![dom[文檔對象模型(Document Object Model)]](/img/8/610/nBnauM3XxEjM1QTN0MDOxIDN0UTMyITNykTO0EDMwAjMwUzLzgzL1czLt92YucmbvRWdo5Cd0FmLwE2LvoDc0RHa.jpg "dom[文檔對象模型(Document Object Model)]")
背景介紹
 DOM
DOMDOM= Document Object Model,文檔對象模型,DOM可以以一種獨立於平台和語言的方式訪問和修改一個文檔的內容和結構。換句話說,這是表示和處理一個HTML或XML文檔的常用方法。有一點很重要,DOM的設計是以對象管理組織(OMG)的規約為基礎的,因此可以用於任何程式語言。最初人們把它認為是一種讓JavaScript在瀏覽器間可移植的方法,不過DOM的套用已經遠遠超出這個範圍。Dom技術使得用戶頁面可以動態地變化,如可以動態地顯示或隱藏一個元素,改變它們的屬性,增加一個元素等,Dom技術使得頁面的互動性大大地增強。
DOM實際上是以面向對象方式描述的文檔模型。DOM定義了表示和修改文檔所需的對象、這些對象的行為和屬性以及這些對象之間的關係。可以把DOM認為是頁面上數據和結構的一個樹形表示,不過頁面當然可能並不是以這種樹的方式具體實現。
通過 JavaScript,您可以重構整個 HTML 文檔。您可以添加、移除、改變或重排頁面上的項目。
要改變頁面的某個東西,JavaScript 就需要獲得對 HTML 文檔中所有元素進行訪問的入口。這個入口,連同對 HTML 元素進行添加、移動、改變或移除的方法和屬性,都是通過文檔對象模型來獲得的(DOM)。
在 1998 年,W3C 發布了第一級的 DOM 規範。這個規範允許訪問和操作 HTML 頁面中的每一個單獨的元素。
所有的瀏覽器都執行了這個標準,因此,DOM 的兼容性問題也難覓蹤影了。
DOM 可被 JavaScript 用來讀取、改變 HTML、XHTML 以及 XML 文檔。
DOM 被分為不同的部分(核心、XML及HTML)和級別(DOM Level 1/2/3):
DOM
DOM 是遵循 W3C(全球資訊網聯盟)的標準。
DOM 定義了訪問 HTML 和 XML 文檔的標準:
"W3C 文檔對象模型 (DOM) 是中立於平台和語言的接口,它允許程式和腳本動態地訪問和更新文檔的內容、結構和樣式。"
W3C DOM 標準被分為 3 個不同的部分:
•核心 DOM - 針對任何結構化文檔的標準模型
•XML DOM - 針對 XML 文檔的標準模型
•HTML DOM - 針對 HTML 文檔的標準模型
XML DOM
XML DOM 是:
•用於 XML 的標準對象模型
•用於 XML 的標準編程接口
•中立於平台和語言
•W3C 標準
XML DOM 定義了所有 XML 元素的 對象和屬性,以及訪問它們的 方法(接口)。
換句話說: XML DOM 是用於獲取、更改、添加或刪除 XML 元素的標準。
HTML DOM
HTML DOM 是:
•HTML 的標準對象模型
•HTML 的標準編程接口
•W3C 標準
HTML DOM 定義了所有 HTML 元素的對象和屬性,以及訪問它們的方法(接口)。
換言之,HTML DOM 是關於如何獲取、修改、添加或刪除 HTML 元素的標準。
DOM的分級
根據W3C DOM規範,DOM是HTML與XML的套用編程接口(API),DOM將整個頁面映射為一個由層次節點組成的檔案。有1級、2級、3級共3個級別。
1級DOM
1級DOM在1998年10月份成為W3C的提議,由DOM核心與DOM HTML兩個模組組成。DOM核心能映射以XML為基礎的文檔結構,允許獲取和操作文檔的任意部分。DOM HTML通過添加HTML專用的對象與函式對DOM核心進行了擴展。
2級DOM
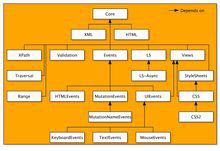 DOM
DOM鑒於1級DOM僅以映射文檔結構為目標,DOM 2級面向更為寬廣。通過對原有DOM的擴展,2級DOM通過對象接口增加了對滑鼠和用戶界面事件(DHTML長期支持滑鼠與用戶界面事件)、範圍、遍歷(重複執行DOM文檔)和層疊樣式表(CSS)的支持。同時也對DOM 1的核心進行了擴展,從而可支持XML命名空間。
2級DOM引進了幾個新DOM模組來處理新的接口類型:
DOM視圖:描述跟蹤一個文檔的各種視圖(使用CSS樣式設計文檔前後)的接口;
DOM事件:描述事件接口;
DOM樣式:描述處理基於CSS樣式的接口;
DOM遍歷與範圍:描述遍歷和操作文檔樹的接口;
3級DOM
3級DOM通過引入統一方式載入和保存文檔和文檔驗證方法對DOM進行進一步擴展,DOM3包含一個名為“DOM載入與保存”的新模組,DOM核心擴展後可支持XML1.0的所有內容,包括XML Infoset、 XPath、和XML Base。
0級DOM
當閱讀與DOM有關的材料時,可能會遇到參考0級DOM的情況。需要注意的是並沒有標準被稱為0級DOM,它僅是DOM歷史上一個參考點(0級DOM被認為是在Internet Explorer 4.0 與Netscape Navigator4.0支持的最早的DHTML)。
節點
根據 DOM,HTML 文檔中的每個成分都是一個節點。
DOM 是這樣規定的:
整個文檔是一個文檔節點
每個 HTML 標籤是一個元素節點
包含在 HTML 元素中的文本是文本節點
每一個 HTML 屬性是一個屬性節點
注釋屬於注釋節點
Node 層次
節點彼此都有等級關係。
HTML 文檔中的所有節點組成了一個文檔樹(或節點樹)。HTML 文檔中的每個元素、屬性、文本等都代表著樹中的一個節點。樹起始於文檔節點,並由此繼續伸出枝條,直到處於這棵樹最低級別的所有文本節點為止。
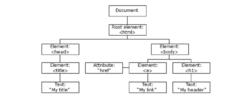
下面這個圖片表示一個文檔樹(節點樹):
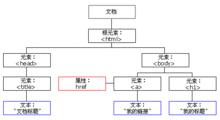 節點樹示意圖
節點樹示意圖文檔樹
請看下面這個HTML文檔:
<html>
<head>
<title>DOM Tutorial</title>
</head>
<body>
<h1>DOM Lesson one</h1>
<p>Hello world!</p>
</body>
</html>
上面所有的節點彼此間都存在 關係。
除文檔節點之外的每個節點都有 父節點。舉例,<head> 和 <body> 的父節點是 <html> 節點,文本節點 "Hello world!" 的父節點是 <p> 節點。
大部分元素節點都有 子節點。比方說,<head> 節點有一個子節點:<title> 節點。<title> 節點也有一個子節點:文本節點 "DOM Tutorial"。
當節點分享同一個父節點時,它們就是 同輩(同級節點)。比方說,<h1> 和 <p>是同輩,因為它們的父節點均是 <body> 節點。
節點也可以擁有 後代,後代指某個節點的所有子節點,或者這些子節點的子節點,以此類推。比方說,所有的文本節點都是 <html>節點的後代,而第一個文本節點是 <head> 節點的後代。
節點也可以擁有 先輩。先輩是某個節點的父節點,或者父節點的父節點,以此類推。比方說,所有的文本節點都可把 <html> 節點作為先輩節點。
訪問節點
你可通過若干種方法來查找您希望操作的元素:
通過使用 getElementById() 和 getElementsByTagName() 方法
通過使用一個元素節點的 parentNode、firstChild 以及 lastChild 屬性
getElementById() 和 getElementsByTagName() 這兩種方法,可查找整個 HTML 文檔中的任何 HTML 元素。
這兩種方法會忽略文檔的結構。假如您希望查找文檔中所有的 <p> 元素,getElementsByTagName() 會把它們全部找到,不管 <p> 元素處於文檔中的哪個層次。同時,getElementById() 方法也會返回正確的元素,不論它被隱藏在文檔結構中的什麼位置。
這兩種方法會向您提供任何你所需要的 HTML 元素,不論它們在文檔中所處的位置!
getElementById() 可通過指定的 ID 來返回元素:
getElementById() 語法
document.getElementById("ID");注釋:getElementById() 無法工作在 XML 中。在 XML 文檔中,您必須通過擁有類型 id 的屬性來進行搜尋,而此類型必須在 XML DTD 中進行聲明。
getElementsByTagName() 方法會使用指定的標籤名返回所有的元素(作為一個節點列表),這些元素是您在使用此方法時所處的元素的後代。
getElementsByTagName() 可被用於任何的 HTML 元素:
getElementsByTagName() 語法
document.getElementsByTagName("標籤名稱");或者:
document.getElementById('ID').getElementsByTagName("標籤名稱");
實例 1
下面這個例子會返回文檔中所有 <p> 元素的一個節點列表:
document.getElementsByTagName("p");
實例 2
下面這個例子會返回所有 <p> 元素的一個節點列表,且這些 <p> 元素必須是 id 為 "maindiv" 的元素的後代:
document.getElementById('maindiv').getElementsByTagName("p");
節點列表
當我們使用節點列表時,通常要把此列表保存在一個變數中,就像這樣:
var x=document.getElementsByTagName("p");現在,變數 x 包含著頁面中所有 <p> 元素的一個列表,並且我們可以通過它們的索引號來訪問這些 <p> 元素。
注釋:索引號從 0 開始。
您可以通過使用 length 屬性來循環遍歷節點列表:
var x=document.getElementsByTagName("p"); for (var i=0;i<x.length;i++) { // do something with each paragraph }您也可以通過索引號來訪問某個具體的元素。
要訪問第三個 <p> 元素,您可以這么寫:
var y=x[2];
parentNode、firstChild以及lastChild
這三個屬性 parentNode、firstChild 以及 lastChild 可遵循文檔的結構,在文檔中進行“短距離的旅行”。
請看下面這個 HTML 片段:
<table>
<tr>
<td>John</td>
<td>Doe</td>
<td>Alaska</td>
</tr>
</table>
在上面的HTML代碼中,第一個 <td> 是 <tr> 元素的首個子元素(firstChild),而最後一個 <td> 是 <tr>元素的最後一個子元素(lastChild)。
此外,<tr> 是每個 <td>元 素的父節點(parentNode)。
對 firstChild 最普遍的用法是訪問某個元素的文本:
var x=[a paragraph]; var text=x.firstChild.nodeValue;parentNode 屬性常被用來改變文檔的結構。假設您希望從文檔中刪除帶有 id 為 "maindiv" 的節點:
var x=document.getElementById("maindiv"); x.parentNode.removeChild(x);首先,您需要找到帶有指定 id 的節點,然後移至其父節點並執行 removeChild() 方法。
優點和缺點
DOM的優勢主要表現在:易用性強,使用DOM時,將把所有的XML文檔信息都存於記憶體中,並且遍歷簡單,支持XPath,增強了易用性。
DOM的缺點主要表現在:效率低,解析速度慢,記憶體占用量過高,對於大檔案來說幾乎不可能使用。另外效率低還表現在大量的消耗時間,因為使用DOM進行解析時,將為文檔的每個element、attribute、processing-instruction和comment都創建一個對象,這樣在DOM機制中所運用的大量對象的創建和銷毀無疑會影響其效率。
