
性質特點
對於一般的Trie樹的數據結構,它的實現簡單但是空間效率極低。例如,如果要支持26個英文字母,每個節點就要保存26個指針,當數據量繼續增大,需要更多的支持記憶體用量,使得整個數據結構占用記憶體太多。
由於節點數組中保存掛起的空指針占用了過多記憶體,我們採用特殊的Trie樹的數據結構——Ternary Search Trie,三叉搜尋樹,它是結合字典樹的高時間效率和二叉搜尋樹的高空間效率的一種數據結構。
三叉搜尋樹與二叉搜尋樹不同,鍵不是直接保存在節點中,而是由節點在樹中的位置決定。一個節點的所有子孫都有相同的前綴(prefix),也就是這個節點對應的字元串,而根節點對應空字元串。一般情況下,不是所有的節點都有對應的值,只有葉子節點和部分內部節點所對應的鍵才有相關的值。
與此同時,三叉搜尋樹使用了一種聰明的手段去解決字典樹的記憶體問題(空的指針數組)。為了避免多餘的指針占用記憶體,每個節點不再用數組來表示,而是表示成“樹中有樹”。節點裡每個非空指針都會在三叉搜尋樹里得到屬於它自己的節點。
插入字元串的順序會影響三叉搜尋樹的結構,為了取得最佳性能,字元串應該以隨機的順序插入到三叉樹搜尋樹中,尤其不應該按字母順序插入,否則對應於單個Trie節點的子樹會退化成鍊表,極大地增加查找成本。單詞的讀入順序對於創建平衡的三叉搜尋樹很重要,但對於二叉搜尋樹就不太重要。通過選擇一個排序後數據單元集合的中間值,並把它作為開始節點。
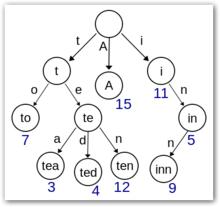 三叉樹
三叉樹三叉搜尋樹的基本性質可以歸納為:
(1)根節點不包含字元,除根節點外的每個節點只包含一個字元。
(2)從根節點到某一個節點,路徑上經過的字元連線起來,為該節點對應的字元串。
(3)每個節點的所有子節點包含的字元串不相同。
(4)節點採用“樹中有樹”的建立方法,避免多餘的記憶體占用。
三叉搜尋樹的實現
對於三叉搜尋樹的實現代碼採用C++和Java語言
C++
//向詞典樹中加入一個單詞的過程
privateTSTNodeaddWord(Stringkey){
TSTNodecurrentNode=root;//從樹的根節點開始查找
intcharIndex=0;//從詞的開頭匹配
while(true){
//比較詞的當前字元與節點的當前字元
//向詞典樹中加入一個單詞的過程
privateTSTNodeaddWord(Stringkey){
TSTNodecurrentNode=root;//從樹的根節點開始查找
intcharIndex=0;//從詞的開頭匹配
while(true){
//比較詞的當前字元與節點的當前字元
intcharComp=key.charAt(charIndex)-
currentNode.splitchar;
if(charComp==0){//相等
charIndex++;
if(charIndex==key.length()){
returncurrentNode;
}
if(currentNode.eqNode==null){
currentNode.eqNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.eqNode;
}elseif(charComp < 0){//小於
if(currentNode.loNode==null){
currentNode.loNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.loNode;
}else{//大於
if(currentNode.hiNode==null){
currentNode.hiNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.hiNode;
}
}
}
intcharComp=key.charAt(charIndex)-
currentNode.splitchar;
if(charComp==0){//相等
charIndex++;
if(charIndex==key.length()){
returncurrentNode;
}
if(currentNode.eqNode==null){
currentNode.eqNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.eqNode;
}elseif(charComp < 0){//小於
if(currentNode.loNode==null){
currentNode.loNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.loNode;
}else{//大於
if(currentNode.hiNode==null){
currentNode.hiNode=newTSTNode(key.charAt
(charIndex));
}
currentNodecurrentNode=currentNode.hiNode;
}
}
}
Java
package sunfa.tree;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class TernarySearchTrie {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
int size = 20;
TernarySearchTrie tree = new TernarySearchTrie();
for (int i = 0; i < size; i++) {
map.put("tkey" + i, "value" + i);
tree.addWord("tkey" + i);
}
System.out.println("search:");
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next().toString();
Entry node = tree.search(key);
System.out.println(node.data.get("value") + ",查找次數:"
+ node.data.get("count"));
}
}
private Entry root = new Entry();
public Entry addWord(String key) {
if (key == null || key.trim().length() == 0)
return null;
Entry node = root;
int i = 0;
while (true) {
int diff = key.charAt(i) - node.splitchar;
char c = key.charAt(i);
if (diff == 0) {// 當前單詞和上一次的相比較,如果相同
i++;
if (i == key.length()) {
node.data = new HashMap<Object, Object>();
node.data.put("value", key);
return node;
}
if (node.equals == null)
node.equals = new Entry(key.charAt(i));// 這裡要注意,要獲取新的單詞填充進去,因為i++了
node = node.equals;
} else if (diff < 0) {// 沒有找到對應的字元,並且下一個左或右節點為NULL,則會一直創建新的節點
if (node.left == null)
node.left = new Entry(c);
node = node.left;
} else {
if (node.right == null)
node.right = new Entry(c);
node = node.right;
}
}
}
public Entry search(String key) {
if (key == null || key.trim().length() == 0)
return null;
Entry node = root;
int count = 0, i = 0;
while (true) {
if (node == null)
return null;
int diff = key.charAt(i) - node.splitchar;
count++;
if (diff == 0) {
i++;
if (i == key.length()) {
node.data.put("count", count);
return node;
}
node = node.equals;
} else if (diff < 0) {
node = node.left;
} else {
node = node.right;
}
}
}
/**
* 三叉Trie樹存在3個節點,左右子節點和二叉樹類似,以前key都是存放在二叉樹的當前節點中,在三叉樹中單詞是存放在中間子樹的。
*/
static class Entry {
Entry left;
Entry right;
Entry equals;// 比對成功就放到中間節點
char splitchar;// 單詞
Map<Object, Object> data;// 擴展數據域,存放 檢索次數,關鍵碼頻率等信息。
public Entry(char splitchar) {
this.splitchar = splitchar;
}
public Entry() {
}
}
}
三叉搜尋樹的套用
 三叉樹
三叉樹三叉搜尋樹由於其優良的搜尋性能,常被使用於搜尋引擎的自動填充完成(Auto-complete)功能,讓用戶可以通過“聯想”的方式更容易查找到所需要的相關模糊信息
百度根據我們輸入的“數據”關鍵字,提示了搜尋量較大的資料庫學習,數據分析等搜尋信息,自動完成這種聯想功能的核心思想即為三叉搜尋樹思想。
對於Web應用程式來說,自動完成(Auto-complete)的繁重處理工作絕大部分要交給伺服器去完成。很多時候,自動完成(Auto-complete)的備選項數目巨大,不適宜一下子全都下載到客戶端。相反,三叉樹搜尋是保存在伺服器上的,客戶端把用戶已經輸入的單詞前綴送到伺服器上作查詢,然後伺服器根據三叉搜尋樹算法獲取相應數據列表,最後把候選的數據列表返回給客戶端。
