
詳細介紹
語言是人類區別其他動物的本質特性。在所有生物中,只有人類才具有語言能力。人類的多種智慧型都與語言有著密切的關係。人類的邏輯思維以語言為形式,人類的絕大部分知識也是以語言文字的形式記載和流傳下來的。因而,它也是人工智慧的一個重要,甚至核心部分。
用自然語言與計算機進行通信,這是人們長期以來所追求的。因為它既有明顯的實際意義,同時也有重要的理論意義:人們可以用自己最習慣的語言來使用計算機,而無需再花大量的時間和精力去學習不很自然和習慣的各種計算機語言;人們也可通過它進一步了解人類的語言能力和智慧型的機制。
實現人機間自然語言通信意味著要使計算機既能理解自然語言文本的意義,也能以自然語言文本來表達給定的意圖、思想等。前者稱為自然語言理解,後者稱為自然語言生成。因此,自然語言處理大體包括了自然語言理解和自然語言生成兩個部分。歷史上對自然語言理解研究得較多,而對自然語言生成研究得較少。但這種狀況已有所改變。
無論實現自然語言理解,還是自然語言生成,都遠不如人們原來想像的那么簡單,而是十分困難的。從現有的理論和技術現狀看,通用的、高質量的自然語言處理系統,仍然是較長期的努力目標,但是針對一定套用,具有相當自然語言處理能力的實用系統已經出現,有些已商品化,甚至開始產業化。典型的例子有:多語種資料庫和專家系統的自然語言接口、各種機器翻譯系統、全文信息檢索系統、自動文摘系統等。
自然語言處理,即實現人機間自然語言通信,或實現自然語言理解和自然語言生成是十分困難的。造成困難的根本原因是自然語言文本和對話的各個層次上廣泛存在的各種各樣的歧義性或多義性(ambiguity)。
一個中文文本從形式上看是由漢字(包括標點符號等)組成的一個字元串。由字可組成詞,由詞可組成詞組,由詞組可組成句子,進而由一些句子組成段、節、章、篇。無論在上述的各種層次:字(符)、詞、詞組、句子、段,……還是在下一層次向上一層次轉變中都存在著歧義和多義現象,即形式上一樣的一段字元串,在不同的場景或不同的語境下,可以理解成不同的詞串、詞組串等,並有不同的意義。一般情況下,它們中的大多數都是可以根據相應的語境和場景的規定而得到解決的。也就是說,從總體上說,並不存在歧義。這也就是我們平時並不感到自然語言歧義,和能用自然語言進行正確交流的原因。但是一方面,我們也看到,為了消解歧義,是需要極其大量的知識和進行推理的。如何將這些知識較完整地加以收集和整理出來;又如何找到合適的形式,將它們存入計算機系統中去;以及如何有效地利用它們來消除歧義,都是工作量極大且十分困難的工作。這不是少數人短時期內可以完成的,還有待長期的、系統的工作。
以上說的是,一個中文文本或一個漢字(含標點符號等)串可能有多個含義。它是自然語言理解中的主要困難和障礙。反過來,一個相同或相近的意義同樣可以用多箇中文文本或多個漢字串來表示。
因此,自然語言的形式(字元串)與其意義之間是一種多對多的關係。其實這也正是自然語言的魅力所在。但從計算機處理的角度看,我們必須消除歧義,而且有人認為它正是自然語言理解中的中心問題,即要把帶有潛在歧義的自然語言輸入轉換成某種無歧義的計算機內部表示。
歧義現象的廣泛存在使得消除它們需要大量的知識和推理,這就給基於語言學的方法、基於知識的方法帶來了巨大的困難,因而以這些方法為主流的自然語言處理研究幾十年來一方面在理論和方法方面取得了很多成就,但在能處理大規模真實文本的系統研製方面,成績並不顯著。研製的一些系統大多數是小規模的、研究性的演示系統。
目前存在的問題有兩個方面:一方面,迄今為止的語法都限於分析一個孤立的句子,上下文關係和談話環境對本句的約束和影響還缺乏系統的研究,因此分析歧義、詞語省略、代詞所指、同一句話在不同場合或由不同的人說出來所具有的不同含義等問題,尚無明確規律可循,需要加強語用學的研究才能逐步解決。另一方面,人理解一個句子不是單憑語法,還運用了大量的有關知識,包括生活知識和專門知識,這些知識無法全部貯存在計算機里。因此一個書面理解系統只能建立在有限的辭彙、句型和特定的主題範圍內;計算機的貯存量和運轉速度大大提高之後,才有可能適當擴大範圍.
以上存在的問題成為自然語言理解在機器翻譯套用中的主要難題,這也就是當今機器翻譯系統的譯文質量離理想目標仍相差甚遠的原因之一;而譯文質量是機譯系統成敗的關鍵。中國數學家、語言學家周海中教授曾在經典論文《機器翻譯五十年》中指出:要提高機譯的質量,首先要解決的是語言本身問題而不是程式設計問題;單靠若干程式來做機譯系統,肯定是無法提高機譯質量的;另外在人類尚未明了大腦是如何進行語言的模糊識別和邏輯判斷的情況下,機譯要想達到“信、達、雅”的程度是不可能的。
發展歷史
最早的自然語言理解方面的研究工作是機器翻譯。1949年,美國人威弗首先提出了機器翻譯設計方案。20世紀60年代,國外對機器翻譯曾有大規模的研究工作,耗費了巨額費用,但人們當時顯然是低估了自然語言的複雜性,語言處理的理論和技術均不成熱,所以進展不大。主要的做法是存儲兩種語言的單詞、短語對應譯法的大辭典,翻譯時一一對應,技術上只是調整語言的同條順序。但日常生活中語言的翻譯遠不是如此簡單,很多時候還要參考某句話前後的意思。
大約90年代開始,自然語言處理領域發生了巨大的變化。這種變化的兩個明顯的特徵是:
(1)對系統輸入,要求研製的自然語言處理系統能處理大規模的真實文本,而不是如以前的研究性系統那樣,只能處理很少的詞條和典型句子。只有這樣,研製的系統才有真正的實用價值。
(2)對系統的輸出,鑒於真實地理解自然語言是十分困難的,對系統並不要求能對自然語言文本進行深層的理解,但要能從中抽取有用的信息。例如,對自然語言文本進行自動地提取索引詞,過濾,檢索,自動提取重要信息,進行自動摘要等等。
同時,由於強調了“大規模”,強調了“真實文本”,下面兩方面的基礎性工作也得到了重視和加強。
(1)大規模真實語料庫的研製。大規模的經過不同深度加工的真實文本的語料庫,是研究自然語言統計性質的基礎。沒有它們,統計方法只能是無源之水。
(2)大規模、信息豐富的詞典的編制工作。規模為幾萬,十幾萬,甚至幾十萬詞,含有豐富的信息(如包含詞的搭配信息)的計算機可用詞典對自然語言處理的重要性是很明顯的。
相關內容
自然語言處理(NLP)是計算機科學,人工智慧,語言學關注計算機和人類(自然)語言之間的相互作用的領域。因此,自然語言處理是與人機互動的領域有關的。在自然語言處理面臨很多挑戰,包括自然語言理解,因此,自然語言處理涉及人機互動的面積。在NLP諸多挑戰涉及自然語言理解,即計算機源於人為或自然語言輸入的意思,和其他涉及到自然語言生成。
現代NLP算法是基於機器學習,特別是統計機器學習。機器學習範式是不同於一般之前的嘗試語言處理。語言處理任務的實現,通常涉及直接用手的大套規則編碼。
許多不同類的機器學習算法已套用於自然語言處理任務。這些算法的輸入是一大組從輸入數據生成的“特徵”。一些最早使用的算法,如決策樹,產生硬的if-then規則類似於手寫的規則,是再普通的系統體系。然而,越來越多的研究集中於統計模型,這使得基於附加實數值的權重,每個輸入要素柔軟,機率的決策。此類模型具有能夠表達許多不同的可能的答案,而不是只有一個相對的確定性,產生更可靠的結果時,這種模型被包括作為較大系統的一個組成部分的優點。
自然語言處理研究逐漸從辭彙語義成分的語義轉移,進一步的,敘事的理解。然而人類水平的自然語言處理,是一個人工智慧完全問題。它是相當於解決中央的人工智慧問題使計算機和人一樣聰明,或強大的AI。自然語言處理的未來一般也因此密切結合人工智慧發展。
相關技術
數據稀疏與平滑技術
大規模數據統計方法與有限的訓練語料之間必然產生數據稀疏問題,導致零機率問題,符合經典的zip'f定律。如IBM, Brown:366M英語語料訓練trigram,在測試語料中,有14.7%的trigram和2.2%的bigram在訓練語料中未出現。
數據稀疏問題定義:“The problem of data sparseness, alsoknown as the zero-frequency problem ariseswhen analyses contain configurations thatnever occurred in the training corpus. Then it isnot possible to estimate probabilities from observedfrequencies, and some other estimation schemethat can generalize (that configurations) from thetraining data has to be used. —— Dagan”。
人們為理論模型實用化而進行了眾多嘗試與努力,誕生了一系列經典的平滑技術,它們的基本思想是“降低已出現n-gram條件機率分布,以使未出現的n-gram條件機率分布非零”,且經數據平滑後一定保證機率和為1,詳細如下:
• Add-one(Laplace) Smoothing
加一平滑法,又稱拉普拉斯定律,其保證每個n-gram在訓練語料中至少出現1次,以bigram為例,公式如圖:
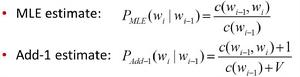 公式
公式 其中,V是所有bigram的個數。
• Good-Turing Smoothing
其基本思想是利用頻率的類別信息對頻率進行平滑。調整出現頻率為c的n-gram頻率為c*:
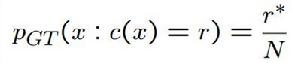 公式
公式 直接的改進策略就是“對出現次數超過某個閾值的gram,不進行平滑,閾值一般取8~10”,其他方法請參見“Simple Good-Turing”。
• InterpolationSmoothing
不管是Add-one,還是Good Turing平滑技術,對於未出現的n-gram都一視同仁,難免存在不合理(事件發生機率存在差別),所以這裡再介紹一種線性插值平滑技術,其基本思想是將高階模型和低階模型作線性組合,利用低元n-gram模型對高元n-gram模型進行線性插值。因為在沒有足夠的數據對高元n-gram模型進行機率估計時,低元n-gram模型通常可以提供有用的信息。公式如下如右圖1:
擴展方式(上下文相關)為如右圖2:
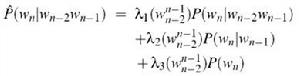 擴展方式
擴展方式 λs可以通過EM算法來估計,具體步驟如下:
• 首先,確定三種數據:Training data、Held-out data和Test data;
• 然後,根據Training data構造初始的語言模型,並確定初始的λs(如均為1);
• 最後,基於EM算法疊代地最佳化λs,使得Held-out data機率(如下式)最大化。
概述
基礎理論
自動機 形式邏輯 統計機器學習漢語語言學 形式語法理論
語言資源
語料庫 詞典
關鍵技術
漢字編碼詞法分析 句法分析 語義分析 文本生成 語音識別
套用系統
文本分類和聚類 信息檢索和過濾 信息抽取問答系統拼音漢字轉換系統 機器翻譯 新信息檢測
爭論
雖然上述新趨勢給自然語言處理領域帶來了成果,但從理論方法的角度看,由於採集、整理、表示和有效套用大量知識的困難,這些系統更依賴於統計學的方法和其他“簡單”的方法或技巧。而這些統計學的方法和其他“簡單”的方法似乎也快達到它們的極限了,因此,就現在而言,在自然語言處理界廣泛爭論的一個問題便是:要取得新的更大的進展,主要有待於理論上的突破呢,還是可由已有的方法的完善和最佳化實現?答案還不清楚。大致上,更多的語言學家傾向於前一種意見,而更多的工程師則傾向於後一種意見。回答或許在“中間”,即應將基於知識和推理的深層方法與基於統計等“淺層”方法結合起來。
處理數據
自然語言處理的基礎是各類自然語言處理數據集,如tc-corpus-train(語料庫訓練集)、面向文本分類研究的中英文新聞分類語料、以IG卡方等特徵詞選擇方法生成的多維度ARFF格式中文VSM模型、萬篇隨機抽取論文中文DBLP資源、用於非監督中文分詞算法的中文分詞詞庫、UCI評價排序數據、帶有初始化說明的情感分析數據集等。
處理工具
OpenNLP
OpenNLP是一個基於Java機器學習工具包,用於處理自然語言文本。支持大多數常用的 NLP 任務,例如:標識化、句子切分、部分詞性標註、名稱抽取、組塊、解析等。
FudanNLP
FudanNLP主要是為中文自然語言處理而開發的工具包,也包含為實現這些任務的機器學習算法和數據集。本工具包及其包含數據集使用LGPL3.0許可證。開發語言為Java。
功能:
1. 文本分類 新聞聚類
2. 中文分詞 詞性標註 實體名識別 關鍵字抽取 依存句法分析 時間短語識別
3. 結構化學習 線上學習 層次分類 聚類 精確推理
語言技術平台(LTP)
語言技術平台(Language Technology Platform,LTP)是哈工大社會計算與信息檢索研究中心歷時十年開發的一整套中文語言處理系統。LTP制定了基於XML的語言處理結果表示,並在此基礎上提供了一整套自底向上的豐富而且高效的中文語言處理模組(包括詞法、句法、語義等6項中文處理核心技術),以及基於動態程式庫(Dynamic Link Library, DLL)的應用程式接口,可視化工具,並且能夠以網路服務(Web Service)的形式進行使用。
自然語言處理技術難點
單詞的邊界界定
在口語中,詞與詞之間通常是連貫的,而界定字詞邊界通常使用的辦法是取用能讓給定的上下文最為通順且在文法上無誤的一種最佳組合。在書寫上,漢語也沒有詞與詞之間的邊界。
詞義的消歧
許多字詞不單只有一個意思,因而我們必須選出使句意最為通順的解釋。
句法的模糊性
自然語言的文法通常是模稜兩可的,針對一個句子通常可能會剖析(Parse)出多棵剖析樹(Parse Tree),而我們必須要仰賴語意及前後文的信息才能在其中選擇一棵最為適合的剖析樹。
有瑕疵的或不規範的輸入
例如語音處理時遇到外國口音或地方口音,或者在文本的處理中處理拼寫,語法或者光學字元識別(OCR)的錯誤。
語言行為與計畫
句子常常並不只是字面上的意思;例如,“你能把鹽遞過來嗎”,一個好的回答應當是把鹽遞過去;在大多數上下文環境中,“能”將是糟糕的回答,雖說回答“不”或者“太遠了我拿不到”也是可以接受的。再者,如果一門課程上一年沒開設,對於提問“這門課程去年有多少學生沒通過?”回答“去年沒開這門課”要比回答“沒人沒通過”好。
