![hibernate[開放原始碼的對象關係映射框架]](/img/2/239/nBnauM3X2MDM1MzMxYTO1QzM5QTMwkzMxgzNzQTNwAzMwIzL2kzLygzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "hibernate[開放原始碼的對象關係映射框架]")
發展歷程
 Hibernate
Hibernate2002年,已經有人開始關注和使用Hibernate了。
2003年9月,Hibernate開發團隊進入JBoss公司,開始全職開發Hibernate,從這個時候開始Hibernate得到了突飛猛進的普及和發展。
2004年,整個Java社區開始從實體bean向Hibernate轉移,特別是在RodJohnson的著作《ExpertOne-on-OneJ2EEDevelopmentwithoutEJB》出版後,由於這本書以紮實的理論、充分的論據和詳實的論述否定了EJB,提出了輕量級敏捷開發理念之後,以Hibernate和Spring為代表的輕量級開源框架開始成為Java世界的主流和事實標準。在2004年Sun領導的J2EE5.0標準制定當中的持久化框架標準正式以Hibernate為藍本。
2006年,J2EE5.0標準正式發布以後,持久化框架標準JavaPersistentAPI(簡稱JPA)基本上是參考Hibernate實現的,而Hibernate在3.2版本開始,已經完全兼容JPA標準。
編程開發
編程環境
Hibernate是一個以LGPL(LesserGNUPublicLicense)許可證形式發布的開源項目。在Hibernate官網上有下載Hibernate包的說明。Hibernate包以原始碼或者二進制的形式提供。
編程工具
Eclipse:一個開放源
代碼的、基於Java的可擴展開發平台。
NetBeans:開放源碼的Java集成開發環境,適用於各種客戶機和Web套用。
IntelliJIDEA:在代碼自動提示、代碼分析等方面的具有很好的功能。
MyEclipse:由Genuitec公司開發的一款商業化軟體,是套用比較廣泛的Java應用程式集成開發環境。
EditPlus:如果正確配置Java的編譯器“Javac”以及解釋器“Java”後,可直接使用EditPlus編譯執行Java程式。
語言特點
將對資料庫的操作轉換為對Java對象的操作,從而簡化開發。通過修改一個“持久化”對象的屬性從而修改資料庫表中對應的記錄數據。
提供執行緒和進程兩個級別的快取提升應用程式性能。
有豐富的映射方式將Java對象之間的關係轉換為資料庫表之間的關係。
禁止不同資料庫實現之間的差異。在Hibernate中只需要通過“方言”的形式指定當前使用的資料庫,就可以根據底層資料庫的實際情況生成適合的SQL語句。
非侵入式:Hibernate不要求持久化類實現任何接口或繼承任何類,POJO即可。
核心API
Hibernate的API一共有6個,分別為:Session、SessionFactory、Transaction、Query、Criteria和Configuration。通過這些接口,可以對持久化對象進行存取、事務控制。
Session
Session接口負責執行被持久化對象的CRUD操作(CRUD的任務是完成與資料庫的交流,包含了很多常見的SQL語句)。但需要注意的是Session對象是非執行緒安全的。同時,Hibernate的session不同於JSP套用中的HttpSession。這裡當使用session這個術語時,其實指的是Hibernate中的session,而以後會將HttpSession對象稱為用戶session。
SessionFactory
SessionFactory接口負責初始化Hibernate。它充當數據存儲源的代理,並負責創建Session對象。這裡用到了工廠模式。需要注意的是SessionFactory並不是輕量級的,因為一般情況下,一個項目通常只需要一個SessionFactory就夠,當需要操作多個資料庫時,可以為每個資料庫指定一個SessionFactory。
Transaction
Transaction接口是一個可選的API,可以選擇不使用這個接口,取而代之的是Hibernate的設計者自己寫的底層事務處理代碼。Transaction接口是對實際事務實現的一個抽象,這些實現包括JDBC的事務、JTA中的UserTransaction、甚至可以是CORBA事務。之所以這樣設計是能讓開發者能夠使用一個統一事務的操作界面,使得自己的項目可以在不同的環境和容器之間方便地移植。
Query
Query接口讓你方便地對資料庫及持久對象進行查詢,它可以有兩種表達方式:HQL語言或本地資料庫的SQL語句。Query經常被用來綁定查詢參數、限制查詢記錄數量,並最終執行查詢操作。
Criteria
Criteria接口與Query接口非常類似,允許創建並執行面向對象的標準化查詢。值得注意的是Criteria接口也是輕量級的,它不能在Session之外使用。
Configuration
Configuration類的作用是對Hibernate進行配置,以及對它進行啟動。在Hibernate的啟動過程中,Configuration類的實例首先定位映射文檔的位置,讀取這些配置,然後創建一個SessionFactory對象。雖然Configuration類在整個Hibernate項目中只扮演著一個很小的角色,但它是啟動hibernate時所遇到的第一個對象。
版本
Hibernate版本
Hibernate版本更新速度很快,目前為止有多個階段性的版本:Hibernate3,Hibernate4和Hibernate5,這一點程式設計師從其Jar檔案名稱便可以看出來。目前(2018-01-10)最新發布的版本是HibernateORM5.2.12.FinalReleased。
Hibernate2系列的最高版本是Hibernate2.1.8,Hibernate3系列的最高版本是hibernate-distribution-3.6.10.Final-dist版,但使用較多且較穩定的版本是Hibernate3.1.3或Hibernate3.1.2。
另外,自Hibernate3發布以來,其產品線愈加成熟,相繼出現了Hibernate注釋、Hibernate實體管理器、Hibernate外掛程式工具等一系列產品套件。在方便程式設計師使用Hibernate進行應用程式的開發的同時,也逐漸增強了Hibernate產品線的實力。
目前Hibernate已經出現了4.0以及5.0的版本
主鍵介紹
Assigned
Assigned方式由用戶生成主鍵值,並且要在save()之前指定否則會拋出異常。
特點:主鍵的生成值完全由用戶決定,與底層資料庫無關。用戶需要維護主鍵值,在調用session.save()之前要指定主鍵值。
Hilo
Hilo使用高低位算法生成主鍵,高低位算法使用一個高位值和一個低位值,然後把算法得到的兩個值拼接起來作為資料庫中的唯一主鍵。Hilo方式需要額外的資料庫表和欄位提供高位值來源。默認情況下使用的表是ibernate_unique_key,默認欄位叫作next_hi。next_hi必須有一條記錄否則會出現錯誤。
特點:需要額外的資料庫表的支持,能保證同一個資料庫中主鍵的唯一性,但不能保證多個資料庫之間主鍵的唯一性。Hilo主鍵生成方式由Hibernate維護,所以Hilo方式與底層資料庫無關,但不應該手動修改hi/lo算法使用的表的值,否則會引起主鍵重複的異常。
Increment
I
 Hibernate相關書籍
Hibernate相關書籍特點:由Hibernate本身維護,適用於所有的資料庫,不適合多進程並發更新資料庫,適合單一進程訪問資料庫。不能用於群集環境。
Identity
Identity方式根據底層資料庫,來支持自動增長,不同的資料庫用不同的主鍵增長方式。
特點:與底層資料庫有關,要求資料庫支持Identity,如MySQl中是auto_increment,SQLServer中是Identity,支持的資料庫有MySql、SQLServer、DB2、Sybase和HypersonicSQL。Identity無需Hibernate和用戶的干涉,使用較為方便,但不便於在不同的資料庫之間移植程式。
Sequence
Sequence需要底層資料庫支持Sequence方式,例如Oracle資料庫等
特點:需要底層資料庫的支持序列,支持序列的資料庫有DB2、PostgreSql、Oracle、SAPDb等在不同資料庫之間移植程式,特別從支持序列的資料庫移植到不支持序列的資料庫需要修改配置檔案。
Native
Native主鍵生成方式會根據不同的底層資料庫自動選擇Identity、Sequence、Hilo主鍵生成方式
特點:根據不同的底層資料庫採用不同的主鍵生成方式。由於Hibernate會根據底層資料庫採用不同的映射方式,因此便於程式移植,項目中如果用到多個資料庫時,可以使用這種方式。
UUID
UUID使用128位UUID算法生成主鍵,能夠保證網路環境下的主鍵唯一性,也就能夠保證在不同資料庫及不同伺服器下主鍵的唯一性。
特點:能夠保證資料庫中的主鍵唯一性,生成的主鍵占用比較多的存貯空間
ForeignGUID
Foreign用於一對一關係中。GUID主鍵生成方式使用了一種特殊算法,保證生成主鍵的唯一性,支持SQLServer和MySQL
包的作用
net.sf.hibernate.
該包的類基本上都是接口類和異常類
net.sf.hibernate.cache.
JCS的實現類
net.sf.hibernate.cfg.
配置檔案讀取類
net.sf.hibernate.collection.
Hibernate集合接口實現類,例如List,Set,Bag等等,Hibernate之所以要自行編寫集合接口實現類是為了支持lazyloading
net.sf.hibernate.connection.
幾個資料庫連線池的Provider
net.sf.hibernate.dialect.
支持多種資料庫特性,每個Dialect實現類代表一種資料庫,描述了該資料庫支持的數據類型和其它特點,例如是否有AutoIncrement,是否有Sequence,是否有分頁sql等等
net.sf.hibernate.eg.
Hibernate文檔中用到的例子
net.sf.hibernate.engine.
這個包的類作用比較散
net.sf.hibernate.expression.
HQL支持的表達式
net.sf.hibernate.hq.
HQL實現
net.sf.hibernate.id.
ID生成器
net.sf.hibernate.impl.
最核心的包,一些重要接口的實現類,如Session,SessionFactory,Query等
net.sf.hibernate.jca.
JCA支持,把Session包裝為支持JCA的接口實現類
net.sf.hibernate.jmx.
JMX是用來編寫AppServer的管理程式的,大概是JMX部分接口的實現,使得AppServer可以通過JMX接口管理Hibernate
net.sf.hibernate.loader.
也是很核心的包,主要是生成sql語句的
net.sf.hibernate.lob.
Blob和Clob支持
net.sf.hibernate.mapping.
hbm檔案的屬性實現
net.sf.hibernate.metadata.
PO的Meta實現
net.sf.hibernate.odmg.
ODMG是一個ORM標準,這個包是ODMG標準的實現類
net.sf.hibernate.persister.
核心包,實現持久對象和表之間的映射
net.sf.hibernate.proxy.
Proxy和LazyLoading支持
net.sf.hibernate.ps.
該包是PreparedStatmentCache
net.sf.hibernate.sql.
生成JDBCsql語句的包
net.sf.hibernate.test.
測試類,你可以用junit來測試Hibernate
net.sf.hibernate.tool.hbm2ddl.
用hbm配置檔案生成DDL
net.sf.hibernate.transaction.
HibernateTransaction實現類
net.sf.hibernate.type.
Hibernate中定義的持久對象的屬性的數據類型
net.sf.hibernate.util.
一些工具類,作用比較散
net.sf.hibernate.xml.
XML數據綁定
快取管理
 Hibernate
Hibernate第一級快取第二級快取存放數據的形式相互關聯的持久化對象的散裝數據快取的範圍。
事務範圍,每個事務都有單獨的第一級快取進程範圍或集群範圍,快取被同一個進程或集群範圍內的所有事務共享並發訪問策略由於每個事務都擁有單獨的第一級快取,不會出現並發問題,無需提供並發訪問策略由於多個事務會同時訪問第二級快取中相同數據,因此必須提供適當的並發訪問策略,來保證特定的事務隔離級別數據過期策略沒有提供數據過期策略。處於一級快取中的對象永遠不會過期,除非應用程式顯式清空快取或者清除特定的對象必須提供數據過期策略,如基於記憶體的快取中的對象的最大數目,允許對象處於快取中的最長時間,以及允許對象處於快取中的最長空閒時間。
物理存儲介質記憶體和硬碟對象的散裝數據首先存放在基於記憶體的快取中,當記憶體中對象的數目達到數據過期策略中指定上限時,就會把其餘的對象寫入基於硬碟的快取中。
快取的軟體實現在Hibernate的Session的實現中包含了快取的實現由第三方提供,Hibernate僅提供了快取適配器(CacheProvider)。用於把特定的快取外掛程式集成到Hibernate中。啟用快取的方式只要應用程式通過Session接口來執行保存、更新、刪除、載入和查詢資料庫數據的操作,Hibernate就會啟用第一級快取,把資料庫中的數據以對象的形式拷貝到快取中,對於批量更新和批量刪除操作,如果不希望啟用第一級快取,可以繞過HibernateAPI,直接通過JDBC API來執行指操作。用戶可以在單個類或類的單個集合的粒度上配置第二級快取。如果類的實例被經常讀但很少被修改,就可以考慮使用第二級快取。只有為某個類或集合配置了第二級快取,Hibernate在運行時才會把它的實例加入到第二級快取中。用戶管理快取的方式第一級快取的物理介質為記憶體,由於記憶體容量有限,必須通過恰當的檢索策略和檢索方式來限制載入對象的數目。Session的evict()方法可以顯式清空快取中特定對象,但這種方法不值得推薦。第二級快取的物理介質可以是記憶體和硬碟,因此第二級快取可以存放大量的數據,數據過期策略的maxElementsInMemory屬性值可以控制記憶體中的對象數目。管理第二級快取主要包括兩個方面:選擇需要使用第二級快取的持久類,設定合適的並發訪問策略:選擇快取適配器,設定合適的數據過期策略。
一級快取
當應用程式調用Session的save()、update()、saveOrUpdate()、get()或load(),以及調用查詢接口的list()、iterate()或filter()方法時,如果在Session快取中還不存在相應的對象,Hibernate就會把該對象加入到第一級快取中。當清理快取時,Hibernate會根據快取中對象的狀態變化來同步更新資料庫。Session為應用程式提供了兩個管理快取的方法:evict(Objectobj):從快取中清除參數指定的持久化對象。clear():清空快取中所有持久化對象。
二級快取
3.1.Hibernate的二級快取策略的一般過程如下:
1)條件查詢的時候,總是發出一條select*fromtable_namewhere….(選擇所有欄位)這樣的SQL語句查詢資料庫,一次獲得所有的數據對象。
2)把獲得的所有數據對象根據ID放入到第二級快取中。
3)當Hibernate根據ID訪問數據對象的時候,首先從Session一級快取中查;查不到,如果配置了二級快取,那么從二級快取中查;查不到,再查詢資料庫,把結果按照ID放入到快取。
4)刪除、更新、增加數據的時候,同時更新快取。
Hibernate的二級快取策略,是針對於ID查詢的快取策略,對於條件查詢則毫無作用。為此,Hibernate提供了針對條件查詢的QueryCache。
3.2.什麼樣的數據適合存放到第二級快取中?1很少被修改的數據2不是很重要的數據,允許出現偶爾並發的數據3不會被並發訪問的數據4參考數據,指的是供套用參考的常量數據,它的實例數目有限,它的實例會被許多其他類的實例引用,實例極少或者從來不會被修改。
3.3.不適合存放到第二級快取的數據?1經常被修改的數據2財務數據,絕對不允許出現並發3與其他套用共享的數據。
3.4.常用的快取外掛程式Hibernater的二級快取是一個外掛程式,下面是幾種常用的快取外掛程式:
lEhCache:可作為進程範圍的快取,存放數據的物理介質可以是記憶體或硬碟,對Hibernate的查詢快取提供了支持。
lOSCache:可作為進程範圍的快取,存放數據的物理介質可以是記憶體或硬碟,提供了豐富的快取數據過期策略,對Hibernate的查詢快取提供了支持。
lSwarmCache:可作為群集範圍內的快取,但不支持Hibernate的查詢快取。
lJBossCache:可作為群集範圍內的快取,支持事務型並發訪問策略,對Hibernate的查詢快取提供了支持。
上述4種快取外掛程式的對比情況列於表9-3中。
表9-34種快取外掛程式的對比情況
| 緩 存 插 件 | 支 持 只 讀 | 支持非嚴格讀寫 | 支 持 讀 寫 | 支 持 事 務 |
| EhCache | 是 | 是 | 是 | |
| OSCache | 是 | 是 | 是 | |
| SwarmCache | 是 | 是 | ||
| JBossCache | 是 | 是 |
表9-4快取策略的提供器
| 緩 存 插 件 | 提供器(Cache Providers) |
| Hashtable(只能測試時使用) | org.hibernate.cache.HashtableCacheProvider |
| EhCache | org.hibernate.cache.EhCacheProvider |
| OSCache | org.hibernate.cache.OSCacheProvider |
延遲載入
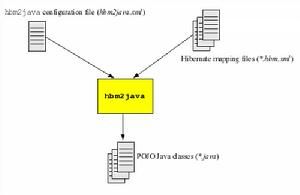 Hibernate
HibernateWeb層延遲載入
幸運的是,Spring框架為Hibernate延遲載入與DAO模式的整合提供了一方便的解決方法。以一個Web套用為例,Spring提供了OpenSessionInViewFilter和OpenSessionInViewInterceptor。我們可以隨意選擇一個類來實現相同的功能。兩種方法唯一的不同就在於interceptor在Spring容器中運行並被配置在web套用的上下文中,而Filter在Spring之前運行並被配置在web.xml中。不管用哪個,他們都在請求將當前會話與當前(資料庫)執行緒綁定時打開Hibernate會話。一旦已綁定到執行緒,這個打開了的Hibernate會話可以在DAO實現類中透明地使用。這個會話會為延遲載入資料庫中值對象的視圖保持打開狀態。一旦這個邏輯視圖完成了,Hibernate會話會在Filter的doFilter方法或者Interceptor的postHandle方法中被關閉。實現方法在web.xml中加入filterfilter-name>hibernateFilter</filter-namefilter-classorg.springframework.orm.hibernate3.support.OpenSessionInViewFilter<filter-classfilterfilter-mappingfilter-name>hibernateFilter</filter-nameurl-pattern>*.do</url-patternfilter-mapping性能最佳化
Hibernate資料庫設計
a)降低關聯的複雜性b)儘量不使用聯合主鍵c)ID的生成機制,不同的資料庫所提供的機制並不完全一樣d)適當的冗餘數據,不過分追求高範式HQL最佳化
HQL如果拋開它同HIBERNATE本身一些快取機制的關聯,HQL的最佳化技巧同普通的SQL最佳化技巧一樣,可以很容易在網上找到一些經驗之談。主配置
a)查詢快取,同下面講的快取不太一樣,它是針對HQL語句的快取,即完全一樣的語句再次執行時可以利用快取數據。但是,查詢快取在一個交易系統(數據變更頻繁,查詢條件相同的機率並不大)中可能會起反作用:它會白白耗費大量的系統資源但卻難以派上用場。b)fetch_size,同JDBC的相關參數作用類似,參數並不是越大越好,而應根據業務特徵去設定c)batch_size同上。d)生產系統中,切記要關掉SQL語句列印。快取
a)資料庫級快取:這級快取是最高效和安全的,但不同的資料庫可管理的層次並不一樣,比如,在Oracle中,可以在建表時指定將整個表置於快取當中。b)SESSION快取:在一個HibernateSESSION有效,這級快取的可干預性不強,大多於HIBERNATE自動管理,但它提供清除快取的方法,這在大批量增加/更新操作是有效的。比如,同時增加十萬條記錄,按常規方式進行,很可能會發現OutofMemeroy的異常,這時可能需要手動清除這一級快取:Session.evict以及Session.clearc)套用快取:在一個SESSIONFACTORY中有效,因此也是最佳化的重中之重,因此,各類策略也考慮的較多,在將數據放入這一級快取之前,需要考慮一些前提條件:i.數據不會被第三方修改(比如,是否有另一個套用也在修改這些數據?)ii.數據不會太大iii.數據不會頻繁更新(否則使用CACHE可能適得其反)iv.數據會被頻繁查詢v.數據不是關鍵數據(如涉及錢,安全等方面的問題)。快取有幾種形式,可以在映射檔案中配置:read-only(唯讀,適用於很少變更的靜態數據/歷史數據),nonstrict-read-write,read-write(比較普遍的形式,效率一般),transactional(JTA中,且支持的快取產品較少)d)分散式快取:同c)的配置一樣,只是快取產品的選用不同,oscache,jbosscache,的大多數項目,對它們的用於集群的使用(特別是關鍵交易系統)都持保守態度。在集群環境中,只利用資料庫級的快取是最安全的。延遲載入
a)實體延遲載入:通過使用動態代理實現b)集合延遲載入:通過實現自有的SET/LIST,HIBERNATE提供了這方面的支持c)屬性延遲載入:方法選用
a)完成同樣一件事,Hibernate提供了可供選擇的一些方式,使用不同的編碼方式對性能有不同的影響。比如:一次返回十萬條記錄,如果用(List/Set/Bag/Map等)進行處理,很可能導致記憶體不夠的問題,而如果用基於游標(ScrollableResults)或Iterator的結果集,則不存在這樣的問題。b)Session的load/get方法,前者會使用二級快取,而後者則不使用。c)Query和list/iterator,如果去仔細研究一下它們,你可能會發現很多有意思的情況,二者主要區別(如果使用了Spring,在HibernateTemplate中對應find,iterator方法):i.list只能利用查詢快取(但在交易系統中查詢快取作用不大),無法利用二級快取中的單個實體,但list查出的對象會寫入二級快取,但它一般只生成較少的執行SQL語句,很多情況就是一條(無關聯)。ii.iterator則可以利用二級快取,對於一條查詢語句,它會先從資料庫中找出所有符合條件的記錄的ID,再通過ID去快取找,對於快取中沒有的記錄,再構造語句從資料庫中查出,因此很容易知道,如果快取中沒有任何符合條件的記錄,使用iterator會產生N+1條SQL語句(N為符合條件的記錄數)iii.通過iterator,配合快取管理API,在海量數據查詢中可以很好的解決記憶體問題,如:while(it.hasNextYouObjectobject=(YouObject)it.next。session.evict(youObject);sessionFactory.evice(YouObject.class,youObject.getId;如果用list方法,很可能就出OutofMemory錯誤了。集合的選用
在Hibernate3.1文檔的“19.5.UnderstandingCollectionperformance”中有詳細的說明。事務控制
事務方面對性能有影響的主要包括:事務方式的選用,事務隔離級別以及鎖的選用a)事務方式選用:如果不涉及多個事務管理器事務的話,不需要使用JTA,只有JDBC的事務控制就可以。b)事務隔離級別:參見標準的SQL事務隔離級別c)鎖的選用:悲觀鎖(一般由具體的事務管理器實現),對於長事務效率低,但安全。樂觀鎖(一般在套用級別實現),如在HIBERNATE中可以定義VERSION欄位,顯然,如果有多個套用運算元據,且這些套用不是用同一種樂觀鎖機制,則樂觀鎖會失效。因此,針對不同的數據應有不同的策略,同前面許多情況一樣,很多時候我們是在效率與安全/準確性上找一個平衡點,無論如何,最佳化都不是一個純技術的問題,你應該對你的套用和業務特徵有足夠的了解。批量操作
即使是使用JDBC,在進行大批數據更新時,BATCH與不使用BATCH有效率上也有很大的差別。可以通過設定batch_size來讓其支持批量操作。舉個例子,要批量刪除某表中的對象,如“deleteAccount”,打出來的語句,HIBERNATE找出了所有ACCOUNT的ID,再進行刪除,這主要是為了維護二級快取,這樣效率肯定高不了,在後續的版本中增加了bulkdelete/update,但這也無法解決快取的維護問題。也就是說,由於有了二級快取的維護問題,HIBERNATE的批量操作效率並不盡如人意。hibernate工作原理:1、通過Configuration().configure();讀取並解析hibernate.cfg.xml配置檔案。2、由hibernate.cfg.xml中的<mappingresource="com/xx/User.hbm.xml"/>讀取解析映射信息。3、通過config.buildSessionFactory();//得到sessionFactory。4、sessionFactory.openSession();//得到session。5、session.beginTransaction();//開啟事務。6、persistentoperate;7、session.getTransaction().commit();//提交事務8、關閉session; Hibernate
Hibernate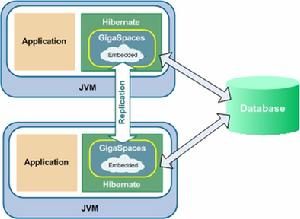 Hibernate
Hibernate