。
誠然,國內的網路行銷環境處於發展之中,環境不那么盡如人意,但中國網際網路信息中心分析師孫秀秀認為,出現這種情況的很多責任在投放廣告的企業方,在於對行銷背後的數據分析工作的不重視,沒有精確定位有效的客戶群,導致大量的展示給了不相關的網民。
通常,廣告投放前的數據分析可以分為兩步走。第一步:描述目標群體。比如,目標群體是18~25歲,上網購物的年輕女性。第二步:描述此群體的網路活動軌跡。
也就是說,知道目標客戶群上什麼網站、做什麼事、在什麼時間地點能夠找到他非常重要。實際上,論復蓋面,網路行銷還遠遠趕不上傳統媒體。2009年底中國的網際網路普及率為28.9%,而同期中國電視的普及率卻已經超過80%。但是,仍舊有很多有遠見的企業選擇網路行銷。其中的一個重要原因是,網路行銷的全過程都可以被追蹤到,通過數據分析可以隨時調整投放方式。
採用的分析方法如下:
1、描述性統計分析
包括樣本基本資料的描述,作各變數的次數分配及百分比分析,以了解樣本的分布情況。此外,以平均數和標準差來描述市場導向、競爭優勢、組織績效等各個構面,以了解樣本企業的管理人員對這些相關變數的感知,並利用t檢驗及相關分析對背景變數所造成的影響做檢驗。
2、Cronbach’a信度係數分析
信度是指測驗結果的一致性、穩定性及可靠性,一般多以內部一致性(consistency)來加以表示該測驗信度的高低。信度係數愈高即表示該測驗的結果愈一致、穩定與可靠。針對各研究變數的衡量題項進行Cronbach’a信度分析,以了解衡量構面的內部一致性。一般來說,Cronbach’a僅大於0.7為高信度,低於0.35為低信度(Cuieford,1965),0.5為最低可以接受的信度水準(Nunnally,1978)。
3、探索性因素分析(exploratory factor analysis)和驗證性因素分析(confirmatory factor analysis)
用以測試各構面衡量題項的聚合效度(convergent validity)與區別效度(discriminant validity)。因為僅有信度是不夠的,可信度高的測量,可能是完全無效或是某些程度上無效。所以我們必須對效度進行檢驗。效度是指工具是否能測出在設計時想測出的結果。收斂效度的檢驗根據各個項目和所衡量的概念的因素的負荷量來決定;而區別效度的檢驗是根據檢驗性因素分析計算理論上相關概念的相關係數,檢定相關係數的95%信賴區間是否包含1.0,若不包含1.0,則可確認為具有區別效度(Anderson,1987)。
4、結構方程模型分析(structural equations modeling)
由於結構方程模型結合了因素分析(factor analysis)和路徑分析(path analysis),並納入計量經濟學的聯立方程式,可同時處理多個因變數,容許自變數和因變數含測量誤差,可同時估計因子結構和因子關係。容許更大彈性的測量模型,可估計整個模型的擬合程度(Bollen和Long,1993),因而適用於整體模型的因果關係。在模型參數的估計上,採用最大似然估計法(Maximum Likelihood,ML);在模型的適合度檢驗上,以基本的擬合標準(preliminary fit criteria)、整體模型擬合優度(overall model fit)以及模型內在結構擬合優度(fit of internal structure of model)(Bagozzi和Yi,1988)三個方面的各項指標作為判定的標準。在評價整體模式適配標準方面,本研究採用x2(卡方)/df(自由度)值、擬合優度指數(goodness.of.f:iJt.in.dex,GFI)、平均殘差平方根(root—mean.square:residual,RMSR)、近似誤差均方根(root-mean—square-error-of-approximation,RMSEA)等指標;模型內在結構擬合優度則參考Bagozzi和Yi(1988)的標準,考察所估計的參數是否都到達顯著水平。
